
不能開啟資料庫的一次處理 ORA-01092: ORACLE instance terminated. Disconnection forced
今天有人說資料庫掛了,請我幫忙看一下。是9i的庫,測試環境的。
啟動報錯如下:
[[email protected] oracle]$ sqlplus "/as sysdba"
SQL*Plus: Release 9.2.0.4.0 - Production on Thu Jan 12 03:54:18 2012
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 303109300 bytes
Fixed Size 451764 bytes
Variable Size 268435456 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
Database mounted.
ORA-01092: ORACLE instance terminated. Disconnection forced
SQL>
先看一下日誌檔案。
Thu Jan 12 04:40:58 2012
Starting ORACLE instance (normal)
Thu Jan 12 04:40:58 2012
WARNING: EINVAL creating segment of size 0x0000000013400000
fix shm parameters in /etc/system or equivalent
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
SCN scheme 2
Using log_archive_dest parameter default value
LICENSE_MAX_USERS = 0
SYS auditing is disabled
Starting up ORACLE RDBMS Version: 9.2.0.4.0.
System parameters with non-default values:
processes = 150
timed_statistics = TRUE
shared_pool_size = 117440512
large_pool_size = 16777216
java_pool_size = 117440512
control_files = /opt/oracle/product/9.2.0/oradata/testdb/control01.ctl, /opt/oracle/product/9.2.0/oradata/testdb/control02.ctl, /opt/oracle/product/9.2.0/oradata/testdb/control03.ctl
db_block_size = 8192
db_cache_size = 33554432
compatible = 9.2.0.0.0
log_archive_start = TRUE
log_archive_dest_1 = LOCATION=/opt/oracle/product/9.2.0/oradata/testdb/archive
log_archive_format = %t_%s.dbf
db_file_multiblock_read_count= 16
fast_start_mttr_target = 300
undo_management = AUTO
undo_tablespace = UNDOTBS2
undo_retention = 10800
remote_login_passwordfile= EXCLUSIVE
db_domain = webex.com
instance_name = testdb
dispatchers = (PROTOCOL=TCP)
job_queue_processes = 10
hash_join_enabled = TRUE
background_dump_dest = /opt/oracle/product/9.2.0/admin/testdb/bdump
user_dump_dest = /opt/oracle/product/9.2.0/admin/testdb/udump
core_dump_dest = /opt/oracle/product/9.2.0/admin/testdb/cdump
sort_area_size = 524288
db_name = testdb
open_cursors = 300
star_transformation_enabled= FALSE
query_rewrite_enabled = FALSE
pga_aggregate_target = 25165824
aq_tm_processes = 1
PMON started with pid=2
DBW0 started with pid=3
LGWR started with pid=4
CKPT started with pid=5
SMON started with pid=6
RECO started with pid=7
CJQ0 started with pid=8
QMN0 started with pid=9
Thu Jan 12 04:40:58 2012
starting up 1 shared server(s) ...
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
ARCH: STARTING ARCH PROCESSES
ARC0 started with pid=12
ARC0: Archival started
ARC1 started with pid=13
Thu Jan 12 04:40:59 2012
ARC1: Archival started
Thu Jan 12 04:40:59 2012
ARCH: STARTING ARCH PROCESSES COMPLETE
ARC1: Thread not mounted
Thu Jan 12 04:40:59 2012
ARC0: Thread not mounted
Thu Jan 12 04:40:59 2012
ALTER DATABASE MOUNT
Thu Jan 12 04:41:03 2012
Successful mount of redo thread 1, with mount id 3969289179.
Thu Jan 12 04:41:03 2012
Database mounted in Exclusive Mode.
Completed: ALTER DATABASE MOUNT
ALTER DATABASE OPEN
Thu Jan 12 04:41:03 2012
Beginning crash recovery of 1 threads
Thu Jan 12 04:41:03 2012
Started first pass scan
Thu Jan 12 04:41:03 2012
Completed first pass scan
57 redo blocks read, 4 data blocks need recovery
Thu Jan 12 04:41:03 2012
Started recovery at
Thread 1: logseq 94, block 2, scn 2612.28455232
Recovery of Online Redo Log: Thread 1 Group 3 Seq 94 Reading mem 0
Mem# 0 errs 0: /opt/oracle/product/9.2.0/oradata/testdb/redo03.log
Thu Jan 12 04:41:03 2012
Completed redo application
Thu Jan 12 04:41:03 2012
Ended recovery at
Thread 1: logseq 94, block 59, scn 2612.28475290
4 data blocks read, 4 data blocks written, 57 redo blocks read
Crash recovery completed successfully
Thu Jan 12 04:41:03 2012
Thread 1 advanced to log sequence 95
Thread 1 opened at log sequence 95
Current log# 1 seq# 95 mem# 0: /opt/oracle/product/9.2.0/oradata/testdb/redo01.log
Successful open of redo thread 1.
