
Hbase二級索引方案Solr key value index
概述
在Hbase中,表的RowKey 按照字典排序, Region按照RowKey設定split point進行shard,通過這種方式實現的全域性、分散式索引. 成為了其成功的最大的砝碼。
然而單一的通過RowKey檢索資料的方式,不再滿足更多的需求,查詢成為Hbase的瓶頸,人們更加希望像Sql一樣快速檢索資料,可是,Hbase之前定位的是大表的儲存,要進行這樣的查詢,往往是要通過類似Hive、Pig等系統進行全表的MapReduce計算,這種方式既浪費了機器的計算資源,又因高延遲使得應用黯然失色。於是,針對HBase Secondary Indexing的方案出現了。
Solr
Solr是一個獨立的企業級搜尋應用伺服器,是Apache Lucene專案的開源企業搜尋平臺,
其主要功能包括全文檢索、命中標示、分面搜尋、動態聚類、資料庫整合,以及富文字(如Word、PDF)的處理。Solr是高度可擴充套件的,並提供了分散式搜尋和索引複製。Solr
4還增加了NoSQL支援,以及基於Zookeeper的分散式擴充套件功能SolrCloud。SolrCloud的說明可以參看:SolrCloud分散式部署。它的主要特性包括:高效、靈活的快取功能,垂直搜尋功能,Solr是一個高效能,採用Java5開發,基於Lucene的全文搜尋伺服器。同時對其進行了擴充套件,提供了比Lucene更為豐富的查詢語言,同時實現了可配置、可擴充套件並對查詢效能進行了優化,並且提供了一個完善的功能管理介面,是一款非常優秀的
Solr可以高亮顯示搜尋結果,通過索引複製來提高可用,性,提供一套強大Data Schema來定義欄位,型別和設定文字分析,提供基於Web的管理介面等。
Key-Value Store Indexer
這個元件非常關鍵,是Hbase到Solr生成索引的中間工具。
在CDH5.3.2中的Key-Value Indexer使用的是Lily HBase NRT Indexer服務.
Lily HBase Indexer是一款靈活的、可擴充套件的、高容錯的、事務性的,並且近實時的處理HBase列索引資料的分散式服務軟體。它是NGDATA公司開發的Lily系統的一部分,已開放原始碼。Lily HBase Indexer使用SolrCloud來儲存HBase的索引資料,當HBase執行寫入、更新或刪除操作時,Indexer通過HBase的replication功能來把這些操作抽象成一系列的Event事件,並用來保證寫入Solr中的HBase索引資料的一致性。並且Indexer支援使用者自定義的抽取,轉換規則來索引HBase列資料。Solr搜尋結果會包含使用者自定義的columnfamily:qualifier欄位結果,這樣應用程式就可以直接訪問HBase的列資料。而且Indexer索引和搜尋不會影響HBase執行的穩定性和HBase資料寫入的吞吐量,因為索引和搜尋過程是完全分開並且非同步的。Lily HBase Indexer在CDH5中執行必須依賴HBase、SolrCloud和Zookeeper服務。
實時查詢方案
Hbase -----> Key Value Store ---> Solr -------> Web前端實時查詢展示
1.Hbase 提供海量資料儲存
2.Solr提供索引構建與查詢
3. Key Value Store 提供自動化索引構建(從Hbase到Solr)
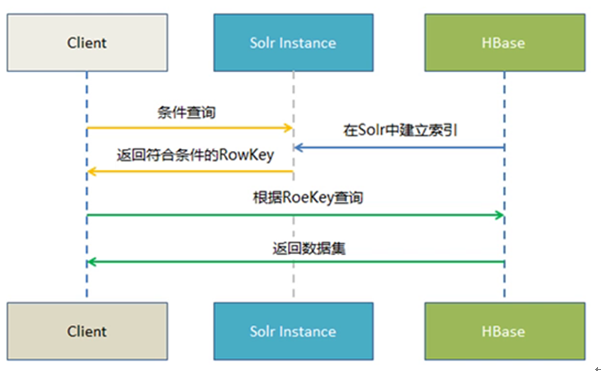
使用流程
前提: CDH5.3.2Solr叢集搭建好,CDH5.3.2 Key-Value Store Indexer叢集搭建好
1.開啟Hbase的複製功能
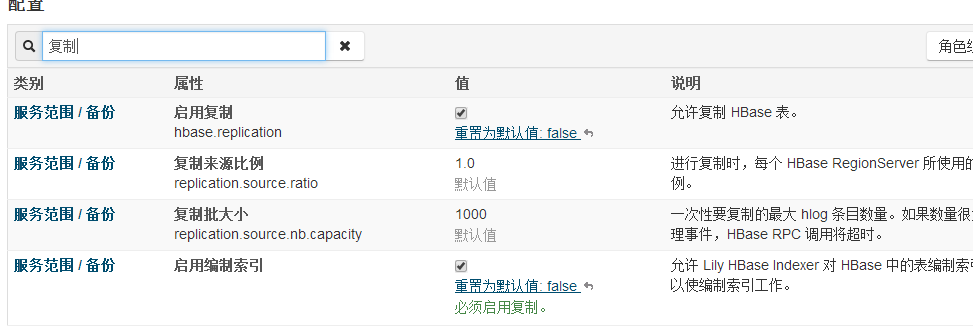
2. Hbase表需要開啟REPLICATION複製功能
|
create 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} #其中1表示開啟replication功能,0表示不開啟,預設為0 |
對於已經建立的表可以使用如下命令
|
disable 'table' alter 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} enable 'table' |
3. 生成實體配置檔案, /opt/hbase-indexer/Test是自定義路徑,可以自己設定
solrctl instancedir --generate /opt/cdhsolr/waslog
4.編輯生成好的scheme.xml檔案
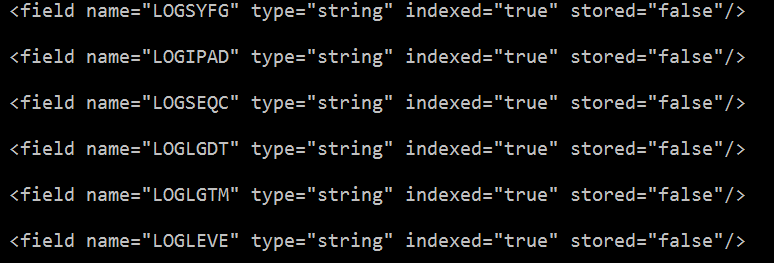
把hbase表中需要索引的列新增到scheme.xml filed節點,其中的name屬性值要與Morphline.conf檔案中的outputField屬性值對應
5.建立collection例項並配置檔案上傳到zookeeper,命令
solrctl instancedir --create waslog /opt/cdhsor/waslog


