
YOLO訓練自定義目標檢測
YOLO是強大的目標檢測開源庫 ,目前支援多個類別的目標檢測,如自行車、人、動物、標識等,檢測速度比較快,V2下檢測速度在普通顯示卡上可以實時對視訊流目標檢測,雖然對小目標效果欠佳,但是大多數應用下還是有實際應用意義。相關詳細介紹可以參考:https://pjreddie.com/darknet/yolo/?utm_source=next.36kr.com,論文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf。儘管yolo實現了100多類目標檢測,但是應用是多樣性的,需要檢測檢測的目標型別成千上萬,因此,下面將要介紹如何使用yolo訓練出自己想要的目標檢測模型。
本文主要參考這篇英文部落格:https://timebutt.github.io/static/how-to-train-yolov2-to-detect-custom-objects/。
我使用的是VS2013,因此下載yolo的Windows版本,先check out原始碼:
git clone https://github.com/AlexeyAB/darknet.git
然後在\darknet\build\darknet目錄中找到darknet.sln開啟,如果是應為cuda版本問題,可能打不開工程,不過沒有關係,在解決方案檢視中找到darknet工程檔案,選擇編解工程檔案,找到裡面的cuda版本,改成自己安裝的版本,關掉解決方案,重新開啟或者選擇reload,就可以看到原始碼檔案了。編譯,順利通過。
準備配置檔案:obj.data,包含以下內容:
classes= 1
train = train.txt
valid = test.txt
names = obj.names
backup = backup/
classes表示類別數量,我只是訓練1類,所以等於1;train表示訓練集,對應的是檔名,檔案中包含了所有用於訓練的圖片檔名;valid表示測試集合,同訓練集一樣,檔案中包含了所有訓練時所用的測試圖片名;names表示類別的名稱,這裡由obj.names指定;backup表示訓練時的中間weights檔案存放目錄,如果沒有對應目錄,需要建立一個目錄,否則開啟訓練時保持weights檔案會報錯。obj.names中的每一行表示一個類別,第一行的類別序號為0,以此下去至classes-1。
train.txt部分截圖:

obj.names 部分截圖:

這裡只有NFPA一類。
接下標記資料,生成train.txt和test.txt檔案:
這裡我使用BBBox Label Tool標記圖片,下載地址:https://github.com/puzzledqs/BBox-Label-Tool,使用python編寫。如果沒有配置python環境,需要配置python環境,這裡不累述。OK,使用命令列開啟標註介面:

在dir中輸入001,可以看到如下介面:

左邊一列是例子,可以不用管,需要標註的圖片在中間顯示,標記的結果在Bounding boxes中顯示,如下:

可以選擇某一個標記結果然後Delete,也可以clear掉當前圖片所有結果。點選下一個的時候或者上一個的時候,自動儲存。標記結果,例如:
2
51 54 213 214
56 234 165 325
第一行表示標記的框的數量2,第二行開始表示標記的矩形框,分別表示左上角x座標、y座標,右下角x座標、有座標,這些都是絕對座標值,沒有歸一化。
標註是個需要耐心的過程,如果需要檢測結果有個準確一點的位置,那麼標註樣本時就需要標註的緊湊些,儘量剛好包含目標。注意,這個工具同個只能標註同一類,標註不同的類別時,需要使用不同的目錄。
