
k8s技術預研12--kubernetes的常見開源網路元件
阿新 • • 發佈:2019-01-19
k8s的網路模型假定了所有Pod都在一個可以直接連通的扁平的網路空間中。這是因為k8s出自Google,而在GCE裡面是提供了網路模型作為基礎設施的,所以k8s就假定這個網路已經存在。而在大傢俬有的平臺設施裡搭建k8s叢集,就不能假定這種網路已經存在了。我們需要自己實現這個網路,將不同節點上的Docker容器之間的互相訪問先打通,然後執行k8s。
目前已經有多個開源元件支援容器網路模型。本節介紹幾個常見的網路元件及其安裝配置方法,包括Flannel、Open vSwitch、直接路由和Calico。1. Flannel
1.1 Flannel通訊原理
Flannel之所以可以搭建k8s依賴的底層網路,是因為它能實現以下兩點。(1)它能協助k8s,給每一個Node上的Docker容器分配互相不衝突的IP地址。(2)它能在這些IP地址之間建立一個覆蓋網路(Overlay Network),通過這個覆蓋網路,將資料包原封不動地傳遞到目標容器內。我們通過下圖來看看Flannel是如何實現這兩點的。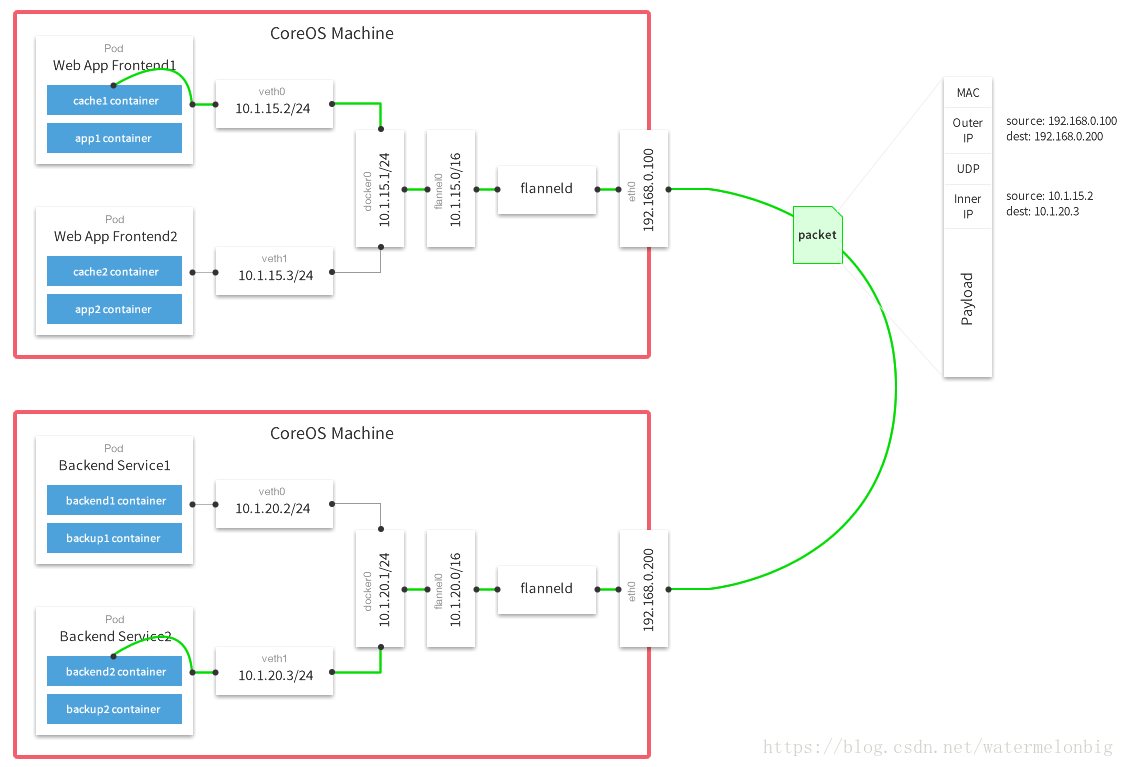
可以看到,Flannel首先建立了一個名為flannel0的網橋,這個網橋的一端連線docker0網橋,另一端連線一個叫作flanneld的服務程序。flanneld程序很重要:
- flanneld首先要連線etcd,利用etcd來管理可分配的IP地址段資源,同時監控etcd中每個Pod的實際地址,並在記憶體中建立了一個Pod節點路由表;
- 然後flanneld程序下連docker0和物理網路,使用記憶體中的Pod節點路由表,將docker0發給它的資料包包裝起來,利用物理網路的連線將資料包投遞到目標flanneld上,從而完成Pod到Pod之間的直接地址通訊。
1.2 Flannel的安裝和配置方法
1)安裝etcd由於Flannel使用etcd作為資料庫,所以需要預先安裝好,這裡不做描述。2)安裝Flannel需要在每臺Node上都安裝Flannel。Flannel軟體的下載地址為:https://github.com/coreos/flannel/releases 。將下載好的flannel-<version>-linux-amd64.tar.gz解壓,把二進位制檔案flanneld和mk-docker-opts.sh複製到/usr/bin中,即可完成對Flannel的安裝。3)配置Flannel此處以使用systemd系統為例對flanneld服務進行配置。編輯服務配置檔案/usr/lib/systemd/system/flanneld.service:[[email protected] sysconfig]# more /usr/lib/systemd/system/flanneld.service[Unit]Description=flanneld overlay address etcd agentAfter=network.targetBefore=docker.service[Service]Type=notifyEnvironmentFile=/etc/sysconfig/flannelExecStart=/usr/bin/flanneld -etcd-endpoints=http://10.0.2.15:2379 $FLANNEL_OPTIONS[Install]RequiredBy=docker.serviceWantedBy=multi-user.target編輯配置檔案/etc/sysconfig/flannel,設定etcd的URL地址:[[email protected] sysconfig]# more flannel# flanneld configuration options# etcd url location. Point this to the server where etcd runsFLANNEL_ETCD="http://10.0.2.15:2379"# etcd config key. This is the configuration key that flannel queries# For address range assignment在啟動flanneld服務之前,需要在etcd中新增一條網路配置記錄,這個配置將用於flanneld分配給每個Docker的虛擬IP地址段。[[email protected] ~]# etcdctl set /coreos.com/network/config '{ "Network": "172.16.0.0/16" }'{ "Network": "172.16.0.0/16" }由於Flannel將覆蓋docker0網橋,所以如果Docker服務已啟動,則需要停止Docker服務。4)啟動Flannel服務systemctl daemon-reloadsystemctl restart flanneld5)重新啟動Docker服務systemctl daemon-reloadsystemctl restart docker6)設定docker0網橋的IP地址mk-docker-opts.sh -isource /run/flannel/subnet.envifconfig docker0 ${FLANNEL_SUBNET}完成後確認網路介面docker0的IP屬於flannel0的子網:[[email protected] system]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 08:00:27:9f:89:14 brd ff:ff:ff:ff:ff:ff inet 10.0.2.4/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3 valid_lft 993sec preferred_lft 993sec inet6 fe80::a00:27ff:fe9f:8914/64 scope link valid_lft forever preferred_lft forever3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:c9:52:3d:15 brd ff:ff:ff:ff:ff:ff inet 172.16.70.1/24 brd 172.16.70.