Thu Jan 12 04:41:03 2012
SMON: enabling cache recovery
Thu Jan 12 04:41:03 2012
ARC0: Media recovery disabled
Thu Jan 12 04:41:03 2012
Undo Segment 4 Onlined
Undo Segment 5 Onlined
Undo Segment 6 Onlined
Undo Segment 7 Onlined
Undo Segment 8 Onlined
Undo Segment 9 Onlined
Undo Segment 10 Onlined
Undo Segment 11 Onlined
Undo Segment 12 Onlined
Thu Jan 12 04:41:03 2012
Errors in file /opt/oracle/product/9.2.0/admin/testdb/udump/testdb_ora_4247.trc:
ORA-00600: internal error code, arguments: [kcbgcur_6], [41], [], [], [], [], [], []
Thu Jan 12 04:41:04 2012
Errors in file /opt/oracle/product/9.2.0/admin/testdb/udump/testdb_ora_4247.trc:
ORA-00600: internal error code, arguments: [kcbgcur_6], [41], [], [], [], [], [], []
Error 600 happened during db open, shutting down database
Instance terminated by USER, pid = 4247
ORA-1092 signalled during: ALTER DATABASE OPEN...
提示是open的時候出錯了。
這個600的錯誤,還真不好找。網上看了一下,也沒有找到什麼。以前記得有個分析600的幾個型別的,當時沒有儲存,可惜啊。不過有個文章提到類似的錯誤,是undo引起的,不是600。 先試試。 URL:
先mount起來:
startup mount
看了一下,當前用的是UNDOTBS2, 系統裡面還有UNDOTBS3,那就替換試一下了。
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 10800
undo_suppress_errors boolean FALSE
undo_tablespace string UNDOTBS2
SQL>
SQL> select name from v$tablespace;
NAME
------------------------------
CWMLITE
DRSYS
EXAMPLE
INDX
ODM
SYSTEM
TOOLS
TEMP2
USERS
XDB
UNDOTBS3
PERFSTAT
UNDOTBS2
SQL> create pfile='/opt/oracle/product/9.2.0/admin/testdb/pfile/inittestdb_20120112.ora' from spfile;
File created.
SQL>
SQL> shutdown
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL>
編輯檔案,啟動
SQL> startup pfile='/opt/oracle/product/9.2.0/admin/testdb/pfile/inittestdb_20120112.ora';
ORACLE instance started.
Total System Global Area 303109300 bytes
Fixed Size 451764 bytes
Variable Size 268435456 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
Database mounted.
Database opened.
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 10800
undo_suppress_errors boolean FALSE
undo_tablespace string UNDOTBS3
SQL>
SQL> create spfile from pfile='/opt/oracle/product/9.2.0/admin/testdb/pfile/inittestdb_20120112.ora';
File created.
SQL>
相關推薦
不能開啟資料庫的一次處理 ORA-01092: ORACLE instance terminated. Disconnection forced
今天有人說資料庫掛了,請我幫忙看一下。是9i的庫,測試環境的。 啟動報錯如下: [[email protected] oracle]$ sqlplus "/as sysdba" SQL*Plus: Release 9.2.0.4.0 - Production on
一次較為完整的oracle資料庫資料遷移過程
作為一個後端開發者, 需要處理的問題會非常多非常雜,不斷的接觸各方面的知識,總結心得才能有所提高。 最近我們將甲方的信披系統改造後併入了我們的系統,開發基本完成,接下來資料遷移就是一個大問題了。因為之前其它開發商系統的資料庫設計極爛,所以這次資料遷移稍微顯得麻煩,而資料遷移
記一次處理mysql資料庫無故鎖表的經歷
某日,生產環境上的使用者表突然無故鎖表,原以為只是偶發的bug。所以第一時間想到的解決方案簡單粗暴:重啟資料庫(service mysqld restart)。問題得以解決。 10min後,該表再次鎖表。終於意識到問題並沒有那麼簡單。 經過多方查資料,各種嘗試。比如kill程序等方法,均無效。 最終看到一個,