classes = ["NFPA"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
"""-------------------------------------------------------------------"""
""" Configure Paths"""
mypath = "labels/001/"
outpath = "labels/002/"
cls = "NFPA"陣列classes = [“NFPA”]填入所有的類,cls = “NFPA”指定當前需要轉換的類別。mypath = “labels/001/” 為原始目錄,outpath = “labels/002/”為轉換之後的輸出目錄。我認為這裡需要增加邊界檢查,所以增加紅框中的幾行:

OK,轉換之後,需要生成train.txt檔案和test.txt檔案。將標註圖片和convert之後生成的檔案歸在path_data = ‘data/obj/’目錄下,使用如下python指令碼生成train.txt和test.txt:
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
# Directory where the data will reside, relative to 'darknet.exe'
path_data = 'data/obj/'
# Percentage of images to be used for the test set
percentage_test = 10;
# Create and/or truncate train.txt and test.txt
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write(path_data + title + '.jpg' + "\n")
else:
file_train.write(path_data + title + '.jpg' + "\n")
counter = counter + 1OK,資料準備完成,修改cfg/yolo-obj.cfg檔案:
第3行:batch=64,表示每個訓練步驟使用64張圖片;
第4行: 根據視訊記憶體大小可以設定subdivisions=8,等於16;
第244行: classes=1,只有一類;
第237行: filters=(classes + 5)*5;
使用如下命令開啟訓練:
例如:
darknet.exe detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23
darknet19_448.conv.23可以在這裡下載:https://pjreddie.com/media/files/darknet19_448.conv.23
正常介面像這樣:
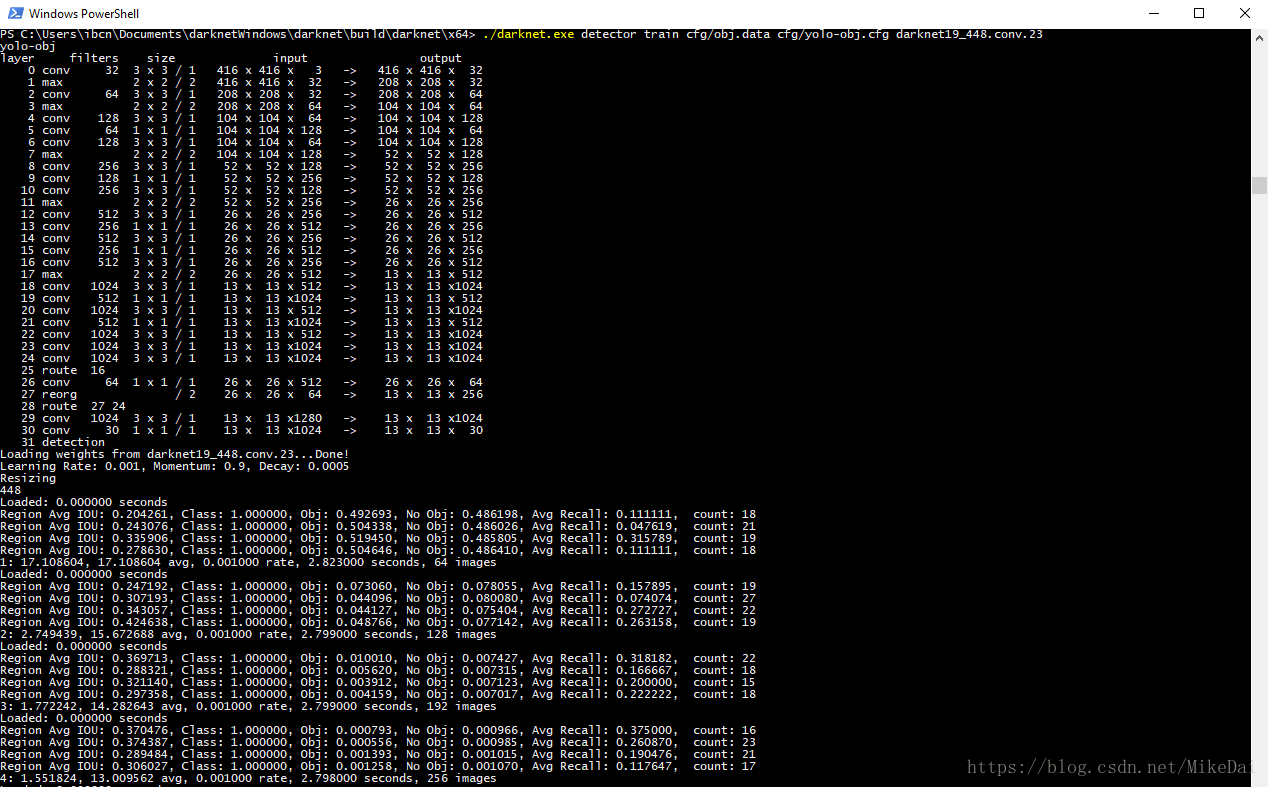
經過幾個小時或幾天的訓練,最後會得到yolo-obj_final.weights,OK,可以用來檢測目標了。
darknet.exe detector test cfg/obj.data cfg/yolo-obj.cfg yolo-obj_final.weights
相關推薦
YOLO訓練自定義目標檢測
YOLO是強大的目標檢測開源庫 ,目前支援多個類別的目標檢測,如自行車、人、動物、標識等,檢測速度比較快,V2下檢測速度在普通顯示卡上可以實時對視訊流目標檢測,雖然對小目標效果欠佳,但是大多數應用下還是有實際應用意義。相關詳細介紹可以參考:https://pjr