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:c9ff:fe52:3d15/64 scope link valid_lft forever preferred_lft forever6: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500 link/none inet 172.16.70.0/16 scope global flannel0 valid_lft forever preferred_lft forever inet6 fe80::4b31:c92f:8cc9:3a22/64 scope link flags 800 valid_lft forever preferred_lft forever[[email protected] system]#至此,就完成了Flannel覆蓋網路的設定。使用ping命令驗證各Node上docker0之間的相互訪問。例如在Node1(docker0 IP=172.16.70.1)機器上ping Node2的docker0(docker0 IP=172.16.13.1),通過Flannel能夠成功連線到其他物理機的Docker網路:[[email protected] system]# ifconfig flannel0flannel0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1472 inet 172.16.70.0 netmask 255.255.0.0 destination 172.16.70.0 inet6 fe80::524a:4b9c:3391:7514 prefixlen 64 scopeid 0x20<link> unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC) RX packets 5 bytes 420 (420.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8 bytes 564 (564.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0[[email protected] system]# ifconfig docker0docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.16.70.1 netmask 255.255.255.0 broadcast 172.16.70.255 inet6 fe80::42:c9ff:fe52:3d15 prefixlen 64 scopeid 0x20<link> ether 02:42:c9:52:3d:15 txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8 bytes 648 (648.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0[[email protected] system]# ping 172.16.13.1PING 172.16.13.1 (172.16.13.1) 56(84) bytes of data.64 bytes from 172.16.13.1: icmp_seq=1 ttl=62 time=1.63 ms64 bytes from 172.16.13.1: icmp_seq=2 ttl=62 time=1.55 ms^C--- 172.16.13.1 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1002msrtt min/avg/max/mdev = 1.554/1.595/1.637/0.057 ms我們可以在etcd中檢視到Flannel設定的flannel0地址與物理機IP地址的對應規則:2 Open vSwitch
2.1 基本原理
Open vSwitch是一個開源的虛擬交換軟體,有點兒像Linux中的bridge,但是功能要複雜得多。Open vSwitch的網橋可以直接建立多種通訊通道(隧道),例如Open vSwitch with GRE/VxLAN。這些通道的建立可以很容易地通過OVS的配置命令實現。在k8s、Docker場景下,我們主要是建立L3到L3的隧道,例如下面樣子的網路架構。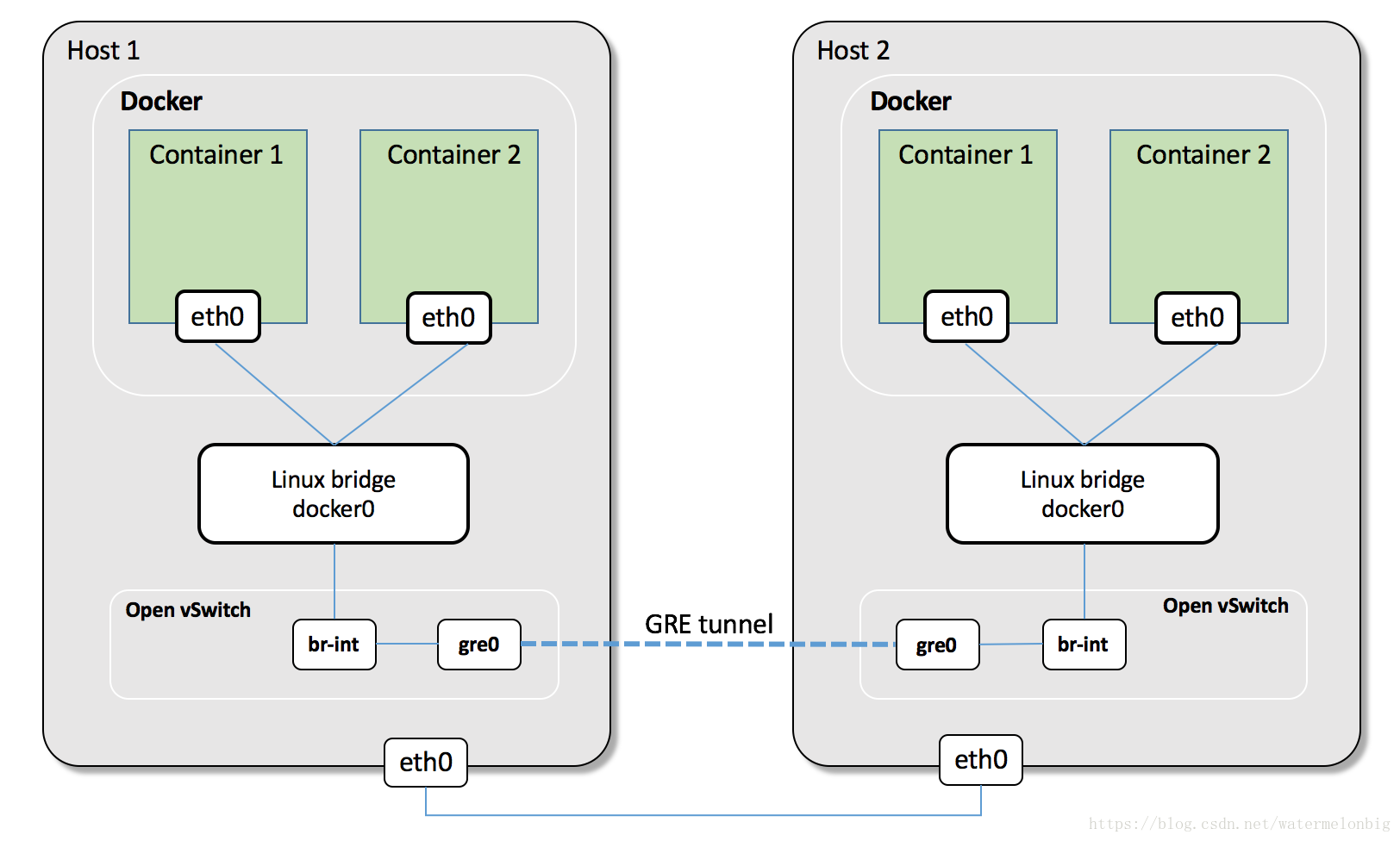
首先,為了避免Docker建立的docker0地址產生衝突,我們需要手動配置和指定下各個Node節點上docker0網橋的地址段分佈。其次,建立Open vSwitch的網橋ovs,然後使用ovs-vsctl命令給ovs網橋增加gre埠,新增gre埠時要將目標連線的NodeIP地址設定為對端的IP地址。對每一個對端IP地址都需要這麼操作(對於大型網路,需要做自動化指令碼來完成)。最後,將ovs的網橋作為網路介面,加入Docker的網橋上。重啟ovs網橋和Docker的網橋,並新增一個Docker的地址段到Docker網橋的路由規則項,就可以將兩個容器的網路連線起來了。
