
【Linux核心學習筆記四】記憶體管理-夥伴系統
1.夥伴系統演算法描述
linux系統採用夥伴系統演算法來解決外碎片問題。主要做法是記錄現存的空閒連續頁框塊的情況,以儘量避免為滿足對小塊的請求而分割大的空閒塊。
夥伴系統演算法中,把所有的空閒頁框分為11個組,每個組對應一個連結串列,每個連結串列分別包含1、2、4、8、16、32、64、128、256、512和1024個連續頁框。對1024個頁框的請求對應著4MB大小的連續RAM塊。每個塊的第一個頁框的實體地址是該塊大小的整數倍。下面用一個例子來說明該演算法的工作原理。
假設現在我們需要請求一個256個頁框的塊,而256個連續頁框對應的連結串列為空,沒有這樣的塊,那麼系統會繼續查詢512個頁框的塊。如果有這樣的塊,將512的塊分為兩個256的塊,一個用於被請求的塊,一個放入256個連續頁框對應的連結串列。如果512個連續頁框對應的連結串列也為空,那麼系統會繼續查詢1024,頁框的塊。如果有這樣的塊,將1024的塊分為兩個512的塊,放入512個連續頁框對應的連結串列。另一個被繼續分割為兩個256的塊,一個用於被請求的塊,一個放入256個連續頁框對應的連結串列。如果1024個連續頁框對應的連結串列也為空,沒有這樣的塊,系統會報錯,發出錯誤訊號。
以上過程的逆過程就是頁框塊的釋放過程。核心試圖把大小為b的一對空閒夥伴塊合併為一個大小為2b的單獨塊。滿足以下條件的兩個塊稱為夥伴系統:
- 兩個塊具有相同的大小,計作b。
- 它們的實體地址是連續的。
- 第一塊的第一個頁框的實體地址是2xbx2^12的倍數。
2.資料結構
linux系統每個管理區zone對應一個夥伴系統。【Linux核心學習筆記二】記憶體管理-管理區(zone)文中已經對管理區描述符的各個欄位進行了描述。其中的free_area欄位包含了以上演算法中提到的11個連結串列。free_area對應的資料結構如下所示:
struct free_area { struct list_head free_list[MIGRATE_TYPES]; unsigned long nr_free; };
- free_list:該欄位是雙向迴圈連結串列的頭,這個雙向迴圈連結串列集中了大小為2^k頁面的空閒塊對應的頁描述符。頁描述符中的lru欄位指向連結串列中相鄰元素。
- nr_free:指定了該連結串列中空閒頁塊的個數。
最後,一個2^k的空閒頁塊的第一個頁的描述符的private欄位存放了塊的order,也就是數字K。正是由於這個欄位,當頁塊被釋放時,核心可以確定這個塊的夥伴是否也空閒,如果是,它可以把兩個塊介個成大小為2^(k+1)頁的單一塊。
3.頁面分配
linux提供了相當多的API來分配頁面,alloc_pages函式用於頁面分配,夥伴系統的核心函式為__alloc_pages_nodemask,alloc_pages函式的呼叫圖如下圖所示:
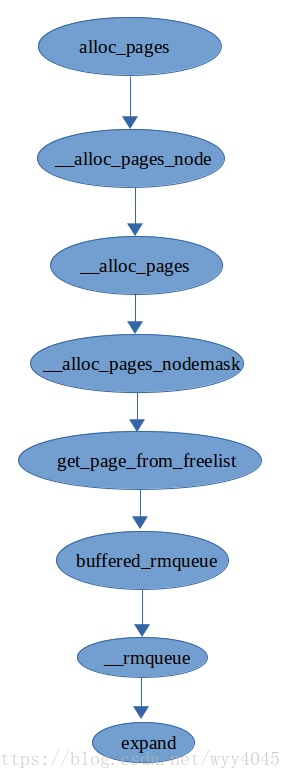
圖1 alloc_pages呼叫圖
所有的函式都有gfp_mask引數,這個引數決定了分配器如何進行分配的一系列掩碼,這些掩碼在<include/linux/gfp.h>中定義如下:
/**
* 和頁面ZONE相關的掩碼
*/
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
/**
* 和分配行為相關的掩碼
*/
#define ___GFP_WAIT 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_COLD 0x100u
#define ___GFP_NOWARN 0x200u
#define ___GFP_REPEAT 0x400u
#define ___GFP_NOFAIL 0x800u
#define ___GFP_NORETRY 0x1000u
#define ___GFP_MEMALLOC 0x2000u
#define ___GFP_COMP 0x4000u
#define ___GFP_ZERO 0x8000u
#define ___GFP_NOMEMALLOC 0x10000u
#define ___GFP_HARDWALL 0x20000u
#define ___GFP_THISNODE 0x40000u
#define ___GFP_RECLAIMABLE 0x80000u
#define ___GFP_NOACCOUNT 0x100000u
#define ___GFP_NOTRACK 0x200000u
#define ___GFP_NO_KSWAPD 0x400000u
#define ___GFP_OTHER_NODE 0x800000u
#define ___GFP_WRITE 0x1000000u這些掩碼分為兩類:一類是和頁面zone相關的掩碼,這些掩碼指定了從哪個zone中分配所需的頁面;一類是和分配行為相關的掩碼,這些掩碼並不限制從哪個記憶體區域中分配記憶體,但會改變分配行為。
- 頁面zone相關的掩碼Zone modifiers:
/*
* GFP bitmasks..