6.上傳到zookeeper之後,其他節點就可以從zookeeper下載配置檔案。接下來建立collection,命令:
solrctl collection –create waslog -s 15 –r 2 –m 50

7.建立Lily HBase Indexer配置檔案

morphline-hbase-mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<indexer table="waslog" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper">
<param name="morphlineFile" value="morphlines.conf"></param>
<param name="morphlineId" value="waslogMap"></param>
</indexer>
其中morphlineId 的value是對應Key-Value Store Indexer 中配置檔案Morphlines.conf 中morphlines 屬性id值
8.修改Morphlines 檔案, 具體操作:進入Key-Value Store Indexer面板->配置->檢視和編輯->屬性-Morphline檔案
morphlines : [ { id :waslogMap importCommands : ["org.kitesdk.**", "com.ngdata.**"] commands : [ { extractHBaseCells { mappings : [ { inputColumn : "cf:LOGSYFG" outputField : "LOGSYFG" type : string source : value }, { inputColumn : "cf:LOGIPAD" outputField : "LOGIPAD" type : string source : value }, { inputColumn : "cf:LOGSEQC" outputField : "LOGSEQC" type : string source : value }, { inputColumn : "cf:LOGLGDT" outputField : "LOGLGDT" type : string source : value }, { inputColumn : "cf:LOGLGTM" outputField : "LOGLGTM" type : string source : value } ] } } { logDebug { format : "output record: {}", args : ["@{}"] } } ] } ]
inputColumn:Hbase的CLOUMN
outputField:Solr的Schema.XML配置的fields