2.2 網路通訊過程
當容器內的應用訪問另一個容器的地址時,資料包會通過容器內的預設路由傳送給docker0網橋。ovs的網橋是作為docker0網橋的埠存在的,安會將資料傳送給ovs網橋。ovs網路已經通過配置建立了和其他ovs網橋的GRE/VxLAN隧道,自然能將資料送達對端的Node,並送往docker0及Pod。通過新增的路由項,使用得Node節點本身的應用的資料也路由到docker0網橋上,和剛才的通訊過程一樣,自然也可以訪問其他Node上的Pod。2.3 OVS with GRE/VxLAN組網方式的特點
OVS的優勢是,作為開源虛擬交換機軟體,它相對成熟和穩定,支援各類網路隧道協議,經過了OpenStack等專案的考驗。另一方面,相對於Flannel不但可以建立OverlayNetwork,實現Pod到Pod的通訊,還和k8s、Docker架構體系緊密結合,感知k8s的Service,動態維護自己的路由表,還通過etcd來協助Docker對整個k8s叢集中的docker0的子網地址進行分配。使用OVS時,很多事情就需要手工完成了。此外,無外是OVS,還是Flannel,通過建立Overlay Network,實現Pod到Pod的通訊,都會引入一些額外的通訊開銷。如果是對網路依賴特別重的應用,則需要評估對業務的影響。2.4 Open vSwitch的安裝與配置
以兩個Node為例,目標網路拓撲如下圖所示。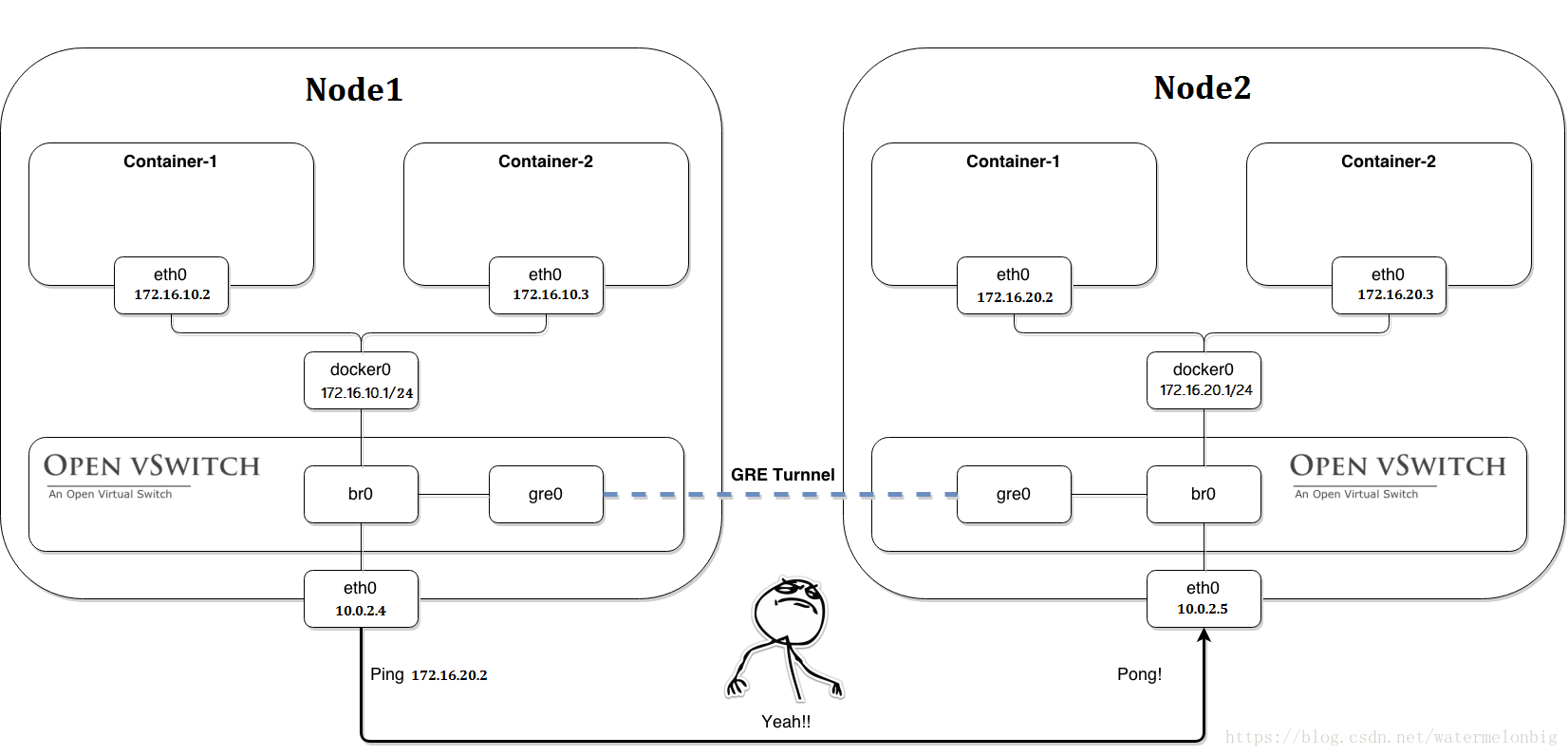
1)在兩個Node上安裝ovs需要確認下關閉了Node節點上的selinux。同時在兩個Node節點上:yum -y install openvswitch檢視Open vSwitch服務狀態,需要有ovsdb-server與ovs-vswitchd兩個程序。[[email protected] system]# systemctl start openvswitch[[email protected] system]# systemctl status openvswitch● openvswitch.service - Open vSwitch Loaded: loaded (/usr/lib/systemd/system/openvswitch.service; disabled; vendor preset: disabled) Active: active (exited) since Sun 2018-06-10 17:06:40 CST; 6s ago Process: 8368 ExecStart=/bin/true (code=exited, status=0/SUCCESS)Main PID: 8368 (code=exited, status=0/SUCCESS)Jun 10 17:06:40 k8s-node2.test.com systemd[1]: Starting Open vSwitch...Jun 10 17:06:40 k8s-node2.test.com systemd[1]: Started Open vSwitch.[[email protected] system]# ps -ef|grep ovsroot 8352 1 0 17:06 ? 00:00:00 ovsdb-server: monitoring pid 8353 (healthy)root 8353 8352 0 17:06 ? 00:00:00 ovsdb-server /etc/openvswitch/conf.db -vconsole:emer -vsyslog:err -vfile:info --remote=punix:/var/run/openvswitch/db.sock --private-key=db:Open_vSwitch,SSL,private_key --certificate=db:Open_vSwitch,SSL,certificate --bootstrap-ca-cert=db:Open_vSwitch,SSL,ca_cert --no-chdir --log-file=/var/log/openvswitch/ovsdb-server.log --pidfile=/var/run/openvswitch/ovsdb-server.pid --detach --monitorroot 8364 1 0 17:06 ? 00:00:00 ovs-vswitchd: monitoring pid 8365 (healthy)root 8365 8364 0 17:06 ? 00:00:00 ovs-vswitchd unix:/var/run/openvswitch/db.sock -vconsole:emer -vsyslog:err -vfile:info --mlockall --no-chdir --log-file=/var/log/openvswitch/ovs-vswitchd.log --pidfile=/var/run/openvswitch/ovs-vswitchd.pid --detach --monitor2)建立網橋和GRE隧道接下來需要在每個Node上建立ovs的網橋br0,然後在網橋上建立一個GRE隧道連線對端的網橋,最後把ovs的網橋br0作為一個埠連線到docker0這個Linux網橋上。這樣一來,兩個節點機器上的docker0網段就能互通了。