*
* Zone modifiers (see linux/mmzone.h - low three bits)
*
* Do not put any conditional on these. If necessary modify the definitions
* without the underscores and use them consistently. The definitions here may
* be used in bit comparisons.
*/
#define __GFP_DMA ((__force gfp_t)___GFP_DMA)
#define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM)
#define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32)
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* Page is movable */
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)- 分配行為相關的掩碼action modifiers:
/*
* Action modifiers - doesn't change the zoning
*
* __GFP_REPEAT: Try hard to allocate the memory, but the allocation attempt
* _might_ fail. This depends upon the particular VM implementation.
*
* __GFP_NOFAIL: The VM implementation _must_ retry infinitely: the caller
* cannot handle allocation failures. New users should be evaluated carefully
* (and the flag should be used only when there is no reasonable failure policy)
* but it is definitely preferable to use the flag rather than opencode endless
* loop around allocator.
*
* __GFP_NORETRY: The VM implementation must not retry indefinitely and will
* return NULL when direct reclaim and memory compaction have failed to allow
* the allocation to succeed. The OOM killer is not called with the current
* implementation.
*
* __GFP_MOVABLE: Flag that this page will be movable by the page migration
* mechanism or reclaimed
*/
#define __GFP_WAIT ((__force gfp_t)___GFP_WAIT) /* Can wait and reschedule? */
#define __GFP_HIGH ((__force gfp_t)___GFP_HIGH) /* Should access emergency pools? */
#define __GFP_IO ((__force gfp_t)___GFP_IO) /* Can start physical IO? */
#define __GFP_FS ((__force gfp_t)___GFP_FS) /* Can call down to low-level FS? */
#define __GFP_COLD ((__force gfp_t)___GFP_COLD) /* Cache-cold page required */
#define __GFP_NOWARN ((__force gfp_t)___GFP_NOWARN) /* Suppress page allocation failure warning */
#define __GFP_REPEAT ((__force gfp_t)___GFP_REPEAT) /* See above */
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL) /* See above */
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY) /* See above */
#define __GFP_MEMALLOC ((__force gfp_t)___GFP_MEMALLOC)/* Allow access to emergency reserves */
#define __GFP_COMP ((__force gfp_t)___GFP_COMP) /* Add compound page metadata */
#define __GFP_ZERO ((__force gfp_t)___GFP_ZERO) /* Return zeroed page on success */
#define __GFP_NOMEMALLOC ((__force gfp_t)___GFP_NOMEMALLOC) /* Don't use emergency reserves.
