
因子分解機FM原理及SGD訓練
1.背景
Steffen Rendle於2010年提出Factorization Machines(下面簡稱FM),併發布開源工具libFM。FM的提出主要對比物件是SVM,與SVM相比,有如下幾個優勢
(1)對於輸入資料是非常稀疏(比如自動推薦系統),FM可以,而SVM會效果很差,因為訓出的SVM模型會面臨較高的bias。
(2)FMs擁有線性的複雜度, 可以通過 primal 來優化而不依賴於像SVM的支援向量機。
2.模型
2-way FM(degree = 2)是FM中具有代表性,且比較簡單的一種。就以其為例展開介紹。其對輸出值是如下建模

其中,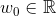
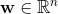
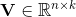
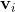
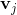
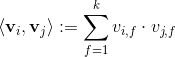
k是定義factorization維度的超引數,是正整數
因子分解機FM也可以推廣到高階的形式,即將更多互異特徵分量之間的相互關係考慮進來。
3.用途
(1)迴歸問題(Regression):可以採用最小均方誤差作為優化的標準(深入理解可以從高斯分佈、極大似然估計入手)
(2)二分類問題(Binary Classification):利用sigmoid函式。詳細原因見 地址
(3)排序(Ranking)
4.交叉項係數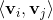
(1)示例
樣本資料

FM交叉項係數

(2)求解
表面上看FM模型的第3項的計算複雜度為O(kn^2),但其實可以經過簡單的數學處理,計算複雜度降為O(kn)。
數學原理:主要是採用瞭如公式((a+b+c)2−a2−b2−c2求出交叉項
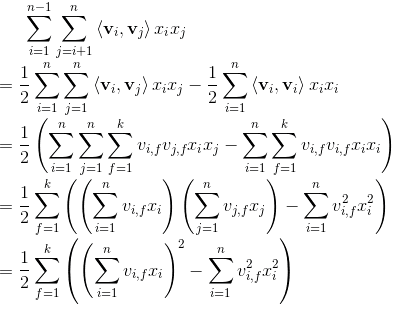
5.SGD求解引數
本文利用隨機梯度下降SGD進行引數學習,也是一種簡單的線上學習方法。
隨機梯度下降與梯度下降主要差別在於batch size不一樣
注:大家可以根據自己需要定義Loss Function,通過梯度下降得到引數更新的公式
最初的V通過正態分佈的形式給出
所示程式碼是通過簡單的似然估計進行二分類從而進行引數更新