以Node1節點為例,具體操作步驟如下:(1)建立ovs網橋[[email protected] system]# ovs-vsctl add-br br0(2)建立GRE隧道連線對端,remote_ip為對端的eth0網絡卡地址[[email protected] system]# ovs-vsctl add-port br0 gre1 -- set interface gre1 type=gre option:remote_ip=10.0.2.5(3)新增br0到本地docker0,使得容器流量通過OVS流經tunnel[[email protected] system]# brctl addif docker0 br0(4)啟動br0與docker0網橋[[email protected] system]# ip link set dev br0 up[[email protected] system]# ip link set dev docker0 up(5)新增路由規則由於10.0.2.5與10.0.2.4的docker0網段分別為172.16.20.0/24與172.16.10.0/24,這兩個網段的路由都需要經過本機的docker0網橋路由,其中一個24網段是通過OVS的GRE隧道到達對端的。因此需要在每個Node上新增通過docker0網橋轉發的172.16.0.0/16的路由規則:[[email protected] system]# ip route add 172.16.0.0/16 dev docker0(6)清空Docker自帶的iptables規則及Linux的規則,後者存在拒絕icmp報文通過防火牆的規則[[email protected] system]# iptables -t nat -F[[email protected] system]# iptables -F在Node1節點上完成以上操作後,在Node2節點上進行相同的配置。配置完成後,Node1節點的IP地址、docker0的IP地址及路由等重要資訊顯示如下:[[email protected] system]# ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 08:00:27:9f:89:14 brd ff:ff:ff:ff:ff:ff inet 10.0.2.4/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3 valid_lft 842sec preferred_lft 842sec inet6 fe80::a00:27ff:fe9f:8914/64 scope link valid_lft forever preferred_lft forever3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:c9:52:3d:15 brd ff:ff:ff:ff:ff:ff inet 172.16.10.1/24 brd 172.16.10.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:c9ff:fe52:3d15/64 scope link valid_lft forever preferred_lft forever10: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 5e:a9:02:75:aa:98 brd ff:ff:ff:ff:ff:ff11: br0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UNKNOWN group default qlen 1000 link/ether 82:e3:9a:29:3c:46 brd ff:ff:ff:ff:ff:ff inet6 fe80::a8de:24ff:fef4:f8ec/64 scope link valid_lft forever preferred_lft forever12: [email protected]: <NOARP> mtu 1476 qdisc noop state DOWN group default qlen 1000 link/gre 0.0.0.0 brd 0.0.0.013: [email protected]: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN group default qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff14: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65490 qdisc pfifo_fast master ovs-system state UNKNOWN group default qlen 1000 link/ether 76:53:6f:11:e0:f8 brd ff:ff:ff:ff:ff:ff inet6 fe80::7453:6fff:fe11:e0f8/64 scope link valid_lft forever preferred_lft forever[[email protected] system]#[[email protected] system]# ip routedefault via 10.0.2.1 dev enp0s3 proto dhcp metric 10010.