* This takes precedence over the
* __GFP_MEMALLOC flag if both are
* set
*/
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL) /* Enforce hardwall cpuset memory allocs */
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)/* No fallback, no policies */
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE) /* Page is reclaimable */
#define __GFP_NOACCOUNT ((__force gfp_t)___GFP_NOACCOUNT) /* Don't account to kmemcg */
#define __GFP_NOTRACK ((__force gfp_t)___GFP_NOTRACK) /* Don't track with kmemcheck */
#define __GFP_NO_KSWAPD ((__force gfp_t)___GFP_NO_KSWAPD)
#define __GFP_OTHER_NODE ((__force gfp_t)___GFP_OTHER_NODE) /* On behalf of other node */
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE) /* Allocator intends to dirty page */
接下來分析頁面的分配。在圖1中已經展示alloc_pages函式的呼叫圖,alloc_pages函式最終呼叫__alloc_pages_nodemask進行頁面分配,該函式是夥伴系統的核心函式。在<mm/page_alloc.c>中,__alloc_pages_nodemask的程式碼如下:
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
struct zoneref *preferred_zoneref;
struct page *page = NULL;
unsigned int cpuset_mems_cookie;
int alloc_flags = ALLOC_WMARK_LOW|ALLOC_CPUSET|ALLOC_FAIR;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = {
.high_zoneidx = gfp_zone(gfp_mask),
.nodemask = nodemask,
.migratetype = gfpflags_to_migratetype(gfp_mask),
};
gfp_mask &= gfp_allowed_mask;
lockdep_trace_alloc(gfp_mask);
might_sleep_if(gfp_mask & __GFP_WAIT);
if (should_fail_alloc_page(gfp_mask, order))
return NULL;
/*
* Check the zones suitable for the gfp_mask contain at least one
* valid zone. It's possible to have an empty zonelist as a result
* of __GFP_THISNODE and a memoryless node
*/
if (unlikely(!zonelist->_zonerefs->zone))
return NULL;
if (IS_ENABLED(CONFIG_CMA) && ac.migratetype == MIGRATE_MOVABLE)
alloc_flags |= ALLOC_CMA;
retry_cpuset:
cpuset_mems_cookie = read_mems_allowed_begin();
/* We set it here, as __alloc_pages_slowpath might have changed it */
ac.zonelist = zonelist;
/* The preferred zone is used for statistics later */
preferred_zoneref = first_zones_zonelist(ac.zonelist, ac.high_zoneidx,
ac.nodemask ? : &cpuset_current_mems_allowed,
&ac.preferred_zone);
if (!ac.preferred_zone)
goto out;
ac.classzone_idx = zonelist_zone_idx(preferred_zoneref);
/* First allocation attempt */
alloc_mask = gfp_mask|__GFP_HARDWALL;
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (unlikely(!page)) {
/*
* Runtime PM, block IO and its error handling path
* can deadlock because I/O on the device might not
* complete.
*/
alloc_mask = memalloc_noio_flags(gfp_mask);
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
}
if (kmemcheck_enabled && page)
kmemcheck_pagealloc_alloc(page, order, gfp_mask);
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
out:
/*
* When updating a task's mems_allowed, it is possible to race with
* parallel threads in such a way that an allocation can fail while
* the mask is being updated. If a page allocation is about to fail,
* check if the cpuset changed during allocation and if so, retry.
*/
if (unlikely(!page && read_mems_allowed_retry(cpuset_mems_cookie)))
goto retry_cpuset;
return page;
}struct alloc_context資料結構是夥伴系統用來分配頁面的上下文。gfp_zone()根據分配標誌,找到最高允許的ZONE索引。gfp_zone()的實現如下:
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
int bit = (__force int) (flags & GFP_ZONEMASK);
z = (GFP_ZONE_TABLE >> (bit * ZONES_SHIFT)) &
((1 << ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}該函式中用到了三個巨集GFP_ZONEMASK,GFP_ZONE_TABLE和ZONES_SHIFT,它們的定義如下:
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)
#define GFP_ZONE_TABLE ( \
(ZONE_NORMAL << 0 * ZONES_SHIFT) \
| (OPT_ZONE_DMA << ___GFP_DMA * ZONES_SHIFT) \
| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << ___GFP_DMA32 * ZONES_SHIFT) \
| (ZONE_NORMAL << ___GFP_MOVABLE * ZONES_SHIFT) \
| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * ZONES_SHIFT) \
| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * ZONES_SHIFT) \
)
/*
* When a memory allocation must conform to specific limitations (such
* as being suitable for DMA) the caller will pass in hints to the
* allocator in the gfp_mask, in the zone modifier bits. These bits
* are used to select a priority ordered list of memory zones which