【AI實戰】動手訓練自己的目標檢測模型(YOLO篇)
在前面的文章中,已經介紹了基於SSD使用自己的資料訓練目標檢測模型(見文章:手把手教你訓練自己的目標檢測模型),本文將基於另一個目標檢測模型YOLO,介紹如何使用自己的資料進行訓練。 YOLO(You only look once)是目前流行的目標檢測模型之一,目前最新已經發
在darknet上訓練yolo模型---單類目標檢測
簡介:在darknet官網上,作者給出的訓練方法是在開源資料集上進行訓練,例如pascal的20類物體,coco的80類物體。如果我們想在自己的資料集上進行訓練,可能就沒有那麼多類物體。這裡我們使用pascal資料集上的一類目標,進行訓練。本篇部落格是對使用方法的一個總結,本
YOLO V3 一步步訓練自己的目標檢測
YOLO 的 Darknet 框架想必大家應該很熟悉,最近出了最新的 V3 版本,也看到網上有很多的“手把手訓練自己的資料”的部落格,感謝前輩們,自己也從中收益良多。但還是覺得有些粗糙,不夠詳細,尤其是像我們這樣的菜鳥,自己訓練自己的資料時候遇見了不少的坑,特整理分享出來。本
應用OpenCV檢測自定義目標
最近做了一個目標檢測的應用,通過大量的待檢測目標的樣本進行訓練,得到分類器;然後輸入測試視訊,看分類器的檢測結果。主要應用了OpenCV自帶的工具:1.opencv\build\x86\vc10\bin下的opencv_createsamples.exe2.opencv\bu
tensorflow利用預訓練模型進行目標檢測(一):預訓練模型的使用
err sync numpy sna sta porting trac git int32 一、運行樣例 官網鏈接:https://github.com/tensorflow/models/blob/master/research/object_detection/obje
tensorflow利用預訓練模型進行目標檢測
一、安裝 首先系統中已經安裝了兩個版本的tensorflow,一個是通過keras安裝的, 一個是按照官網教程https://www.tensorflow.org/install/install_linux#InstallingNativePip使用Virtualenv 進行安裝的,第二個在根目錄下,做標記
caffe-ssd使用預訓練模型做目標檢測
首先參考https://www.jianshu.com/p/4eaedaeafcb4 這是一個傻瓜似的目標檢測樣例,目前還不清楚圖片怎麼轉換,怎麼驗證,後續繼續跟進 模型測試(1)圖片資料集上測試 python examples/ssd/score_ssd_pascal.py 輸出為
10分鐘學會使用YOLO及Opencv實現目標檢測(下)|附原始碼
將YOLO應用於視訊流物件檢測 首先開啟 yolo_video.py檔案並插入以下程式碼: # import the necessary packages import numpy as np import argparse import imutils import time impo
【AI實戰】手把手教你訓練自己的目標檢測模型(SSD篇)
目標檢測是AI的一項重要應用,通過目標檢測模型能在影象中把人、動物、汽車、飛機等目標物體檢測出來,甚至還能將物體的輪廓描繪出來,就像下面這張圖,是不是很酷炫呢,嘿嘿 在動手訓練自己的目標檢測模型之前,建議先了解一下目標檢測模型的原理(見文章:大話目標檢測經典模型RCNN、Fast RCN
tensorflow利用預訓練模型進行目標檢測(二):將檢測結果存入mysql資料庫