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.4 metric 100172.16.0.0/16 dev docker0 scope link172.16.10.0/24 dev docker0 proto kernel scope link src 172.16.10.13)兩個Node上容器之間的互通測試[[email protected] system]# ping 172.16.20.1PING 172.16.20.1 (172.16.20.1) 56(84) bytes of data.64 bytes from 172.16.20.1: icmp_seq=1 ttl=64 time=2.39 ms64 bytes from 172.16.20.1: icmp_seq=2 ttl=64 time=3.36 ms^C--- 172.16.20.1 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1004msrtt min/avg/max/mdev = 2.398/2.882/3.366/0.484 ms[[email protected] system]#在Node2上抓包觀察:[[email protected] system]# tcpdump -i docker0 -nnntcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes23:43:59.020039 IP 172.16.10.1 > 172.16.20.1: ICMP echo request, id 20831, seq 26, length 6423:43:59.020096 IP 172.16.20.1 > 172.16.10.1: ICMP echo reply, id 20831, seq 26, length 6423:44:00.020899 IP 172.16.10.1 > 172.16.20.1: ICMP echo request, id 20831, seq 27, length 6423:44:00.020939 IP 172.16.20.1 > 172.16.10.1: ICMP echo reply, id 20831, seq 27, length 6423:44:01.021706 IP 172.16.10.1 > 172.16.20.1: ICMP echo request, id 20831, seq 28, length 6423:44:01.021750 IP 172.16.20.1 > 172.16.10.1: ICMP echo reply, id 20831, seq 28, length 64接下來我們從前面曾做過的實驗中找出來一份建立2例項的RC資原始檔來,實際建立兩個容器來測試下兩個Pods間的網路通訊:[[email protected] ~]# more frontend-rc.yamlapiVersion: v1kind: ReplicationControllermetadata: name: frontend labels: name: frontendspec: replicas: 2 selector: name: frontend template: metadata: labels: name: frontend spec: containers: - name: php-redis image: kubeguide/guestbook-php-frontend ports: - containerPort: 80 hostPort: 80 env: - name: GET_HOSTS_FROM value: env[[email protected] ~]#建立並觀察下結果:[[email protected] ~]# kubectl get rcNAME DESIRED CURRENT READY AGEfrontend 2 2 2 33m[[email protected] ~]# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODEfrontend-b6krg 1/1 Running 1 33m 172.16.20.2 10.0.2.5frontend-qk6zc 1/1 Running 0 33m 172.16.10.2 10.0.2.4我們繼續登入進入Node1節點上的容器內部:[[email protected] ~]# kubectl exec -it frontend-qk6zc -c php-redis /bin/bash[email protected]:/var/www/html# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever2: [email protected]: <NOARP> mtu 1476 qdisc noop state DOWN group default qlen 1000 link/gre 0.0.0.0 brd 0.0.0.03: [email protected]: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN group default qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff22: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:10:0a:02 brd ff:ff:ff:ff:ff:ff inet 172.16.10.2/24 brd 172.16.10.255 scope global eth0 valid_lft forever preferred_lft forever[email