9.註冊Lily HBase Indexer configuration 和 Lily Hbase Indexer Service
hbase-indexer add-indexer \ --name cloudIndexer \ --indexer-conf /opt/cdhsolr/morphline-hbase-mapper.xml --connection-param solr.zk=cdh1:2181,cdh2:2181,cdh3:2181/solr \ --connection-param solr.collection=waslog \ --zookeeper cdh1:2181,cdh2:2181,cdh3:2181
驗證索引器是否成功建立
hbase-indexer list-indexers

10.測試put資料檢視結果
當寫入資料後,稍過幾秒我們可以在相對於的solr中查詢到該插入的資料,表明配置已經成功。


11.使用IK分詞器
在/opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF建立classes目錄
把IKAnalyzer.cfg.xml 和 stopword.dic新增到classes目錄
把IKAnalyzer2012FF_u1.jar新增到/opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib目錄
在Schema.xml中新增
<!--配置IK分詞器-->
<fieldType name="text_ik" class="solr.TextField">
<!--索引時候的分詞器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查詢時候的分詞器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
配置好後更新ZK配置檔案,重啟solr服務
12,擴充套件命令
Scheme.xml新增索引欄位
執行以下命令更新配置
solrctl instancedir --update waslog /opt/cdhsolr /waslog
solrctl collection --reload waslog
檢視collection命令:solrctl collection –list
Hbase表資料到SOLR叢集遷移
在CDH5.3.2中Hbase-indexer提供了MapReduce來批量構建索引的方式
/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.3.2-job.jar
構建命令
hadoop jar /opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.3.2-job.jar D 'mapreduce.reduce.shuffle.memory.limit.percent=0.06' --hbase-indexer-file /opt/cdhsolr/mapping/waslog/morphline-hbase-mapper.xml --zk-host hadoop03:2181,hadoop04:2181,hadoop05:2181/solr --collection waslog --go-live

