
sk-learn學習筆記三
邏輯迴歸處理二元分類
普通的線性迴歸假設響應變數呈正態分佈,也稱為高斯分佈(Gaussian distribution )或鐘形曲線(bell curve)。正態分佈資料是對稱的,且均值,中位數和眾數(mode)是一樣的。
擲一個硬幣獲取正反兩面的概率分佈是伯努力分佈(Bernoulli distribution),又稱兩點分佈或者0-1分佈。表示一個事件發生的概率是p,不發生的概率是1-p,概率在{0,1}之間
在邏輯迴歸裡,響應變數描述了類似於擲一個硬幣結果為正面的概率。如果響應變數等於或超過了指
定的臨界值,預測結果就是正面,否則預測結果就是反面。響應變數是一個像線性迴歸中的解釋變數
構成的函式表示,稱為邏輯函式(logistic function)。
二元分類效果評估方法
二元分類的效果評估方法有很多,常見的包括第一章裡介紹的腫瘤預測使用的準確率(accuracy),
精確率(precision)和召回率(recall)三項指標,以及綜合評價指標(F1 measure), ROC AUC
值(Receiver Operating Characteristic ROC,Area Under Curve,AUC)
在我們的垃圾簡訊分類裡,真陽性是指分類器將一個垃圾簡訊分辨為spam類。真陰性是指分類器將
一個正常簡訊分辨為ham類。假陽性是指分類器將一個正常簡訊分辨為spam類。假陰性是指分類器
將一個垃圾簡訊分辨為ham類。混淆矩陣(Confusion matrix),也稱列聯表分析(Contingency
table)可以用來描述真假與陰陽的關係。矩陣的行表示實際型別,列表示預測型別。
LogisticRegression.score()用來計算模型預測的準確率
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.cross_validation import train_test_split, cross_val_score
df = pd.read_csv('mlslpic/sms.csv')
X_train_raw, X_test_raw, y_train, y_test = train_test_split(df['message']
, df['label'])
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
scores = cross_val_score(classifier, X_train, y_train, cv=5)
print('準確率:',np.mean(scores), scores)
輸出結果如下:
準確率: 0.958373205742 [ 0.96291866 0.95334928 0.95813397 0.96172249 0.95574163]
精確率:
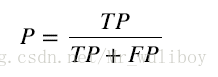
召回率:
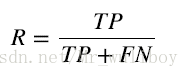
scikit-learn結合真實型別資料,提供了一個函式來計算一組預測值的精確率和召回率。
程式碼如下:
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.cross_validation import train_test_split, cross_val_score
df = pd.read_csv('mlslpic/sms.csv')
X_train_raw, X_test_raw, y_train, y_test = train_test_split(df['message']
, df['label'])
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
precisions = cross_val_score(classifier, X_train, y_train, cv=5, scoring=
'precision')
print('精確率:', np.mean(precisions), precisions)
recalls = cross_val_score(classifier, X_train, y_train, cv=5, scoring='re
call')
print('召回率:', np.mean(recalls), recalls)
輸出結果:
精確率: 0.99217372134 [ 0.9875 0.98571429 1. 1. 0.98765432]
召回率: 0.672121212121 [ 0.71171171 0.62162162 0.66363636 0.63636364 0.72727273]
綜合評價指標(F1 measure)是精確率和召回率的調和均值(harmonic mean),或加權平均值,也稱為F-measure或fF-score。
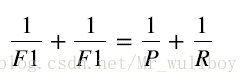
即:
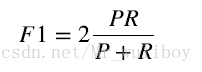