protected]:/var/www/html#從Node1上執行的Pod中ping一個Nod2上執行的Pod的地址:[email protected]:/var/www/html# ping 172.16.20.2PING 172.16.20.2 (172.16.20.2): 56 data bytes64 bytes from 172.16.20.2: icmp_seq=0 ttl=63 time=2017.587 ms64 bytes from 172.16.20.2: icmp_seq=1 ttl=63 time=1014.193 ms64 bytes from 172.16.20.2: icmp_seq=2 ttl=63 time=13.232 ms64 bytes from 172.16.20.2: icmp_seq=3 ttl=63 time=1.122 ms64 bytes from 172.16.20.2: icmp_seq=4 ttl=63 time=1.379 ms64 bytes from 172.16.20.2: icmp_seq=5 ttl=63 time=1.474 ms64 bytes from 172.16.20.2: icmp_seq=6 ttl=63 time=1.371 ms64 bytes from 172.16.20.2: icmp_seq=7 ttl=63 time=1.583 ms^C--- 172.16.20.2 ping statistics ---8 packets transmitted, 8 packets received, 0% packet lossround-trip min/avg/max/stddev = 1.122/381.493/2017.587/701.350 ms[email protected]:/var/www/html#在Node2節點上抓包看到資料包互動:[[email protected] system]# tcpdump -i docker0 -nnntcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes00:13:18.601908 IP 172.16.10.2 > 172.16.20.2: ICMP echo request, id 38, seq 4, length 6400:13:18.601947 IP 172.16.20.2 > 172.16.10.2: ICMP echo reply, id 38, seq 4, length 6400:13:18.601956 IP 172.16.20.2 > 172.16.10.2: ICMP echo reply, id 38, seq 4, length 6400:13:28.609109 IP 172.16.10.2 > 172.16.20.2: ICMP echo request, id 38, seq 5, length 6400:13:28.609165 IP 172.16.20.2 > 172.16.10.2: ICMP echo reply, id 38, seq 5, length 6400:13:28.609179 IP 172.16.20.2 > 172.16.10.2: ICMP echo reply, id 38, seq 5, length 6400:13:29.612564 IP 172.16.10.2 > 172.16.20.2: ICMP echo request, id 38, seq 6, length 64注:如果以上網路通訊測試沒有完全成功,不妨檢查下Node節點上的firewalld防火牆配置。至此,基於OVS的網路搭建成功,由於GRE是點對點的隧道通訊方式,所以如果有多個Node,則需要建立N*(N-1)條GRE隧道,即所有Node組成一個網狀的網路,以實現全網互通。
3 直接路由
我們在前幾節的實驗中已經測試過通過直接手動寫路由的方式,實現Node之間的網路通訊功能了,配置方法不再討論。該直接路由配置方法的問題是,在叢集節點發生變化時,需要手動去維護每個Node上的路由表資訊,效率很低。為了有效管理這些動態變化的網路路由資訊,動態地讓其他Node都感知到,就需要使用動態路由發現協議來同步這些變化。在實現這些動態路由發現協議的開源軟體中,常用的有Quagga、Zebra等。下面簡單介紹下配置步驟和注意事項。(1)仍然需要手動分配每個Node節點上的Docker bridge的地址段無論是修改預設的docker0使用的地址段,還是另建一個bridge並使用--bridge=XX來指定使用的網橋,都需要確保每個Node上Docker網橋使用的地址段不能重疊。(2)然後在每個Node上執行Quagga既可以選擇在每臺伺服器上安裝Quagga軟體並啟動,也可以使用Quagga容器來執行。在每臺Node上下載Docker映象:# docker pull georce/router在每臺Node上啟動Quagga容器,需要說明的是,Quagga需要以--privileged特權模式執行,並且指定--net=host,表示直接使用物理機的網路。# docker run -itd --name=router --privileged --net=host georce/router啟動成功後,各Node上的Quagga會相互學習來完成到其他機器的docker0路由規則的新增。至此,所有Node上的docker0都可以互聯互通了。注:如果叢集規模在數千臺Node以上,則需要測試和評估路由表的效率問題。4 Calico容器網路和網路策略
4.1 Calico簡介