* match the requested limits. See gfp_zone() in include/linux/gfp.h
*/
#if MAX_NR_ZONES < 2
#define ZONES_SHIFT 0
#elif MAX_NR_ZONES <= 2
#define ZONES_SHIFT 1
#elif MAX_NR_ZONES <= 4
#define ZONES_SHIFT 2
#else
#error ZONES_SHIFT -- too many zones configured adjust calculation
#endifgfpflags_to_migratetype()函式把gfp_mask分配掩碼轉換成MIGRATE_TYPES型別,即是否允許遷移頁面。例如分配掩碼為GFP_KERNEL,那麼MIGRATE_TYPES型別就是MIGRATE_UNMOVABLE;如果分配掩碼是GFP_HIGHUSER_MOVABLE,那麼MIGRATE_TYPES型別就是MIGRATE_MOVABLE。gfpflags_to_migratetype()函式的實現如下:
/* Convert GFP flags to their corresponding migrate type */
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (((gfp_flags & __GFP_MOVABLE) != 0) << 1) |
((gfp_flags & __GFP_RECLAIMABLE) != 0);
}__alloc_pages_nodemask中上下文引數分配好以後,將呼叫get_page_from_freelist()函式來分配物理頁面,get_page_from_freelist()函式的實現如下:
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zonelist *zonelist = ac->zonelist;
struct zoneref *z;
struct page *page = NULL;
struct zone *zone;
nodemask_t *allowednodes = NULL;/* zonelist_cache approximation */
int zlc_active = 0; /* set if using zonelist_cache */
int did_zlc_setup = 0; /* just call zlc_setup() one time */
bool consider_zone_dirty = (alloc_flags & ALLOC_WMARK_LOW) &&
(gfp_mask & __GFP_WRITE);
int nr_fair_skipped = 0;
bool zonelist_rescan;
zonelist_scan:
zonelist_rescan = false;
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
for_each_zone_zonelist_nodemask(zone, z, zonelist, ac->high_zoneidx,
ac->nodemask) {
unsigned long mark;
if (IS_ENABLED(CONFIG_NUMA) && zlc_active &&
!zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* Distribute pages in proportion to the individual
* zone size to ensure fair page aging. The zone a
* page was allocated in should have no effect on the
* time the page has in memory before being reclaimed.
*/
if (alloc_flags & ALLOC_FAIR) {
if (!zone_local(ac->preferred_zone, zone))
break;
if (test_bit(ZONE_FAIR_DEPLETED, &zone->flags)) {
nr_fair_skipped++;
continue;
}
}
/*
* When allocating a page cache page for writing, we
* want to get it from a zone that is within its dirty
* limit, such that no single zone holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the zone's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* This may look like it could increase pressure on
* lower zones by failing allocations in higher zones
* before they are full. But the pages that do spill
* over are limited as the lower zones are protected
* by this very same mechanism. It should not become
* a practical burden to them.
*
* XXX: For now, allow allocations to potentially
* exceed the per-zone dirty limit in the slowpath
* (ALLOC_WMARK_LOW unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* zones are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of zones in the
* dirty-throttling and the flusher threads.
*/
if (consider_zone_dirty && !zone_dirty_ok(zone))
continue;
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (!zone_watermark_ok(zone, order, mark,
ac->classzone_idx, alloc_flags)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (IS_ENABLED(CONFIG_NUMA) &&
!did_zlc_setup && nr_online_nodes > 1) {
/*
* we do zlc_setup if there are multiple nodes
* and before considering the first zone allowed
* by the cpuset.
*/
allowednodes = zlc_setup(zonelist, alloc_flags);
zlc_active = 1;
did_zlc_setup = 1;
}
if (zone_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zone, zone))
goto this_zone_full;
/*
* As we may have just activated ZLC, check if the first
* eligible zone has failed zone_reclaim recently.
*/
if (IS_ENABLED(CONFIG_NUMA) && zlc_active &&
!zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
ret = zone_reclaim(zone, gfp_mask, order);
switch (ret) {
case ZONE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case ZONE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->classzone_idx, alloc_flags))
goto try_this_zone;
/*
* Failed to reclaim enough to meet watermark.
* Only mark the zone full if checking the min
* watermark or if we failed to reclaim just
* 1<<order pages or else the page allocator
* fastpath will prematurely mark zones full
* when the watermark is between the low and
* min watermarks.