scikit-learn也提供了計算綜合評價指標的函式。
程式碼如下:
f1s = cross_val_score(classifier, X_train, y_train, cv=5, scoring='f1')
print('綜合評價指標:', np.mean(f1s), f1s)
輸出結果如下:
綜合評價指標: 0.8020666384483939 [0.76923077 0.81481481 0.86010363 0.76404494 0.80213904]
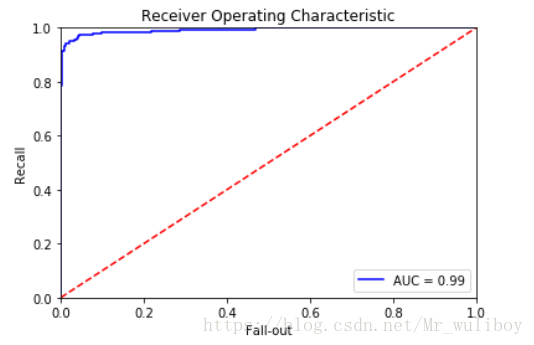
ROC AUC
ROC曲線(Receiver Operating Characteristic,ROC curve)可以用來視覺化分類器的效果。和準確
率不同,ROC曲線對分類比例不平衡的資料集不敏感,ROC曲線顯示的是對超過限定閾值的所有預
測結果的分類器效果。ROC曲線畫的是分類器的召回率與誤警率(fall-out)的曲線。誤警率也稱假
陽性率,是所有陰性樣本中分類器識別為陽性的樣本所佔比例:
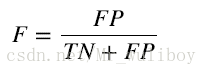
AUC是ROC曲線下方的面積,它把ROC曲線變成一個值,表示分類器隨機預測的效果。scikit-learn
提供了計算ROC和AUC指標的函式
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.cross_validation import train_test_split, cross_val_score
from sklearn.metrics import roc_curve, auc
df = pd.read_csv('D:\dateset\SMSSpamCollection', delimiter='\t', header=None)
X_train_raw, X_test_raw, y_train, y_test = train_test_split(df[1], df[0])
lb = LabelBinarizer()#標籤二值化
y_test = np.array([number[0] for number in lb.fit_transform(y_test)])
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
predictions = classifier.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test, predictions[:, 1])
roc_auc = auc(false_positive_rate, recall)
plt.title('Receiver Operating Characteristic')
plt.plot(false_positive_rate, recall, 'b', label='AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
輸出結果如下:
相關推薦
sk-learn學習筆記三
邏輯迴歸處理二元分類 普通的線性迴歸假設響應變數呈正態分佈,也稱為高斯分佈(Gaussian distribution )或鐘形曲線(bell curve)。正態分佈資料是對稱的,且均值,中位數和眾數(mode)是一樣的。 擲一個硬幣獲取正反兩面的概率分佈是伯努力分佈(B
Linux學習筆記(三):系統執行級與執行級的切換
查看 用戶操作 回車 water hat ntsysv tde 文件表 config 1.Linux系統與其它的操作系統不同,它設有執行級別。該執行級指定操作系統所處的狀態。Linux系統在不論什麽時候都執行於某個執行級上,且在不同的執行級上執行的程序和服務都不同,所要
【Unity 3D】學習筆記三十:遊戲元素——遊戲地形
nbsp 3d遊戲 strong 直觀 分辨率 == 摩擦力 fill 世界 遊戲地形 在遊戲的世界中,必然會有非常多豐富多彩的遊戲元素融合當中。它們種類繁多。作用也不大同樣。一般對於遊戲元素可分為兩種:經經常使用。不經經常使用。經常使用的元素是遊戲中比較重要的元素。一
MYSQL學習筆記三:日期和時間函數
div content minute name top fonts table hmm 指定 MYSQL學習筆記三:日期和時間函數 1. 獲取當前日期的函數和獲取當前時間的函數 /*獲取當前日期的函數和獲取當前時間的函數。將日期以‘YYYY-MM-DD‘或者’YYYYM
Hadoop權威指南學習筆記三
支持 第三方 handle line src factory 模式 多個 重要 HDFS簡單介紹 聲明:本文是本人基於Hadoop權威指南學習的一些個人理解和筆記,僅供學習參考。有什麽不到之處還望指出,一起學習一起進步。 轉載請註明:http://blog.cs
NLTK學習筆記(三):NLTK的一些工具