Calico 是容器網路的又一種解決方案,和其他虛擬網路最大的不同是,它沒有采用 overlay 網路做報文的轉發,提供了純 3 層的網路模型。三層通訊模型表示每個容器都通過 IP 直接通訊,中間通過路由轉發找到對方。在這個過程中,容器所在的節點類似於傳統的路由器,提供了路由查詢的功能。要想路由工作能夠正常,每個虛擬路由器(容器所在的主機節點)必須有某種方法知道整個叢集的路由資訊,calico 採用的是 BGP 路由協議,全稱是 Border Gateway Protocol。除了能用於 容器叢集平臺 kubernetes、共有云平臺 AWS、GCE 等, 也能很容易地整合到 openstack 等 Iaas 平臺。Calico在每個計算節點利用Linux Kernel實現了一個高效的vRouter來負責資料轉發。每個vRouter通過BGP協議把在本節點上執行的容器的路由資訊向整個Calico網路廣播,並自動設定到達其他節點的路由轉發規則。Calico保證所有容器之間的資料流量都是通過IP路由的方式完成互聯互通的。Calico節點組網可以直接利用資料中心的網路結構(L2或者L3),不需要額外的NAT、隧道或者Overlay Network,沒有額外的封包解包,能夠節約CPU運算,提高網路通訊效率。Calico的資料包結構示意圖如下。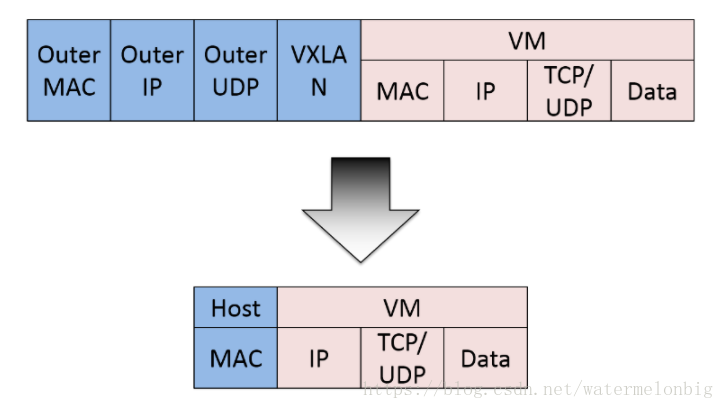
Calico在小規模叢集中可以直接互聯,在大規模叢集中可以通過額外的BGP route reflector來完成。
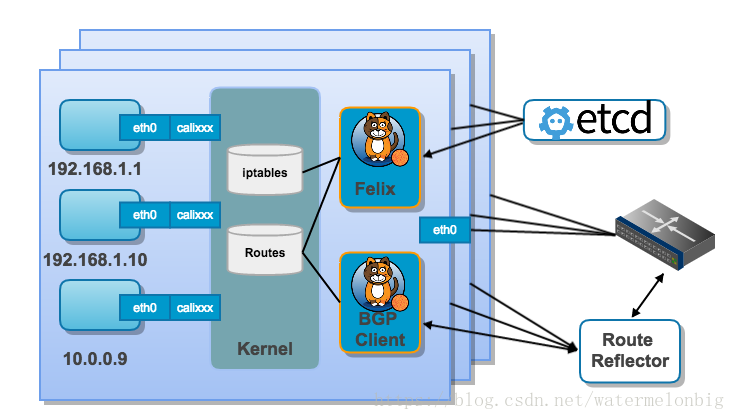
此外,Calico基於iptables還提供了豐富的網路策略,實現了k8s的Network Policy策略,提供容器間網路可達性限制的功能。Calico的主要元件如下:
- Felix:Calico Agent,執行在每臺Node上,負責為容器設定網路源(IP地址、路由規則、iptables規則等),保證主機容器網路互通。
- etcd:Calico使用的儲存後端。
- BGP Client(BIRD):負責把Felix在各Node上設定的路由資訊通過BGP協議廣播到Calico網路。
- BGP Route Reflector(BIRD):通過一個或者多個BGP Route Reflector來完成大規模叢集的分級路由分發。
- calicoctl:Calico命令列管理工具。
4.2 部署Calico服務
在k8s中部署Calico的主要步驟包括兩部分。4.2.1 修改kubernetes服務的啟動引數,並重啟服務- 設定Master上kube-apiserver服務的啟動引數:--allow-privileged=true(因為Calico-node需要以特權模式執行在各Node上)。
- 設定各Node上kubelet服務的啟動引數:--network-plugin=cni(使用CNI網路外掛), --allow-privileged=true
- 建立ConfigMap calico-config,包含Calico所需的配置引數。
- 建立Secret calico-etcd-secrets,用於使用TLS方式連線etcd。
- 在每個Node上執行calico/node容器,部署為DaemonSet。
- 在每個Node上安裝Calico CNI二進位制檔案和網路配置引數(由install-cni容器完成)。
- 部署一個名為calico/kube-policy-controller的Deployment,以對接k8s叢集中為Pod設定的Network Policy。
- etcd_endpoints:Calico使用etcd來儲存網路拓撲和狀態,該引數指定etcd的地址,可以使用k8s Master所用的etcd,也可以另外搭建。
- calico_backend:Calico的後端,預設為bird。
- cni_network_config:符合CNI規範的網路配置。其中type=calico表示kubelet將從/opt/cni/bin目錄下搜尋名為“Calico”的可執行檔案,並呼叫它完成容器網路的設定。ipam中type=calico-ipam表示kubelet將在/opt/cni/bin目錄下搜尋名為"calico-ipam"的可執行檔案,用於完成容器IP地址的分配。
- calico-node:Calico服務程式,用於設定Pod的網路資源,保證Pod的網路與各Node互聯互通,它還需要以hostNetwork模式執行,直接使用宿主機網路。
- install-cni:在各Node上安裝CNI二進位制檔案到/opt/cni/bin目錄下,並安裝相應的網路配置檔案到/etc/cni/net.d目錄下。
- CALICO_IPV4POOL_CIDR:Calico IPAM的IP地址池,Pod的IP地址將從該池中進行分配。
- CALICO_IPV4POOL_IPIP:是否啟用IPIP模式。啟用IPIP模式時,Calico將在Node上建立一個名為"tunl0"的虛擬隧道。
- FELIX_IPV6SUPPORT:是否啟用IPV6。
- FELIX_LOGSEVERITYSCREEN:日誌級別。
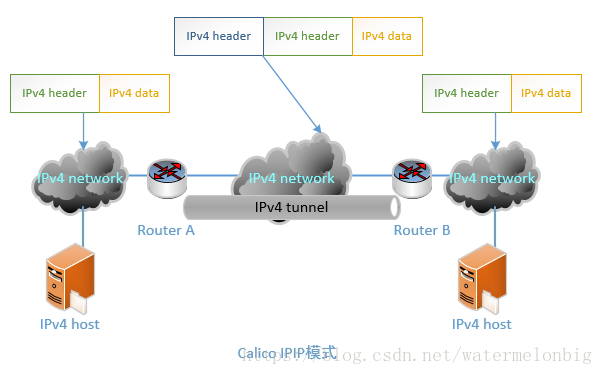