mysql版本:5.7 ; 資料庫:rdshare;表captain_america3_sd用來記錄某幀是否被檢測。表captain_america3_d用來記錄檢測到的資料。 python模組,包部分內容參考http://www.runoob.com/python/python-modules.html&
tensorflow利用預訓練模型進行目標檢測(四):檢測中的精度問題以及evaluation
一、tensorflow提供的evaluation Inference and evaluation on the Open Images dataset:https://github.com/tensorflow/models/blob/master/research/object_detection/g
深度學習(三)——tiny YOLO演算法實現實時目標檢測(tensorflow實現)
一、背景介紹 YOLO演算法全稱You Only Look Once,是Joseph Redmon等人於15年3月發表的一篇文章。本實驗目標為實現YOLO演算法,借鑑了一部分材料,最終實現了輕量級的簡化版YOLO——tiny YOLO,其優勢在於實現簡單,目標檢測迅速。 [1]文章連結:ht
自定義記憶體檢測原理及方案
在專案開發中,或多或少都會遇到一些記憶體洩露的問題,今天就來總結下檢測記憶體洩露的原理及其方法 1 將使用的系統的動態申請/釋放記憶體的函式重新過載實現一遍,如new、delete、malloc、fre
利用YOLO實現自己的目標檢測
因為很多是我按照記憶來寫的,可能會有錯誤,大家一定按照給的連結為準,參考這些即可。。。。。最近,在師哥的引導下,接觸了一下YOLO演算法,是近年來一個比較好的目標檢測演算法,而且它有自己的開源深度學習框架—darknet,使用起來比較簡單,對於我一個新手來說,挺直白的這個,可
使用tensorflow object detection API 訓練自己的目標檢測模型 (一)labelImg的安裝配置過程
第一步:準備自己的資料集。比如我要檢測車牌。首先用到的是labelImg軟體:先簡要介紹一下labelimg安裝的步驟。接下來需要安裝一些python的包:我的環境是win10anacondapythonn36需要安裝的庫有:lxml, pyqt5,一般anaconda會有l
使用tensorflow object detection API 訓練自己的目標檢測模型 (二)
在上一篇部落格"使用tensorflow object detection API 訓練自己的目標檢測模型 (一)"中介紹瞭如何使用LabelImg標記資料集,生成.xml檔案,經過個人的手工標註,形成了一個大概有兩千張圖片的資料集。 但是這仍然不滿足t
Adaboost訓練及在目標檢測中的應用
Adaboost訓練及在目標檢測中的應用 1. Adaboost原理 Adaboost(AdaptiveBoosting)是一種迭代演算法,通過對訓練集不斷訓練弱分類器,然後把這些弱分類器集合起來,構成強分類器。adaboost演算法訓練的過程中,初始化所有訓練
YOLO——基於迴歸的目標檢測演算法
YOLO: You Only Look Once:Unified, Real-Time Object Detection 這篇論文的內容並不多,核心思想也比較簡單,下面相當於是對論文的翻譯! YOLO是一個可以一次性預測多個Box位置和類別的卷積神經網
pvanet 訓練自定義資料
原始碼 編譯方法 到lib目錄下執行 make caffe-fast-rcnn目錄下執行 cp Makefile.config.example Makefile.config #編輯Makefile.config內容,啟動WITH_PY