*/
if (((alloc_flags & ALLOC_WMARK_MASK) == ALLOC_WMARK_MIN) ||
ret == ZONE_RECLAIM_SOME)
goto this_zone_full;
continue;
}
}
try_this_zone:
page = buffered_rmqueue(ac->preferred_zone, zone, order,
gfp_mask, ac->migratetype);
if (page) {
if (prep_new_page(page, order, gfp_mask, alloc_flags))
goto try_this_zone;
return page;
}
this_zone_full:
if (IS_ENABLED(CONFIG_NUMA) && zlc_active)
zlc_mark_zone_full(zonelist, z);
}
/*
* The first pass makes sure allocations are spread fairly within the
* local node. However, the local node might have free pages left
* after the fairness batches are exhausted, and remote zones haven't
* even been considered yet. Try once more without fairness, and
* include remote zones now, before entering the slowpath and waking
* kswapd: prefer spilling to a remote zone over swapping locally.
*/
if (alloc_flags & ALLOC_FAIR) {
alloc_flags &= ~ALLOC_FAIR;
if (nr_fair_skipped) {
zonelist_rescan = true;
reset_alloc_batches(ac->preferred_zone);
}
if (nr_online_nodes > 1)
zonelist_rescan = true;
}
if (unlikely(IS_ENABLED(CONFIG_NUMA) && zlc_active)) {
/* Disable zlc cache for second zonelist scan */
zlc_active = 0;
zonelist_rescan = true;
}
if (zonelist_rescan)
goto zonelist_scan;
return NULL;
}
get_page_from_freelist()函式中,for_each_zone_zonelist_nodemask()在允許的ZONE管理區裡面進行遍歷,找到接下來可以從哪些zone中分配記憶體。找到匹配的zone以後,對zone進行一系列的檢查。最後呼叫buffered_rmqueue()函式在夥伴系統空閒緩衝連結串列中分配頁面。buffered_rmqueue()的實現如下:
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, int migratetype)
{
unsigned long flags;
struct page *page;
bool cold = ((gfp_flags & __GFP_COLD) != 0);
if (likely(order == 0)) {
struct per_cpu_pages *pcp;
struct list_head *list;
local_irq_save(flags);
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list = &pcp->lists[migratetype];
if (list_empty(list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, cold);
if (unlikely(list_empty(list)))
goto failed;
}
if (cold)
page = list_entry(list->prev, struct page, lru);
else
page = list_entry(list->next, struct page, lru);
list_del(&page->lru);
pcp->count--;
} else {
if (unlikely(gfp_flags & __GFP_NOFAIL)) {
/*
* __GFP_NOFAIL is not to be used in new code.
*
* All __GFP_NOFAIL callers should be fixed so that they
* properly detect and handle allocation failures.
*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with
* __GFP_NOFAIL.
*/
WARN_ON_ONCE(order > 1);
}
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
}
__mod_zone_page_state(zone, NR_ALLOC_BATCH, -(1 << order));
if (atomic_long_read(&zone->vm_stat[NR_ALLOC_BATCH]) <= 0 &&
!test_bit(ZONE_FAIR_DEPLETED, &zone->flags))
set_bit(ZONE_FAIR_DEPLETED, &zone->flags);
__count_zone_vm_events(PGALLOC, zone, 1 << order);
zone_statistics(preferred_zone, zone, gfp_flags);
local_irq_restore(flags);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}buffered_rmqueue()中,如果order=0,即只分配一個頁面,那就直接在本CPU的快取中分配,即在zone->pageset列表中分配。如果要分配多個頁面,必須從空閒連結串列中分配,此時,呼叫__rmqueue()分配空閒塊。__rmqueue()的實現如下:
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype)
{
struct page *page;
retry_reserve:
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
if (!page)
page = __rmqueue_fallback(zone, order, migratetype);
/*
* Use MIGRATE_RESERVE rather than fail an allocation. goto
* is used because __rmqueue_smallest is an inline function
* and we want just one call site
*/
if (!page) {
migratetype = MIGRATE_RESERVE;
goto retry_reserve;
}
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}__rmqueue()呼叫__rmqueue_smallest()先從最小的連結串列開始分配,__rmqueue_smallest()程式碼如下:
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}函式__rmqueue_smallest()從小到大遍歷zone空閒連結串列,如果相應的遷移型別連結串列裡面沒有空閒頁面了,就繼續遍歷下一個大塊連結串列。如果該空閒連結串列不為空,就從該連結串列中獲取一個空閒塊,此時,呼叫expand()函式,對較大的空閒塊進行切分。切分後得到的空閒塊,一部分用於滿足請求,一部分放回夥伴系統。expand()函式的實現如下:
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
if (IS_ENABLED(CONFIG_DEBUG_PAGEALLOC) &&
debug_guardpage_enabled() &&
high < debug_guardpage_minorder()) {
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
set_page_guard(zone, &page[size], high, migratetype);
continue;
}
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}
expand()函式中,low是被請求的order,high是當前current_order。如果high > low,area和high就減1,並將剩下的記憶體塊新增到低一級的空閒連結串列中。
此時,所請求的頁面就分配成功了,__rmqueue()函式會返回分配到的頁面的起始地址。但是還沒結束,__rmqueue()成功分配頁面後,還需再回到buffered_rmqueue()函式中,此時,執行zone_statistics()函式做一些統計資料的計算。然後再回到get_page_from_freelist()函式中,呼叫prep_new_page()函式做一些規整工作和正確性檢查。至此,頁面分配的工作就完成了。
4.頁面釋放
free_pages()函式用於釋放頁面,free_pages()函式的呼叫圖如下所示:
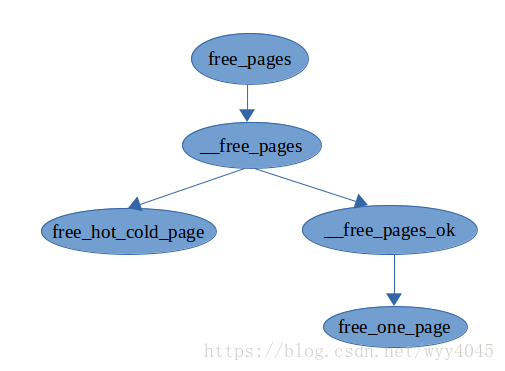
圖2 free_pages()函式呼叫圖
free_pages()函式呼叫__free_pages()函式進行頁面釋放,_free_pages()是釋放頁面的核心函式,程式碼如下:
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_cold_page(page, false);
else
__free_pages_ok(page, order);
}
}當order為0時,此時呼叫free_hot_cold_page()釋放一個頁面,將該頁面放入hot池中,free_hot_cold_page()的程式碼如下:
void free_hot_cold_page(struct page *page, bool cold)
{
//頁面所屬的zone
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
unsigned long flags;
unsigned long pfn = page_to_pfn(page);
int migratetype;
if (!free_pages_prepare(page, 0))
return;
migratetype = get_pfnblock_migratetype(page, pfn);
set_pcppage_migratetype(page, migratetype);
local_irq_save(flags);
__count_vm_event(PGFREE);
/*
* We only track unmovable, reclaimable and movable on pcp lists.
* Free ISOLATE pages back to the allocator because they are being
* offlined but treat RESERVE as movable pages so we can get those
* areas back if necessary. Otherwise, we may have to free
* excessively into the page allocator
*/
if (migratetype >= MIGRATE_PCPTYPES) {
if (unlikely(is_migrate_isolate(migratetype))) {
free_one_page(zone, page, pfn, 0, migratetype);
goto out;
}
migratetype = MIGRATE_MOVABLE;
}
//當前CPU的快取
pcp = &this_cpu_ptr(zone->pageset)->pcp;
if (!cold)//加到快取的前面,保持其熱度。
list_add(&page->lru, &pcp->lists[migratetype]);
else//否則加到後面
list_add_tail(&page->lru, &pcp->lists[migratetype]);
//快取計數
pcp->count++;
//快取中頁面過多,還到連結串列中去.
if (pcp->count >= pcp->high) {
unsigned long batch = READ_ONCE(pcp->batch);
free_pcppages_bulk(zone, batch, pcp);
pcp->count -= batch;
}
out:
local_irq_restore(flags);
}
當order不為0時,呼叫__free_pages_ok()釋放多個頁面,程式碼如下:
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page);
if (!free_pages_prepare(page, order))
return;
migratetype = get_pfnblock_migratetype(page, pfn);
local_irq_save(flags);
__count_vm_events(PGFREE, 1 << order);
free_one_page(page_zone(page), page, pfn, order, migratetype);
local_irq_restore(flags);
}__free_pages_ok()通過呼叫free_one_page()來釋放頁面,而free_one_page()最終呼叫__free_one_page()來釋放頁面。釋放記憶體塊時,會查詢相鄰的記憶體塊是否空閒,如果空閒,就會合併成一個大的記憶體塊,放到高一階的空閒連結串列free_area中,如果還能繼續合併相鄰的記憶體塊,就會繼續合併,轉移到更高階的空閒連結串列free_area中,這個過程會一直重複下去,直至所有可能合併的記憶體塊都已經合併,程式碼如下:
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long page_idx;
unsigned long combined_idx;
unsigned long uninitialized_var(buddy_idx);
struct page *buddy;
int max_order = MAX_ORDER;
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (is_migrate_isolate(migratetype)) {
/*
* We restrict max order of merging to prevent merge
* between freepages on isolate pageblock and normal
* pageblock. Without this, pageblock isolation
* could cause incorrect freepage accounting.