記錄一次處理https監聽不正確的過程
負載均衡 https 502 nginx 金山雲 今天開發反饋在測試金山雲設備的時候遇到了這樣的一個現象:wget https://funchlscdn.lechange.cn/LCLR/2K02135PAK01979/0/0/20170726085033/dev_201707260850
【譯】Flink + Kafka 0.11端到端精確一次處理語義的實現
網絡 人員 回調 per 算法 connect commit int 學習 本文是翻譯作品,作者是Piotr Nowojski和Michael Winters。前者是該方案的實現者。 原文地址是https://data-artisans.com/blog/end-to-en
Kafka設計解析(二十二)Flink + Kafka 0.11端到端精確一次處理語義的實現
pac 內部 通知 發生 ng- 設計 解析 位移 eas 轉載自 huxihx,原文鏈接 【譯】Flink + Kafka 0.11端到端精確一次處理語義的實現 本文是翻譯作品,作者是Piotr Nowojski和Michael Winters。前者是該方案的實現
記一次處理linux伺服器cpu跑滿的問題
記一次處理linux伺服器cpu跑滿的問題 公司伺服器,突然掛掉了,登入阿里雲後臺才發現,是阿里雲把我們的伺服器給關停了,提示有對外攻擊,使用top命令檢視後發現Cpu(s) us顯示98%多,但是看程序發現,並沒有佔用很多加起來也不過就10%左右。然後就給阿里雲發工單尋求幫助,因為我壓根就
一次成功批量刪除oracle冗餘資料的經歷
問題描述:千辛萬苦往資料庫裡存了幾十萬條資料,發現由於程式問題,有將近10萬條的冗餘資料,此時內心是無比崩潰的,關於怎麼查詢是否有冗餘資料見上一篇文章(https://my.oschina.net/u/3636678/blog/2967373)。 嘗試1:首先想到的當然就是delete語句啦,如下所示:
讓天下沒有難用的資料庫 » 一次資料庫上雲遷移效能下降的排查
背景介紹: 某客戶目前正在將本地的業務系統遷移上雲,測試過程中發現後臺運營系統,在rds上執行時間明顯要比線下PC上自建資料庫執行時間要慢1倍,導致客戶系統割接延期的風險。使用者線下一臺PC伺服器的效能居然還比頂配的RDS跑的快,這讓使用者對RDS的效能產生了質疑,需要立刻調查原因。 問題分析: 通
記一次處理簡訊盜刷問題的解決方案
前言 最近公司的註冊介面經常在半夜被惡意訪問,從而引發簡訊盜刷事件,原本在手機號等引數校驗通過後,註冊介面會對圖形驗證碼進行正確性校驗,校驗通過後再進行簡訊傳送。通過簡訊傳送記錄發現我們的圖形驗證碼很容易就被識別了,沒有起到安全過濾的作用,同時對簡訊傳送
Logstash從資料庫一次同步多張表
一次同步多張表是開發中的一般需求。之前研究了很久找到方法,但沒有詳細總結。 博友前天線上提問,說明這塊理解的還不夠透徹。 我整理下, 一是為了儘快解決博友問題, 二是加深記憶,便於未來產品開發中快速上手。 1、同步原理 原有ES專欄中有詳解,不再贅述。詳細請參
多麼痛的一次領悟ORA-21561: OID generation failed
環境為 2個節點的11.2.0.4的RAC環境 重啟異常 資料庫無法啟動,出現報錯如下 在日誌 /opt/app/grid/11.2.0/log/racoa02/agent/ohasd/oraagent_grid/oraagent_grid.log 201
記一次處理rt-thread優先順序低執行緒無法執行
最近升級了rt-thread的核心程式碼,從3.0正式發行不久後,rt-thread採用了KConfig的配置方式,因為以前搞過linux核心配置,所以對KConfig不算太陌生,rt-thread的配置介面用起來還是相當不錯的,詳細用法可以參考官方相關文件。
記一次處理Apache無法啟動的問題
apache logs 信息 無響應 could not server fff sin 提供服務 一、問題現象使用/usr/local/apache/bin/apachectl start啟動,apache服務無響應。 二、問題分析排查1.使用 ps -ef | grep
硬核!八張圖搞懂 Flink 端到端精準一次處理語義 Exactly-once(深入原理,建議收藏)
### Flink 在 Flink 中需要端到端精準一次處理的位置有三個: 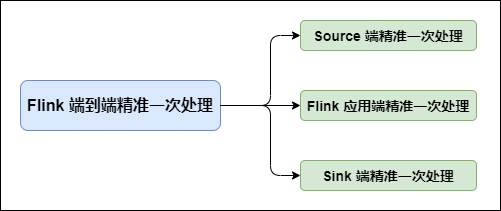 - **Source 端**:資料從上一階段進入到 Flink 時,
一次ORA-600處理
ORACLE ORA-600 UNDO ORA-00600:internal error code, arguments: [4194], [43], [46], [], [], [], [], []出現這種情況,大多數是因為異常宕機,在啟動的時候報的錯誤。DB 不能啟動。 方法一:使用syste
記一次SQLSERVER2008R2資料庫查詢超時問題處理
資料庫環境: WINDOWS2008R2 SQLSERVER2008R2 應用程式環境: REDHAT6.5 TOMCAT JAVA 一、故障現象 某系統應用查詢超時 相關SQL: SELECT v.OBarcode Ba
記一次jdbc連線oracle資料庫佔用CPU過高的問題排查
背景: 公司有一個通訊系統,主要是通訊資料到客戶端程式所指定的資料庫,目前支援sqlserver、mysql和oracle三種類型的資料庫,此篇主要記錄一次oracle資料庫佔用CPU飆高的問題。 &nbs
記一次Oracle RAC一節點重啟後出現故障的處理
因為儲存的相關操作,客戶需要手動重啟rac節點,然而,這個重啟導致了接下來的事故。。。。 由於是遠端跟我溝通,我回復rac環境下可以重啟一個節點,客戶就自信重啟了,出現的故障如下所示: [grid@hxdb01 ~]$ srvctl start nodeapps