BGP模式則直接使用物理機作為虛擬路由路(vRouter),不再建立額外的tunnel。(4)calico-policy-controller容器用於對接k8s叢集中為Pod設定的Network Policy。# This manifest deploys the Calico policy controller on Kubernetes.apiVersion: extensions/v1beta1kind: Deploymentmetadata: name: calico-policy-controller namespace: kube-system labels: k8s-app: calico-policy annotations: scheduler.alpha.kubernetes.io/critical-pod: '' scheduler.alpha.kubernetes.io/tolerations: | [{"key": "dedicated", "value": "master", "effect": "NoSchedule" }, {"key":"CriticalAddonsOnly", "operator":"Exists"}]spec: # The policy controller can only have a single active instance. replicas: 1 strategy: type: Recreate template: metadata: name: calico-policy-controller namespace: kube-system labels: k8s-app: calico-policy spec: # The policy controller must run in the host network namespace so that # it isn't governed by policy that would prevent it from working. hostNetwork: true containers: - name: calico-policy-controller image: quay.io/calico/kube-policy-controller:v0.5.4 env: # The location of the Calico etcd cluster. - name: ETCD_ENDPOINTS valueFrom: configMapKeyRef: name: calico-config key: etcd_endpoints # Location of the CA certificate for etcd. - name: ETCD_CA_CERT_FILE valueFrom: configMapKeyRef: name: calico-config key: etcd_ca # Location of the client key for etcd. - name: ETCD_KEY_FILE valueFrom: configMapKeyRef: name: calico-config key: etcd_key # Location of the client certificate for etcd. - name: ETCD_CERT_FILE valueFrom: configMapKeyRef: name: calico-config key: etcd_cert # The location of the Kubernetes API. Use the default Kubernetes # service for API access. - name: K8S_API # Since we're running in the host namespace and might not have KubeDNS # access, configure the container's /etc/hosts to resolve # kubernetes.default to the correct service clusterIP. - name: CONFIGURE_ETC_HOSTS value: "true" volumeMounts: # Mount in the etcd TLS secrets. - mountPath: /calico-secrets name: etcd-certs volumes: # Mount in the etcd TLS secrets. - name: etcd-certs secret: secretName: calico-etcd-secrets使用者在k8s叢集中設定了Pod的Network Policy之後,calico-policy-controller就會自動通知各個Node上的calico-node服務,在宿主機上設定相應的iptables規則,完成Pod間網路訪問策略的設定。做好以上配置檔案的準備工作後,就可以開始建立Calico的各資源物件了。[[email protected] ~]# kubectl create -f calico.yamlconfigmap "calico-config" createdsecret "calico-etcd-secrets" createddaemonset "calico-node" createddeployment "calico-policy-controller" created[[email protected] ~]#確保各服務正確執行:
[[email protected] ~]# kubectl get pods --namespace=kube-system -o wideNAME READY STATUS RESTARTS AGE IP NODEcalico-node-59n9j 2/2 Running 1 9h 10.0.2.5 10.0.2.5calico-node-cksq5 2/2 Running 1 9h 10.0.2.4 10.0.2.4calico-policy-controller-54dbfcd7c7-ctxzz 1/1 Running 0 9h 10.0.2.5 10.0.2.5[[email protected] ~]#[[email protected] ~]# kubect