
【原創】基於分散式儲存的開源系統在實時資料庫海量歷史資料儲存專案上的預研
1. 要關注的問題
2. 解決問題的傳統方法
3. 傳統方法的優化以及優化過程中問題
4. Hadoop是什麼?Hadoop中的HDFS、MapReduce與HBase。
5 利用HBase如何解決要關注的問題
1. 要關注的問題
青島高信大閘道器和庚頓實時資料庫都要面對的一個問題就是海量資料的高效儲存、管理與分析。
海量資料的概念?站在實時資料庫歷史資料儲存的角度來說,海量資料的概念不是實時資料庫中包含的數以十萬計、百萬計甚至是千萬計的測點,而是歷史資料儲存需要面對的成百上千G位元組, 甚至是以T為單位的巨型儲存檔案。對於多級部署方式的資料庫,越靠近頂端承載的資料量也就越大 ,在行業應用中因為一系列技術的突破帶來了資料爆炸性的增長,測點數量不斷增多 、測點重新整理頻率不斷加快 、資料線上時間不斷延長,從而使歷史資料檔案的容量輕而易舉的突破百G、千G甚至是幾十幾百T位元組。當單伺服器模式無法承載如此大量的資料檔案,而帶來的一系列問題,如資料檔案建立緩慢、管理低效、備份困難,讀寫耗時。那麼分散式儲存應用解決方案自然地走到我們面前。
2. 解決問題的傳統方法
對於要處理動輒T級位元組大小的檔案,單個閘道器、單個數據庫、單個伺服器往往很難滿足要求,所以採用多個閘道器、多個數據庫、多臺伺服器聯合部署方式,實現所謂的“群集資料庫”。群集資料庫一般由若干個實時/歷史資料庫和一個測點關係庫組成,對外提供統一的訪問介面,同時能夠實現對測點位置、測點資料訪問介面透明,即應用訪問測點時無須關心測點具體儲存在哪個資料庫實體上,群集資料庫是邏輯意義上的資料庫。通過群集資料庫的設計方式可以解決測點不斷擴充套件等問題,但是解決不了巨型資料檔案的問題。同時對於單庫吞吐率的也沒有幫助。資料庫測點數量與歷史資料檔案的大小直接決定了分散式儲存建設規模,特別是資料庫伺服器的配置資料量。
假設單臺伺服器能夠支援的測點容量為X(測點容量與具體資料庫產品有關),同時實時資料庫伺服器採用主備方式執行,某階段建設時估算的所有測點數量為Y(包括了測點容量裕度), 則此階段所需的資料庫伺服器數量為(INT(Y/X)+1)* 2。
例如:一個實時/歷史資料庫的最大測點容量為20萬,某應用的所有測點數量為100萬,則所需伺服器的數量為(INT(100/20)+1)*2=12。
還是同樣的應用場景,一個20萬點資料庫,設定為不壓縮,不算索引檔案和衛星資料,每秒鐘資料全重新整理一次,所產生的資料量為( 8B V + 2B Q +8B T)*200 000 = 3.4MB , 每年產生的資料量102TB,在這樣的場景之下, 單伺服器處理資料的能力迅速下降。可見簡單的 “群集資料庫”不能解決資料檔案不斷膨脹帶來的單伺服器處理能力不足的問題。
在建設的不同階段,硬體配置的變化主要取決於接入測點數量的變化,因此在從速贏向基本成型進階, 或者從基本成型向完善優化階段進階時,除了功能和應用的不斷豐富以外,需要充分考慮由於測點增長、重新整理頻率高、線上時間長引起的資料庫伺服器的增加,以實現平滑升級。
3. 傳統方法的優化以及優化過程中問題
對於簡單的傳統“群集資料庫” ,隨著測點量增加、重新整理頻率增高、線上時間長造成的單伺服器資料檔案負載過重的問題,除了在系統建設初始階段做好規劃外,在系統執行維護階段可以採取類似關係資料庫中分表的方法,把承載巨大資料檔案的單個伺服器中的實時/歷史資料庫的測點表、資料檔案進行拆分。
“群集資料庫”與生具來的一個特點是使用了多個硬體,其中任一硬體發生故障的機率將會變得非常高,避免資料丟失的方法是使用備份,使用磁碟陣列RAID是一種可選的方法。
“群集資料庫”需要用某種方式結合大部分資料共同完成使用者任務。即從一臺伺服器上讀取的資料可能需要從另外N臺伺服器中讀取的資料結合使用。結合多個來源的資料並實現分析,保證其正確性是一個非常大的挑戰。
“群集資料庫”在分散式的計算環境下,協調各程序的執行是一個很大的挑戰,最困難的是合理的處理系統部分失效,程式設計師必須利用底層次的功能模組如套接字和高層次的資料分析演算法控制資料流,顯式的管理自身的檢查點和恢復機制。“群集資料庫”將更多的控制權交給了程式設計師,但也增加了程式設計的難度。
“群集資料庫”每個節點採用雙機備份,硬體資源浪費嚴重。同時也非常容易出現機器與機器之間磁碟利用率不平衡的情況,整個系統的效能受制於資源負載率最高的機器,也不會因為叢集中機器的數量增加,而使叢集的整個效能得到提升 。
4. Hadoop是什麼?Hadoop中的HDFS、MapReduce與HBase。
今天,我們可以從很多渠道獲取到Hadoop的資訊,Hadoop可以做什麼、Hadoop適用什麼場合、Hadoop的技術實現。這些內容在網際網路上有很多的資料可供查詢。通過相關技術資料不難看出,Hadoop是一個分散式計算基礎架構這把“大傘”下的相關子專案集合,這些專案資料Apache軟體基金會,或者為開源軟體專案社群提供支援。這些子專案可以簡化表示為:
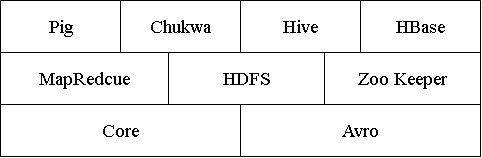
Core
