
MySQL的高級部分
(1)存儲引擎的介紹
介紹:當客戶端發送一條SQL語句給服務器時,服務器端通過緩存、語法檢查、校驗通過之後,然後會通過調用底層的一些軟件組織,去從數據庫中查詢數據,然後將查詢到的結果集返回給客戶端,而這些底層的軟件組織就是存儲引擎。
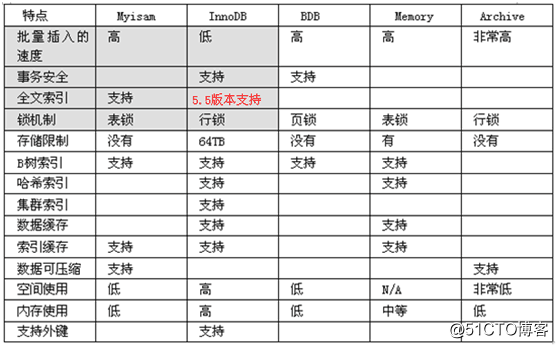
MySQL的存儲引擎:
- MySQL的核心就是存儲引擎,MySQL可以設置多種不同的存儲引擎,不同的存儲引擎在索引、存儲、以及鎖的策略上是不同的。
- Mysql5.5之前,使用的是myisam存儲引擎,支持全文搜索,不支持事務。
(2)MySQL事務的介紹
介紹:事務是一個操作序列,這些操作要麽都做,要麽都不做,是一個不能分割的工作單位。在兩條或兩條以上的SQL語句才能完成的業務時,才需要用事務,因為事務時同步原則,效率比較低。
事務的ACID特性:
- 原子性:放在同一事務的一組操作時不可分割的
- 一致性:在事務的執行前後,整體的狀態是不變的
- 隔離性:事務之間是獨立存在的,兩個不同事務之間互不影響
#例:一個事務操作
BEGIN;
update t_account set money=money+100 where id =1;
update t_account set money=money-100 where id =2;
COMMIT;
#一個回滾操作
BEGIN;
update t_account set money=money+100 where id =1;
update t_account set money=money-100 where id =2;
COMMIT;註意:MySQL數據庫,dml操作采用的是自動提交
#查看自動提交
show variables like ‘autocommit‘;
#修改自動提交
set autocommit=0;(3)MySQL事務並發時產生的問題
臟讀:在一個事務的執行範圍內,讀到了另一事務未提交的數據。
解決:讀已提交,一個數據庫只能讀到另一個事務提交後的數據。(Oracle默認的事務隔離級別)
不可重復讀:一個事務,在只讀範圍內,被另一事務修改並提交事務,導致多次讀取的數據不一致的問題。
解決:可重復讀(MySQL默認的事務隔離級別)
虛讀:一個事務的只讀範圍內,被另一個事務刪除或者添加數據,導致多次讀取的數據不一致的問題。
解決:串行化:解決所有問題,但是速度十分緩慢,不能使用並發事務。
註意:查看事務的隔離級別:select @@tx_isolation;
2. MySQL的存儲程序
(1)MySQL的存儲程序的介紹
描述:運行與服務器端的程序。
優點:簡化開發,執行效率比較高(在服務器端以通過校驗,可直接使用)
缺點:服務器端保存這些存儲程序需要占用磁盤空間;數據遷移時,需要將這些存儲程序進行遷移;調試和編寫程序在服務器端都不方便
存儲程序的分類:存儲過程、存儲函數、觸發器
註意:存儲程序不能使用事務
(2)存儲過程
介紹:存儲過程是在服務器端的一段可執行的代碼塊。
例:
#修改結束符標誌
delimiter //
#創建存儲過程
create procedure pro_book()
begin
#sql
select * from book;
select * from book where bid=3;
end //
#運行
call pro_book() #參數的傳入
delimiter //
create procedure pro_book02(num int)
begin
select * from book where bid=num;
end ; //
--調用
call pro_book02(3)#傳出參數
delimiter //
create procedure pro_book03(num int,out v_name varchar(10))
begin
select bname into v_name from book where bid=num;
end ; //
--調用,這裏的@v_name是一個用戶變量
call pro_book03(1,@v_name);
select @v_name;#傳入傳出參數
delimiter //
create procedure pro_book04(num int)
begin
select bid into num from book where bid=num;
end ; //
--調用
set @v_id=3; --給用戶變量賦值
call pro_book04(@v_id);
select @v_id;控制流程語句
#if語句
delimiter //
create procedure if_test(score int)
begin
-- 定義局部變量
declare myLevel varchar(20);
if score>80 then
set myLevel=‘A‘;
elseif score >60 then
set myLevel=‘B‘;
else
set myLevel=‘C‘;
end if;
select myLevel;
end; //
-- 調用
call if_test(70);#while循環
delimiter //
create procedure while_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
while i<=100 do
set sum=sum+i;
set i=i+1;
end while ;
