
《推薦系統》基於標籤的使用者推薦系統
1:聯絡使用者興趣和物品的方式
2:標籤系統的典型代表
3:使用者如何打標籤
4:基於標籤的推薦系統
5:演算法的改進
6:標籤推薦
一:聯絡使用者興趣和物品的方式
推薦系統的目的是聯絡使用者的興趣和物品,這種聯絡方式需要依賴不同的媒介。目前流行的推薦系統基本上是通過三種方式聯絡使用者興趣和物品。
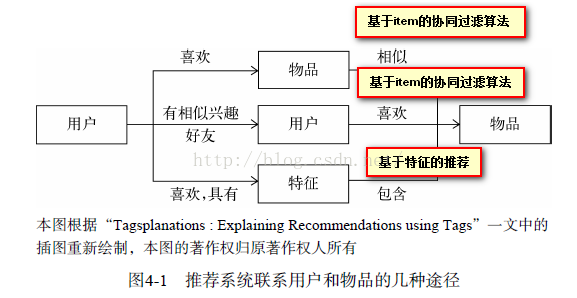
1:利用使用者喜歡過的物品,給使用者推薦與他喜歡過的物品相似的物品,即基於item的系統過濾推薦演算法(演算法分析可參考:點選閱讀)
2:利用使用者和興趣使用者興趣相似的其他使用者,給使用者推薦哪些和他們興趣愛好相似的其他使用者喜歡的物品,即基於User的協同過濾推薦演算法(演算法分析可參考:
3:通過一些特徵聯絡使用者和物品,給使用者推薦那些具有使用者喜歡的特徵的物品,這裡的特徵有不同的表現形式,比如可以表現為物品的屬性集合,也可以表現為隱語義向量,而下面我們要討論的是一種重要的特徵表現形式——標籤
二:標籤系統的典型代表
pass掉那些國外網站,比如說豆瓣圖書(左),網易雲音樂(右)
標籤系統確實能夠幫助使用者發現他們喜歡和感興趣的物品
三:使用者如何打標籤
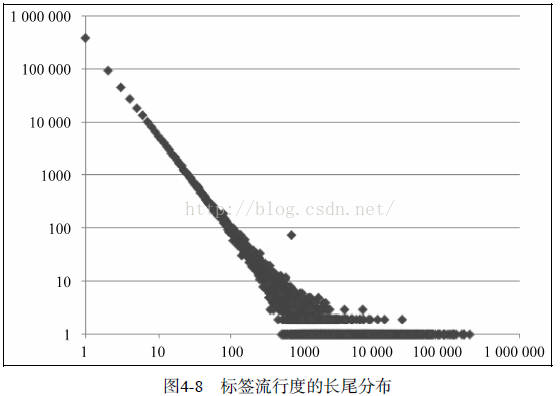
在網際網路中每個人的行為都是隨機的,但其實這些表面的行為隱藏著很多規律,那麼我們對使用者打的標籤進行統計呢,便引入了標籤流行度,我們定義的一個標籤被一個使用者使用在一個物品上,他的流行度就加1,可以如下程式碼實現:
- #統計標籤流行度
- def TagPopularity(records):
- tagfreq = dict()
- for user, item ,tag in records:
- if tag notin tagfreq:
- tagfreq[tag] = 1
- else:
- tagfreq[tag] +=1
- return tagfreq
在使用者看到一個物品時,我們希望他打的標籤是能夠準確的描述物品內容屬性的關鍵詞,但使用者往往不是按照我們的想法操作,而是可能給物品打上各種各樣奇奇怪怪的標籤,此時便需要我們人工編輯一些特定的標籤供使用者選擇,Scott A. Golder 總結了Delicious上的標籤,將它們分為如下幾類。
表明物品是什麼 比如是一隻鳥,就會有“鳥”這個詞的標籤;是豆瓣的首頁,就有一個標籤叫“豆瓣”;是喬布斯的首頁,就會有個標籤叫“喬布斯”。 表明物品的種類 比如在Delicious的書籤中,表示一個網頁類別的標籤包括 article(文章)、blog(部落格)、 book(圖書)等。
表明誰擁有物品 比如很多部落格的標籤中會包括部落格的作者等資訊。
表達使用者的觀點 比如使用者認為網頁很有趣,就會打上標籤funny(有趣),認為很無聊,就會打上標籤boring(無聊)。
使用者相關的標籤 比如 my favorite(我最喜歡的)、my comment(我的評論)等。
使用者的任務 比如 to read(即將閱讀)、job search(找工作)
比如在豆瓣上,標籤便被分為如下幾個類別
四:基於標籤的推薦系統
使用者用標籤來描述對物品的看法,因此標籤是聯絡使用者和物品的紐帶,也是反應使用者興趣的重要資料來源,如何利用使用者的標籤資料提高個性化推薦結果的質量是推薦系統研究的重要課題。
豆瓣很好地利用了標籤資料,它將標籤系統融入到了整個產品線中。
首先,在每本書的頁面上,豆瓣都提供了一個叫做“豆瓣成員常用標籤”的應用,它給出了這本書上使用者最常打的標籤。
同時,在使用者給書做評價時,豆瓣也會讓使用者給圖書打標籤。
最後,在最終的個性化推薦結果裡,豆瓣利用標籤將使用者的推薦結果做了聚類,顯示了對不同標籤下使用者的推薦結果,從而增加了推薦的多樣性和可解釋性。
一個使用者標籤行為的資料集一般由一個三元組的集合表示,其中記錄(u, i, b) 表示使用者u給物品i打上了標籤b。當然,使用者的真實標籤行為資料遠遠比三元組表示的要複雜,比如使用者打標籤的時間、使用者的屬性資料、物品的屬性資料等。但是為了集中討論標籤資料,只考慮上面定義的三元組形式的資料,即使用者的每一次打標籤行為都用一個三元組(使用者、物品、標籤)表示。
1:試驗設定
本節將資料集隨機分成10份。這裡分割的鍵值是使用者和物品,不包括標籤。也就是說,使用者對物品的多個標籤記錄要麼都被分進訓練集,要麼都被分進測試集,不會一部分在訓練集,另一部分在測試集中。然後,我們挑選1份作為測試集,剩下的9份作為訓練集,通過學習訓練集中的使用者標籤資料預測測試集上使用者會給什麼物品打標籤。對於使用者u,令R(u)為給使用者u的長度為N的推薦列表,裡面包含我們認為使用者會打標籤的物品。令T(u)是測試集中使用者u實際上打過標籤的物品集合。然後,我們利用準確率(precision)和召回率(recall)評測個性化推薦演算法的精度。
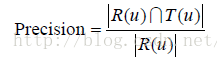
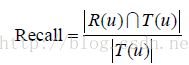
將上面的實驗進行10次,每次選擇不同的測試集,然後將每次實驗的準確率和召回率的平均值作為最終的評測結果。為了全面評測個性化推薦的效能,我們同時評測了推薦結果的覆蓋率(coverage)、多樣性(diversity)和新穎度。覆蓋率的計算公式如下:
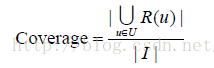