*/
max_order = min(MAX_ORDER, pageblock_order + 1);
} else {
__mod_zone_freepage_state(zone, 1 << order, migratetype);
}
page_idx = pfn & ((1 << max_order) - 1);
VM_BUG_ON_PAGE(page_idx & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
while (order < max_order - 1) {
buddy_idx = __find_buddy_index(page_idx, order);
buddy = page + (buddy_idx - page_idx);
if (!page_is_buddy(page, buddy, order))
break;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_idx = buddy_idx & page_idx;
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
*/
if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) {
struct page *higher_page, *higher_buddy;
combined_idx = buddy_idx & page_idx;
higher_page = page + (combined_idx - page_idx);
buddy_idx = __find_buddy_index(combined_idx, order + 1);
higher_buddy = higher_page + (buddy_idx - combined_idx);
if (page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}相關推薦
【Linux核心學習筆記四】記憶體管理-夥伴系統
1.夥伴系統演算法描述 linux系統採用夥伴系統演算法來解決外碎片問題。主要做法是記錄現存的空閒連續頁框塊的情況,以儘量避免為滿足對小塊的請求而分割大的空閒塊。 夥伴系統演算法中,把所有的空閒頁框分為11個組,每個組對應一個連結串列,每個連結串列分
【LINUX C學習筆記 3】管道通訊2-標準流管道
從檔案結構體指標stream中讀取資料,每次讀取一行。讀取的資料儲存在buf指向的字元陣列中,每次最多讀取bufsize-1個字元(第bufsize個字元賦'\0'),如果檔案中的該行,不足bufsize個字元,則讀完該行就結束。如若該行(包括最後一個換行符)的字元數超過bufsize-1,則fgets只返
Linux核心學習筆記(一) 虛擬檔案系統VFS
什麼是VFS Vritual Filesystem 是給使用者空間程式提供統一的檔案和檔案系統訪問介面的核心子系統。藉助VFS,即使檔案系統的型別不同(比如NTFS和ext3),也可以實現檔案系統之間互動(移動、複製檔案等), 從使用者空間程式的角度來看,
Linux核心驅動學習(四)----記憶體管理子系統
kmalloc()和vmalloc()介紹 kmalloc() 用於申請較小的、連續的實體記憶體 1. 以位元組為單位進行分配,在<linux/slab.h>中 2. void *kmalloc(size_t size, int flags) 分配的記憶體實體地址上連續,虛擬地址上自然
Linux核心學習筆記九——核心記憶體管理方式
一 頁 核心把物理頁作為記憶體管理的基本單位;記憶體管理單元(MMU)把虛擬地址轉換為物理 地址,通常以頁為單位進行處理。MMU以頁大小為單位來管理系統中的也表。 32位系統:頁大小4KB 64位系統:頁大小8KB 核心
【opencv學習筆記四】opencv3.4.0圖形使用者介面highgui函式解析
在筆記二中我們已經知道了,在highgui資料夾下的正是opencv圖形使用者介面功能結構,我們這篇部落格所說的便是D:\Program Files\opencv340\opencv\build\include\opencv2\highgui\highgui.hpp中的函數了
java 核心學習筆記(四) 單例類
com null tools 初始化 equal inf div 特殊 對象 如果一個類始終只能創建一個實例,那麽這個類被稱作單例類。 一些特殊的應用場景可能會用到,為了保證只能創建一個實例,需要將構造方法用private修飾,不允許在類之外的其它地方創建類的實例。 又要保