後續會更新利用FTRL訓練FM
相關推薦
因子分解機FM原理及SGD訓練
1.背景 Steffen Rendle於2010年提出Factorization Machines(下面簡稱FM),併發布開源工具libFM。FM的提出主要對比物件是SVM,與SVM相比,有如下幾個優
因子分解機(FM) +場感知分解機 (FFM) 入門
前言 FM和FFM模型是最近幾年提出的模型,憑藉其在資料量比較大並且特徵稀疏的情況下,仍然能夠得到優秀的效能和效果的特性,屢次在各大公司舉辦的CTR預估比賽中獲得不錯的戰績。在計算廣告領域,點選率CTR(click-through rate)和轉化率CVR(conversi
因子分解機 FM和FFM
因子分解機 Factorization Machine 因子分解機主要是考慮了特徵之間的關聯。 FM主要是為了解決資料稀疏的情況下,(而SVM無法解決稀疏問題),特徵怎樣組合的問題。 資料稀疏是指資料的維度很大,但是其中為0的維度很多。推薦系統是常見應用場
ml課程:FM因子分解機介紹及相關程式碼
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 FM(factorization machines)表示因子分解機,是由Steffen Rendle提出的一種基於矩陣分解的機器學習演算法。目前,被廣泛的應用於廣告預估模型中,相比LR而言,效果更好。主要目標是:解決資料稀疏的情況下,特
FM(因子分解機系列)
FM(Factorization Machine) 引子 機器學習的通常模式為學習輸入到輸出的變換,比如最常見的線性迴歸模型,輸入為X,輸出為Y,通常輸入為高維資料,X是一個向量,形式如下: y=w1x1+w2x2+...+wnxn 線性迴歸是最簡單
FM(Factorization Machine,因子分解機)演算法個人理解
1. FM是什麼 因子分解機(Factorization Machine, FM)是由Steffen Rendle提出的一種基於矩陣分解的機器學習演算法。 1.1 背景 常見的線性模型,比如線性迴歸、邏輯迴歸等,它只考慮了每個特徵對結果的單獨影響,而沒有考慮特徵間的組合
萬字長文,詳解推薦系統領域經典模型FM因子分解機
在上一篇文章當中我們剖析了Facebook的著名論文GBDT+LR,雖然這篇paper在業內廣受好評,但是畢竟GBDT已經是有些老舊的模型了。今天我們要介紹一個業內使用得更多的模型,它誕生於2010年,原作者是Steffen Rendle。雖然誕生得更早,但是它的活力更強,並且衍生出了多種版本。我們今天剖析的
光纖鐳射打標機的原理及特點
光纖鐳射打標機原理: 光纖鐳射器採用一體化整體結構,無光學汙染,功率耦合損失和空氣冷卻,具有其他鐳射器不具備的高效率,長壽命和少維護等效能.光纖鐳射打標機在鐳射打標應用方面具有許多獨特的優勢.與傳統的固體鐳射器使用晶體棒作為鐳射介質不同,光纖鐳射器採用很長的摻鐿雙包層光纖作為鐳射介質,並
簡單易學的機器學習演算法——因子分解機(Factorization Machine)
#coding:UTF-8 from __future__ import division from math import exp from numpy import * from random import normalvariate#正態分佈 from datetime import datetime
【機器學習】支援向量機SVM原理及推導
參考:http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399 部分圖片來自於上面部落格。 0 由來 在二分類問題中,我們可以計算資料代入模型後得到的結果,如果這個結果有明顯的區別,
因子分解機(libffm+xlearn)
因子分解機 一、簡介 在CTR和CVR預估任務中,可能有大量的ID類特徵(Categorical Feature),一般來說並不適合直接送入樹模型(xgboost完全不支援,lightgbm只根據取值不同),一種常用的做法是通過Label Encod
感知機演算法原理及推導
感知機(Perceptron)是二分類問題的線性分類模型,其輸入為例項的特徵向量,輸出為例項的類別,取+1和-1二值。 感知機於輸入空間(特徵空間)中將例項劃分為正負兩類的分離超平面,屬於判別模型。感知機於1957年由Rosenblatt提出,是神經網路和支援向量機的基礎
RBM(受限玻爾茲曼機)原理及程式碼
EBMs 的隱藏神經元 在很多情況下, 我們看不到部分的隱藏單元 , 或者我們要引入一些不可見的參量來增強模型的能力.所以我們考慮一些可見的神經元(依然表示為 ) 和 隱藏的部分 . 我們可以這樣寫我們的表示式:
從SVD、SVD++到因子分解機
什麼是因子分解?在本文的含義表示:矩陣分解、因子分解機等等。而什麼是矩陣分解、因子分解機?看完這篇文章你將會有答案。 傳統推薦系統中的矩陣分解 在很多情況下,資料的一小段攜帶了資料集中的大部分資訊,其他資訊則要麼是噪聲,要麼就是毫不相關的資訊。矩
推薦系統學習筆記之四 Factorization Machines 因子分解機 + Field-aware Factorization Machine(FFM) 場感知分解機
前言 Factorization Machines(FM) 因子分解機是Steffen Rendle於2010年提出,而Field-aware Factorization Machine (FFM) 場感知分解機最初的概念來自於Yu-Chin Juan與其比賽
奇異值分解SVD計算原理及JAVA程式碼
SVD是什麼? SVD是針對非方陣的特徵降維方法,對於方陣通常用PCA來進行降維。設A是一個m*n矩陣 m>=n。那麼對A進行奇異值分解的結果就表示為(V.T的大小是r*n): 其中矩陣U中的列向量被稱為左奇異向量,V中的行向量被成為右奇異向量,Σ是一個對角矩陣
(一)因式分解機(Factorization Machine,FM)原理及實踐
因子分解機(Factorization Machine),是由Konstanz大學(德國康斯坦茨大學)Steffen Rendle(現任職於Google)於2010年最早提出的,旨在解決大規模稀疏資料下的特徵組合問題。原論文見此。 不久後,FM的升級版模型場感知分解機(Field-awa
學一點 mysql 雙機異地熱備份----快速理解mysql主從,主主備份原理及實踐
server counter ror 位置 正在 大型 主循環 備份 配置詳解 雙機熱備的概念簡單說一下,就是要保持兩個數據庫的狀態自動同步。對任何一個數據庫的操作都自動應用到另外一個數據庫,始終保持兩個數據庫數據一致。 這樣做的好處多。 1. 可以做災備,其中一個壞了可
奇異值分解(SVD)原理及應用
4.4 存在 post 定性 tro ant 二維 5.1 spl 一、奇異值與特征值基礎知識: 特征值分解和奇異值分解在機器學習領域都是屬於滿地可見的方法。兩者有著很緊密的關系,我在接下來會談到,特征值分解和奇異值分解的目的都是一樣,就是提取出一個矩陣最重要的特征
ssh原理及管理機分發公鑰方法
ssh原理:在SSH安全協議的原理中, 是一種非對稱加密與對稱加密演算法的結合。 ssh登入有2種方法:賬號密碼登入和公鑰登入。 1.帳號密碼登入,沒辦法公證,不像https有CA證書公證。 1.服務端收到登入請求後,首先互換公鑰。 2.客戶端用服務端的公鑰加密賬號密碼併發送 3.服務端用自