
機器學習調參-模型選擇
本文主要介紹機器學習模型中超級引數(hyperparameter)的調優問題(下文簡稱為調參問題),主要的方法有手動調優、網格搜尋、隨機搜尋以及基於貝葉斯的引數調優方法。因為模型通常由它的超級引數確定,所以從更高的角度看調參問題就轉化為模型選擇問題。
手動調優
需要較多專業背景知識。
網格搜尋
先固定一個超參,然後對其他各個超參依次進行窮舉搜尋,超參集合為
隨機搜尋
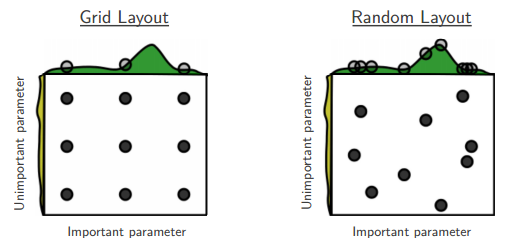
在N維引數空間按某種分佈(如正態分佈)隨機取值,因為引數空間的各個維度的重要性是不等的,隨機搜尋方法可以在不重要的維度上取巧。如下圖所示,按網格搜尋的方式進行搜尋時,由於在非重要維度上取值無效,因此相當於只取了3個有效點。隨機取值相同的引數空間,則可能達到9個有效搜尋點。
貝葉斯方法
從模型選擇的角度來,通過計算在已知資料的情況下,哪種模型的後驗概率大即選擇哪種模型,公式如下,這種方法偏向於選擇簡單的模型,詳見MLAPP
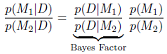
通用的分析方法
如果訓練誤差和驗證誤差都停滯在一個很大的值上,那麼可能的原因和可以嘗試的解決方案:
- 欠擬合,採取增加模型容量的方法,如將weight decay 設為0
模型有bug,將訓練資料集減小,再次訓練看訓練誤差是否能減小
不能很好解釋的問題
對於非凸優化問題模型,當學習率較小時,隨著迭代次數增加,損失函式停滯在較大的值上。
參考
1.Bengio etc.2015,deep learning
貝葉斯模型選擇
1.Robert C P. Machine Learning, a Probabilistic Perspective[J]. Chance, 2014.
相關推薦
機器學習調參-模型選擇
本文主要介紹機器學習模型中超級引數(hyperparameter)的調優問題(下文簡稱為調參問題),主要的方法有手動調優、網格搜尋、隨機搜尋以及基於貝葉斯的引數調優方法。因為模型通常由它的超級引數確定,所以從更高的角度看調參問題就轉化為模型選擇問題。 手動調優
偏差(Bias)和方差(Variance)——機器學習中的模型選擇
模型效能的度量 在監督學習中,已知樣本 $(x_1, y_1),(x_2, y_2),...,(x_n, y_n)$,要求擬合出一個模型(函式)$\hat{f}$,其預測值$\hat{f}(x)$與樣本實際值$y$的誤差最小。 考慮到樣本資料其實是取樣,$y$並不是
強大而精緻的機器學習調參方法:貝葉斯優化
一、簡介 貝葉斯優化用於機器學習調參由J. Snoek(2012)提出,主要思想是,給定優化的目標函式(廣義的函式,只需指定輸入和輸出即可,無需知道內部結構以及數學性質),通過不斷地新增樣本點來更新目標函式的後驗分佈(高斯過程,直到後驗分佈基本貼合於真實分佈。簡單的說,就是考慮了上一次引數的資訊**,從而更好
機器學習模型選擇:調參引數選擇
調參經驗好的實驗環境是成功的一半由於深度學習實驗超參眾多,程式碼風格良好的實驗環境,可以讓你的人工或者自動調參更加省力,有以下幾點可能需要注意:將各個引數的設定部分集中在一起。如果引數的設定分佈在程式碼的各個地方,那麼修改的過程想必會非常痛苦。可以輸出模型的損失函式值以及訓練
【機器學習123】模型評估與選擇 (上)
第2章 模型評估與選擇 2.1 經驗誤差與過擬合 先引出幾個基本概念: 誤差(error):學習器的實際預測輸出與樣本的真實輸出之間的差異。 訓練誤差(training error):學習器在訓練集上的誤差,也稱“經驗誤差”。 測試誤差(testing error):學習器在測試集上的
學習理論、模型選擇、特徵選擇——斯坦福CS229機器學習個人總結(四)
這一份總結裡的主要內容不是演算法,是關於如何對偏差和方差進行權衡、如何選擇模型、如何選擇特徵的內容,通過這些可以在實際中對問題進行更好地選擇與修改模型。 1、學習理論(Learning theory) 1.1、偏差/方差(Bias/variance)
深度 | 機器學習中的模型評價、模型選擇及演算法選擇
作者:Sebastian Raschka翻譯:reason_W編輯:周翔簡介正確使用模型評估、模
機器學習筆記(二)模型評估與選擇