linux初級學習筆記四:Linux文件管理類命令詳解!(視頻序號:03_1)
單詞 linux初級 linux文件管理 查看 stat 顯示行數 swd 字符處理 行數 本節學習的命令:cat(tac),more,less,head,tail,cut,sort,uniq,wc,tr 本節學習的技能:目錄管理 文件管理
【Python爬蟲學習筆記2】urllib庫的基本使用
代理服務 cor proc 技術 origin car windows tpc -c urllib庫是python內置的實現HTTP請求的基本庫,通過它可以模擬瀏覽器的行為,向指定的服務器發送一個請求,並保存服務器返回的數據。 urlopen函數 函數原型:urlopen(
【Python爬蟲學習筆記10】多線程中的生產者消費者模式
其中 因此 問題 共享 and 生產者消費者模式 共享問題 由於 接下來 在多線程編程中,最經典的模式是生產者消費者模式。其中,生產者是專門用來生產數據的線程,它把數據存放在一個中間變量中;而消費者則從這個中間變量取出數據進行消費。由於生產者和消費者共享中間變量,這些變量大
Linux核心學習筆記(2)—— 程序
來源:《Linux核心設計與實現(第2版)》第三章 Robert Love 知識點很少,蝸牛慢慢爬~~~ 1. 什麼是程序? 程序是處於執行期的程式以及它所包含的資源的總稱。所謂的資源,像開啟的檔案、掛起的訊號、核心內部資料、處理器狀態、地址空間、一
【Robot定位 學習筆記 1】GPS和IMU(慣導)在無人駕駛中的應用
無人駕駛定位技術 行車定位是無人駕駛最核心的技術之一,全球定位系統(GPS)在無人駕駛定位中也擔負起相當重要的職責。然而無人車是在複雜的動態環境中行駛,尤其在大城市,GPS多路徑反射的問題會很明顯。這樣得到的GPS定位資訊很容易就有幾米的誤差。對於在有限寬度高速行駛的汽車來說,這樣的誤差很有可能
【 C/C++學習筆記整理】--3.取陣列中的其中一位,將其中幾位組合起來
10.定義一個數組,取陣列中的其中幾位,將其中幾位組合起來 const int f[10]={6,2,5,5,4,5,6,3,7,6}; int match(int num) { int k=0; for(int i=n
【 C/C++學習筆記整理】--2.break與return0、常用函式的用法
5.break和return 0 的區別 break 是跳出迴圈,執行迴圈體的外的程式;return 0 是結束程式,返回到main函式 6.sort()函式的用法 sort(begin,end,cmp),cmp引數可以沒有,如
【 C/C++學習筆記整理】--1.常量的用法、指標與陣列的區別
巨集常量與const常量的區別: 指標與陣列的區別: ++i和i++的區別: 求X的n次冪 pow(X,n); 1.巨集常量與const常量的區別: 巨集常量,如 #define MAX_NUM 65536 本質為字
【java併發學習筆記2】
(一)基本概念 1.同步和非同步: 同步(Sync) 所謂同步,就是發出一個功能呼叫時,在沒有得到結果之前,該呼叫就不返回或繼續執行後續操作。 簡單來說,同步就是必須一件一件事做,等前一件做完了才能做下一件事。 例如:B/S模式中的表單提交,具體過程是:客戶端提交請
linux核心學習筆記------iP選項處理(一)
ip首部分為固定部分和選項部分;固定部分為20個位元組,而選項部分則是變長的,最長不超過40個位元組。選項的格式分為單位元組和多位元組兩種。單位元組只包括一個位元組的選項型別,而多位元組則除一個位元組的型別之外,還包括選項長度以及選項資料。包括以下幾種ip選項: 1、選項列
linux核心學習筆記------ip報文組裝
ip報文有分片就會有組裝。在接收方,只有報文的所有分片被重新組合後才會提交到上層協議。核心組裝ip報文用到了ipq結構體:(注,這系列原始碼中的註釋都來自:http://blog.csdn.net/justlinux2010) struct ipq { struct in
linux核心記憶體管理學習之二(實體記憶體管理--夥伴系統)
linux使用夥伴系統來管理實體記憶體頁。 一、夥伴系統原理 1. 夥伴關係 定義:由一個母實體分成的兩個各方面屬性一致的兩個子實體,這兩個子實體就處於夥伴關係。在作業系統分配記憶體的過程中,一個記憶體塊常常被分成兩個大小相等的記憶體塊,這兩個大小相等的記憶體塊就處於夥伴關
Linux核心學習筆記(一)——Linux核心簡介
Unix系統業已演化成一個具有相似應用程式程式設計介面(API),並且基於相似設計理念的作業系統家族。 1、Unix的歷史 Unix是從貝爾實驗室的一個失敗的多使用者作業系統Multics中涅槃而生的。 時間 事件 19