接下來我們用物品標籤向量的餘弦相似度度量物品之間的相似度。對於每個物品i,item_tags[i]儲存了物品i的標籤向量,其中item_tags[i][b]是對物品i打標籤b的次數,那麼物品i和j的餘弦相似度可以通過如下程式計算。
- #計算餘弦相似度
- def CosineSim(item_tags,i,j):
- ret = 0
- for b,wib in item_tags[i].items(): #求物品i,j的標籤交集數目
- if b in item_tags[j]:
- ret += wib * item_tags[j][b]
- ni = 0
- nj = 0
- for b, w in item_tags[i].items(): #統計 i 的標籤數目
- ni += w * w
- for b, w in item_tags[j].items(): #統計 j 的標籤數目
- nj += w * w
- if ret == 0:
- return0
- return ret/math.sqrt(ni * nj) #返回餘弦值
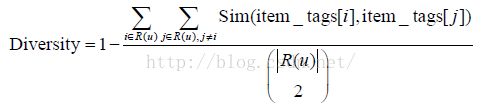
- #計算推薦列表多樣性
- def Diversity(item_tags,recommend_items):
- ret = 0
- n = 0
- for i in recommend_items.keys():
- for j in recommend_items.keys():
- if i == j:
- continue
- ret += CosineSim(item_tags,i,j)
- n += 1
- return ret/(n * 1.0)
推薦系統的多樣性為所有使用者推薦列表多樣性的平均值。
至於推薦結果的新穎性,我們簡單地用推薦結果的平均熱門程度(AveragePopularity)度量。對於物品i,定義它的流行度item_pop(i)為給這個物品打過標籤的使用者數。而對推薦系統,我們定義它的平均熱門度如下:
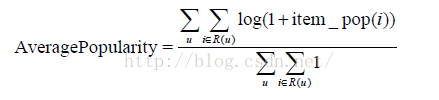
2:一個簡單的演算法
拿到了使用者標籤行為資料,相信大家都可以想到一個最簡單的個性化推薦演算法。這個演算法的
描述如下所示。
統計每個使用者最常用的標籤。
對於每個標籤,統計被打過這個標籤次數最多的物品。
對於一個使用者,首先找到他常用的標籤,然後找到具有這些標籤的最熱門物品推薦給這個使用者。
對於上面的演算法,使用者u對物品i的興趣公式如下:
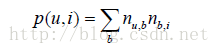
這裡,B(u)是使用者u打過的標籤集合,B(i)是物品i被打過的標籤集合,nu,b是使用者u打過標籤b的次數,nb,i是物品i被打過標籤b的次數。本章用SimpleTagBased標記這個演算法。
在Python中,我們遵循如下約定:
用 records 儲存標籤資料的三元組,其中records[i] = [user, item, tag];
用 user_tags 儲存nu,b,其中user_tags[u][b] = nu,b;
用 tag_items儲存nb,i,其中tag_items[b][i] = nb,i。
如下程式可以從records中統計出user_tags和tag_items:
- <span style="font-family:Microsoft YaHei;">#從records中統計出user_tags和tag_items
- def InitStat(records):
- user_tags = dict()
- tag_items = dict()
- user_items = dict()
- for user, item, tag in records.items():
- addValueToMat(user_tags, user, tag, 1)
- addValueToMat(tag_items, tag, item, 1)
- addValueToMat(user_items, user, item, 1)</span>
- <span style="font-family:Microsoft YaHei;">#對使用者進行個性化推薦
- def Recommend(user):
- recommend_items = dict()
- tagged_items = user_items[user]
- for tag, wut in user_tags[user].items():
- for item, wti in tag_items[tag].items():
- #if items have been tagged, do not recommend them
- if item in tagged_items:
- continue
- if item notin recommend_items:
- recommend_items[item] = wut * wti
- else:
- recommend_items[item] += wut * wti
- return recommend_items
- </span>
五:演算法的改進
再次回顧四中提出的簡單演算法
該演算法存在許多缺點,比如說對於熱門商品的處理,資料洗漱性的處理等,這也是在推薦系統中經常會遇見的問題
1:TF-IDF
前面這個公式傾向於給熱門標籤對應的熱門物品很大的權重,因此會造成推