ast 關註 code 值範圍 通過 自動 ive 叠代器 emma 主要總結一下簡單的工具:條件頻率分布、正則表達式、詞幹提取器和歸並器。 條件分布頻率 《自然語言學習》很多地方都用到了條件分布頻率,nltk提供了兩種常用的接口:FreqDist 和 Condit
Tomcat學習筆記(三)
containe 請求 container connect 技術 http 簡單 img 容器 Tomcat連接器 tomcat連接器是tomcat的一個核心組件,在tomcat4中的實現原理如下 1.實現Connector接口 2.創建Reques
mybatis學習筆記(三)-- 優化數據庫連接配置
bsp pro 新建 數據 配置信息 onf ron XML oca 原來直接把數據庫連接配置信息寫在conf.xml配置中,如下 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configura
Odoo10學習筆記三:模型(結構化的應用數據)、視圖(用戶界面設計)
其他 描述 用戶界面 列表 支持 字段 界面設計 允許 學習 一:模型 1:創建模型 模型屬性:模型類可以使用一些屬性來控制它們的一些行為: _name :創建odoo模型的內部標識符,必含項。 _description :當用戶界面顯示模型時,一個方便用戶的模型記錄標題。
tensorflow學習筆記(三):實現自編碼器
sea start ear var logs cos soft 編碼 red 黃文堅的tensorflow實戰一書中的第四章,講述了tensorflow實現多層感知機。Hiton早年提出過自編碼器的非監督學習算法,書中的代碼給出了一個隱藏層的神經網絡,本人擴展到了多層,改進
CSS學習筆記三:自定義單選框,復選框,開關
sla checked 移動 transform 第一個 16px 位移 block back 一點一點學習CCS,這次學習了如何自定義單選框,復選框以及開關。 一、單選框 1、先寫好body裏面的樣式,先寫幾個框 1 <body> 2 <d
git 學習筆記三 (windows環境)
clas 環境 check pre div nbsp windows name cnblogs 分支管理 查看分支 git branch 創建dev分支 git branch <name> 切換到dev分支 git checkout <name&
遊戲開發學習筆記三
nor scrip 筆記 nsrunloop posit ppr 遊戲開發 tor http sdk%E6%9B%B4%E6%96%B0%E4%B8%8D%E6%88%90%E5%8A%9F%E6%B1%82%E5%A4%A7%E7%A5%9E%E5%B8%AE%E5%BF
學習筆記(三)
type 指向 des 函數 句柄 釋放內存 服務類 pat play OpenSCManager:function OpenSCManager(lpMachineName, lpDatabaseName: PChar;dwDesiredAccess: DWORD): SC
Android學習筆記三:用Intent串聯activity
conda data activity setresult result 意圖 prot 其他 cte 一:Intent Intent可以理解為 意圖。 我們可以通過創建intent實例來定義一個跳轉意圖,意圖包括:要跳轉到哪個頁面、需要傳遞什麽
redis 學習筆記三
緩解 實時 代理 水平擴展 命令連接 事件 都沒有 分數 能力 一、redis 復制 數據庫復制指的是發生在不同數據庫實例之間,單向的信息傳播的行為,通常由被復制方和復制方組成,被復制方和復制方之間建立網絡連接,復制方式通常為被復制方主動將數據發送到復制方,復制方接收到數據
Java學習筆記三---unable to launch
world 學習筆記 .com image 新工程 hello unable sta ava 環境配置好後,在eclipse下編寫HelloWorld程序: ①創建新工程 ②創建.java文件,命名為HelloWorld ③在源文件中添加main方法,代碼如下: p
vue學習筆記(三):vue-cli腳手架搭建
node log ins 版本 返回 ges 技術分享 安裝webpack webp 一:安裝vue-cli腳手架: 1:為了確保你的node版本在4.*以上,輸入 node -v 查看本機node版本,低於4請更新。 2:輸入: npm install -g vue-c
學習筆記三
putty和xshell的遠程連接及密鑰認證使用puTTY和Xshell遠程連接Linux以及密鑰認證使用puTTY遠程連接Linux首先,安裝puTTY,它是一個免費的開源的軟件,且操作和配置非常簡單易用,下載地址:www.chiark.greenend.org.uk下載安裝包putty-0.70-inst
NumPy學習筆記 三 股票價格
... average col color adt 數據分析 enter 圖片 數理統計 NumPy學習筆記 三 股票價格 《NumPy學習筆記》系列將記錄學習NumPy過程中的動手筆記,前期的參考書是《Python數據分析基礎教程 NumPy學習指南》第二版、《數學分析》