2.模型評估與選擇 2.1經驗誤差和過擬合 不同學習演算法及其不同引數產生的不同模型,涉及到模型選擇的問題,關係到兩個指標性,就是經驗誤差和過擬合。 1)經驗誤差 錯誤率(errorrate):分類錯誤的樣本數佔樣本總數的比例。如果在m個樣本中有a個樣本分類錯誤,則錯誤率E
機器學習筆記之模型評估與選擇
2.1經驗誤差與過擬合錯誤率(error rate):分類錯誤的樣本數佔樣本總數的比例精度(accuracy):1-錯誤率誤差(error):實際預測輸出與樣本的真實輸出之間的差異訓練誤差/經驗誤差:在訓練集上的誤差測試誤差/泛化誤差:在新樣本的誤差過擬合:學習時選擇的模型包
學習理論之模型選擇——Andrew Ng機器學習筆記(八)
內容提要 這篇部落格主要的內容有: 1. 模型選擇 2. 貝葉斯統計和規則化(Bayesian statistics and regularization) 最為核心的就是模型的選擇,雖然沒有那麼多複雜的公式,但是,他提供了更加巨集觀的指導,而且很多時候
機器學習之特征選擇方法
transform 數量 filter 想要 一起 進行 AD IE 維度 特征選擇是一個重要的數據預處理過程,在現實機器學習任務中,獲得數據之後通常先進行特征選擇,此後在訓練學習器,如下圖所示: 進行特征選擇有兩個很重要的原因: 避免維數災難:能剔除不相關(irrel
第四十八篇 入門機器學習——超參數問題
顯示 eight nbsp 根據 情況下 ima 測試 job 個數 No.1. kNN算法中需要傳入一個參數k,這個參數k的作用之前提到過,它就是指距離待預測數據最近的前k個數據,這個參數k的具體大小應該如何選擇?超參數問題就是描述的這類問題。 No.2. 所
機器學習超參數優化庫
並行 分布 可靠的 ima 深度學習 可能 計算平臺 過程 sklearn Skopt https://scikit-optimize.github.io/是一個超參數優化庫,包括隨機搜索、貝葉斯搜索、決策森林和梯度提升樹。這個庫包含一些理論成熟且可靠的優化方法,但是這些
先驗概率、後驗概率、似然函數與機器學習中概率模型(如邏輯回歸)的關系理解
集中 並且 結果 概率論 但我 evidence logs 硬幣 之前 看了好多書籍和博客,講先驗後驗、貝葉斯公式、兩大學派、概率模型、或是邏輯回歸,講的一個比一個清楚 ,但是聯系起來卻理解不能 基本概念如下 先驗概率:一個事件發生的概率 \[P(y)\] 後驗概
【機器學習】機器學習分類器模型評價指標 機器學習分類器模型評價指標
機器學習分類器模型評價指標 分類器評價指標主要有: 1,Accuracy 2,Precision 3,Recall 4,F1 score 5,ROC 曲線
對於機器學習,到底該選擇哪種程式語言?
開發者到底應該學習哪種程式語言才能獲得機器學習或資料科學這類工作呢?這是一個非常重要的問題。我們在許多論壇上都討論過這個問題。今天,我將給出我自己的答案並解釋其中原因,但我們首先看一些資料。畢竟,這是機器學習者和資料科學家應該做的事情:看資料,而不是看觀點。 讓我們看一些資料。
先驗概率、後驗概率、似然函式與機器學習中概率模型(如邏輯迴歸)的關係理解
看了好多書籍和部落格,講先驗後驗、貝葉斯公式、兩大學派、概率模型、或是邏輯迴歸,講的一個比一個清楚 ,但是聯絡起來卻理解不能 基本概念如下 先驗概率:一個事件發生的概率 \[P(y)\] 後驗概率:一個事件在另一個事件發生條件下的條件概率 \[P(y|x
機器學習之---生成模型和判別模型
監督學習方法可分為兩大類,即生成方法與判別方法,它們所學到的模型稱為生成模型與判別模型。 判別模型:判別模型是學得一個分類面(即學得一個模型),該分類面可用來區分不同的資料分別屬於哪一類; 生成模型:生成模型是學得各個類別各自的特徵(即可看成學得多個模型),可用這些
機器學習之判別式模型和生成式模型
https://www.cnblogs.com/nolonely/p/6435213.html 判別式模型(Discriminative Model)是直接對條件概率p(y|x;θ)建模。常見的判別式模型有線性迴歸模型、線性判別分析、支援向量機SVM、神經網路、boosting
機器學習之主題模型(七)
摘要: 主題模型是對文字隱含主題進行建模的方法。它克服了傳統資訊檢索中文件相似度計算方法的缺點,並且能夠在海量網際網路資料中自動尋找出文字間的語義主題。主題模型在自然語言和基於文字的搜尋上都起到非常大的作用。 引言: 兩篇文件是否相關往往不只決定於字面上的詞語重複,還取決於文字背後的語義關聯。對