一系列分散式檔案系統和通用I/O的元件和介面
Avro
一種提供高效、跨語言RPC的資料序列系統,持久化資料儲存。
MapReduce
分散式資料處理模式和執行環境,運行於大型商用機叢集。
HDFS
分散式檔案系統,運行於大型商用機叢集。
Hbase
一個分散式的、列儲存資料庫。HBase使用HDFS作為底層儲存,同時支援MapReduce的批量式計算和點查詢(隨機讀取)。
在群集系統中, Hadoop主要解決了兩個問題:
一、硬體故障
在故障發生時,可以使用資料的另一份副本。這就是冗餘的磁碟陣列的工作方式。Hadoop的檔案系統HDFS就是一個例子,雖然它採取的是另一種稍有不同的方法
二、任務的平行計算
不同的分散式系統組合多個來源的資料,在保證正確性方面,MapReduce提供了一個程式設計模型,氣抽象出上磁碟讀寫的問題,將其轉換為計算一個由成對key/value組成的資料集。
簡而言之,Hadoop提供了一個穩定的共享儲存和分析系統。儲存由HDFS實現、分析由MapReduce實現。縱然Hdoop還有其他功能,但這些功能是它的核心所在。在實時資料庫歷史儲存和大閘道器上Hbase是一個可使用、可改造、可擴充套件的基於開源分散式檔案系統的資料庫。
但是,雖然HDFS和MapReduce是用於對大資料集進行批處理的強大工具,但對於讀或者寫單獨的記錄,效率卻很低。Hadoop是一個完成的生態圈,HBase正是用來填補它們之間的鴻溝。
5 利用HBase如何解決要關注的問題
對於實時/歷史資料庫和青島高信要開發的大閘道器,採集的資料要包含越來越長的線上時間的上十萬甚至百萬、千萬的感測器採集資料,這個資料集一直繼續增長,它的大小几乎是無限的。在我們要構建的系統中來讓各種應用進行更新、查詢。為此,我們可以假設資料集非常大,採集資料達到上億條記錄,且採集資料到達的速度很快,不僅如此,構建的應用必須能夠滿足及時查詢到採集的資料。即在收到資料後大約1秒能查詢到結果。
對於資料集的第一個特性使我們排除了使用RDBMS產品,而可能選擇HBase。對於第二個要求排除了直接使用HDFS。MapReduce作業可以用於建立索引以支援對採集資料進行隨機訪問,但HDFS和MpaReduce並不擅長在有更新到達時維護索引。
根據庚頓在實時資料庫開發領域多年的經驗,成熟穩定的Golden V2.0是在基於Windows系統上利用了大量COM技術、檔案記憶體交換技術的單機伺服器模式。Golden V2.0在單機系統上效能優秀,但是要單純的將其中的歷史儲存模組獨立分離出來,或者用Golden實時資料庫構建“分散式群集”資料庫,會有第三節涉及到的問題存在。所以排除了從零開始重新開發或者改造現有資料庫的方法。
對於歷史資料儲存,在HBase中應該如何設計它的模式?(以下涉及的概念和術語,均可在google釋出了一篇相當詳細的論文“Bigtable: A Distributed Storage System for Structured Data ”中有解釋) 。在我們的系統中,至少有兩個表History 、 Section 。
Histroy
這個表存放實時部分傳遞的資料。行的主鍵是測點ID和逆序時間戳構成的組合鍵,這個表有一個列簇data,它包含列value , quality 。這樣同一個測點ID收到的資料就會被分組放到一起,使用逆序時間戳的二進位制儲存,系統把每個測點的最新資料儲存在最前面。行主鍵, HBase不支援條件查詢和Order by等查詢,讀取記錄只能按Row key(及其range)或全表掃描,因此Row key需要根據業務來設計以利用其儲存排序特性提高效能。
|
Row Key |
Timestamp |
data |
|
0000001 |
13171790000001 |
data:value = 1.2f , data,quality= 0 |
|
13171790000002 |
data:value = 1.3f , data,quality= 0 |
|
|
13171790000003 |
data:value = 1.4f , data,quality= 0 |
|
|
0000002 |
13171790000001 |
data:value = 1.3f , data,quality= 0 |
|
13171790000002 |
data:value = 1.1f , data,quality= 0 |
|
|
13171790000003 |
data:value = 1.1f , data,quality= 0 |
Section
這個表存放斷面的歷史資料。行的主鍵是測點時間戳,這個表有一個列簇data,它包含列以測點ID為列名 。這樣同一個時間斷面的測點值就會存放在一起。只要列簇存在,列便可以有客戶端隨時新增。
在為HBase設計模式時,最重要的是考慮資料的訪問方式。所有資料都是通過主鍵進行訪問。所以在設計時,最主要的問題是知道如何查詢這些資料。在對Hbase這樣面向列(簇)的儲存設計模式時,要知道它是可以以極小的開銷管理較寬的稀疏表。
我們應以較多的精力設計行的鍵。一個精心設計的複合鍵可以用來對資料進行聚類,以配合資料的訪問。