select sum;
end ;//
call while_test()#loop循環
delimiter //
create procedure loop_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
-- 起別名
lip:loop
if i>100 then
-- 離開loop循環
leave lip ;
end if ;
set sum=sum+i;
set i=i+1;
end loop ;
select sum;
end ;//
call loop_test()#repeat循環
delimiter //
create procedure repeat_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
repeat
set sum=sum+i;
set i=i+1;
-- 不要加分號
until i>100
end repeat ;
select sum;
end ;//
call loop_test()(3)存儲函數
存儲在服務器端,有返回值,函數可以作為SQL的一部分進行調用。
**例**:
delimiter //
create function func_01(num int)
-- 返回值類型
returns varchar(20)
deterministic
begin
declare v_name varchar(20);
select bname into v_name from book where bid =num ;
return v_name;
end ; //
set @v_name=func_01(3);
select @v_name;
-- 作為SQL的一部分調用
select * from book where bname=func_01(3);函數和存儲過程的區別:
- 存儲過程有三種參數模式(in、out、inout)實現數據的輸入輸出,而函數是通過返回值進行數據傳遞。
- 關鍵字不同
- 存儲過程可以作為獨立個體執行,函數只能作為SQL的一部分執行。
(4)觸發器
觸發器,存儲在服務器端,由事件調用,不能傳參。
事件類型:增、刪、改
語法:
create trigger 觸發器名
觸發時機(after|before) event(update|delete|insert)
on 需要設置觸發器的表名 for each row (設置為行級觸發器)
begin
一組sql
end;例:
delimiter //;
-- 創建一個觸發器
create trigger tri_test
after delete
-- 設置為行級別的觸發器
on book for each row
begin
insert into book values(old.id,‘悲慘數據‘,‘zzy‘);
end;//
註意:在觸發器中有兩個對象:old、new,old表示刪除數據時那條原數據記錄,
new表示修改和插入數據時,那條新數據記錄。3. MySQL的表的設計
(1)數據庫的三大範式:
- 1NF:所有字段都是原子性的,不可分割的。
- 2NF:非主鍵字段必須與主鍵相關(每一張表只描述一類事物),而不能與主鍵部分相關(在聯合主鍵時有效)
- 3NF:非主鍵字段必須與主鍵相關(每一張表只描述一類事物),而不能與主鍵部分相關(在聯合主鍵時有效)
(2)表的關系:
一一對應
#以人和×××為例
人表:
CREATE TABLE `t_people` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)
×××表:
create table t_idcard(
card_number varchar(18) primary key,
create_date date,
p_id int unique,
foreign key (p_id) REFERENCES t_people(id)
)
註意:設計方法:想辦法讓外鍵字段同時擁有唯一約束,外鍵字段在任意的表中都可以一對多:
以部門和員工表為例:
create table t_emp(
eid int PRIMARY KEY,
ename varchar(50) not null,
job varchar(50),
deptno int ,
foreign key (deptno) REFERENCES t_dept(deptno)
)
部門表:
create table t_dept(
deptno int primary key,
deptname varchar(50)
)
註意:設計方法:只需要在多的那個表中增加一個外鍵約束多對多: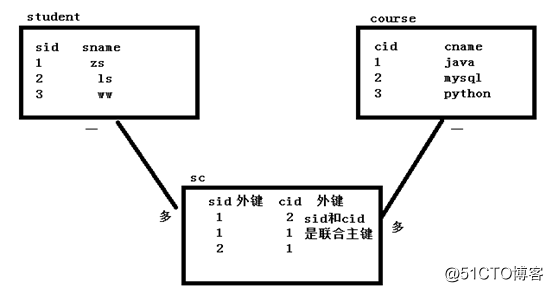
設計方法:需要找一張中間表,轉化成兩個一對多的關系
(3)數據庫的優化:
- SQL的優化
- 在查詢時一般不使用 *,因為在查詢記錄時,一般使用(*),他會將*轉換為列名,然後在查詢(耗時)
- 使用 not null /null 對索引進行搜索,會導致索引失效
- 索引列中使用函數,也會導致索引失效
- 索引列中進行計算,也會導致索引失效
- 索引列不要使用not|!=|<>
- 盡量不要使用or,使用union
- 索引列中使用like,也會導致索引失效
- exists 和 in的使用選擇
- exists先執行主查詢:如果主查詢過濾的比較多,則使用exists
- in先執行子查詢:如果是子查詢的過濾比較多,則使用in。
MySQL的高級部分