注意:在執行命令的目錄下必須有morphlines.conf檔案

相關推薦
Hbase二級索引方案Solr key value index
概述 在Hbase中,表的RowKey 按照字典排序, Region按照RowKey設定split point進行shard,通過這種方式實現的全域性、分散式索引. 成為了其成功的最大的砝碼。 然而單一的通過RowKey檢索資料的方式,不再滿足更多的需求,查詢成為Hb
solr-hbase二級索引及查詢解決方案(一)
最近要搞一個查詢功能,是把hbase中的資料方便的查詢出來.之前根據rowkey的查詢方式,儘管有針對性設計過rowkey,有字首查詢,字尾查詢,以及正則查詢,但是實際上不夠用. 參考了網路上的設計,建立二級索引是比較好的思路.於是就以solr儲存hbase
華為hbase二級索引(secondary index)細節分析 2013-06-03 | 相關總結
華為在HBTC 2012上由其高階技術經理Anoop Sam John透露了其二級索引方案,這在業界引起極大的反響,甚至有人認為,如果華為早點公佈這個方案,hbase的某些問題早就解決了。其核心思想是保證索引表和主表在同一個region server上。 下面來對其方案做
基於Solr的Hbase二級索引
關於Hbase二級索引 HBase 是一個列存資料庫,每行資料只有一個主鍵RowKey,無法依據指定列的資料進行檢索。查詢時需要通過RowKey進行檢索,然後檢視指定列的資料是什麼,效率低下。在實際應用中,我們經常需要根據指定列進行檢索,或者幾個列進行組合檢索,這就提出
HBase協處理器同步二級索引到Solr
一、 已知的問題和不足 在上一個版本中,實現了使用HBase的協處理器將HBase的二級索引同步到Solr中,但是仍舊有幾個缺陷:寫入Solr的Collection是寫死在程式碼裡面,且是唯一的。如果我們有一張表的資料希望將不同的欄位同步到Solr中該如何做呢?目前所有
Hbase二級索引,索引海量資料實現方案
方案1:使用開源的hbase-indexer,是藉助於hbase的WAL實現,不會影響hbase效能 https://blog.csdn.net/xiahoujie_90/article/details/53400044方案2:基於ES自己實現,利用ha
hbase二級索引構建
tables required family create tab ice converts length strong 參考學習hbase源代碼中的二級索引構建代碼 IndexBuilder.java /** * * Licensed to the Apache
Hbase二級索引+CDH+Lily
1.更改表結構,允許複製 已存在的表 disable 'tableName' alter 'tableName',{NAME =>'fn', REPLICATION_SCOPE =>1} enable 'tableName' 不存在的表 create ‘table‘,{N
Hindex--華為Hbase二級索引
華為在HBTC 2012上由其高階技術經理Anoop Sam John透露了其二級索引方案,這在業界引起極大的反響,甚至 有人認為,如果華為早點公佈這個方案,hbase的某些問題早就解決了。其核心思想是保證索引表和主表在同一個 region server上。 更新:目前該方
CDH key value index lily安裝配置
Key-Value Store Indexer 這個元件非常關鍵,是Hbase到Solr生成索引的中間工具。 Lily HBase Indexer是一款靈活的、可擴充套件的、高容錯的、事務性的,並且近實時的處理HBase列索引資料的分散式服務軟體。它是NGDATA公
HBase之——MapReduce構建HBase二級索引
import java.io.IOException; import java.util.HashMap; import java.util.Map; import java.util.Set; import org.apache.hadoop.conf.Configur
利用Solr建立HBase的二級索引
public void insertSolr(Put put) { CloudSolrServer cloudSolrServer; final String zkHost = "IP:2181,IP:2181,IP:2181"; final int zkConnectTimeout = 1;
使用HBase Indexer建立二級索引(整合最新版本的HBase1.2.6及Solr 7.2.1)
這段時間整合HBase,需要為HBase建立二級索引,方便資料的查詢使用,Solr權威指南上面有Hbase與Solr的整合章節,照著書上以及網上的說明折騰了很近才配置成功,HBase Indexer已經有1年多沒有更新了,整合最新的HBase1.2.6,solr7.2.1有
CDH HBASE使用solr建立二級索引,更新刪除索引
關於為什麼要建立hbase二級索引,這裡不再贅述,直接開始安裝配置 1.環境準備 ①安裝HBASE,solr,Key-Value Store Indexer,這些在CDH
HBase建立二級索引的一些解決方式
ack sca for done pseudo 100% hide shm range HBase的一級索引就是rowkey,我們僅僅能通過rowkey進行檢索。假設我們相對hbase裏面列族的列列進行一些組合查詢。就須要採用HBase的二級索引方案來進
HBase的二級索引
strong clean 查詢 問題 mvn clean 流程 zxvf oop sem HBase的二級索引,以及phoenix的安裝(需再做一次) 一:HBase的二級索引 1.講解 uid+ts 11111_20161126111111:查詢某一u
[Phoenix基礎]-- 二級索引應該使用local Index還是global Index?
版本:phoenix 4.12.0 說明: 1、一個global index表對應著一個hbase 表,local index是在主表上新增一列儲存索引資料。 2、適用場景 global index :適用於多讀的場景,但是存在同步索引時帶來網路開銷較大的問題。 local
hbase協處理器與二級索引
一、協處理器—Coprocessor 1、 起源 Hbase 作為列族資料庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執 行求和、計數、排序等操作。比如,在舊版本的(<0.92)Hbase 中,統計資料表的總行數,需 要使用 Counte
HBase利用observer(協處理器)建立二級索引
一、協處理器—Coprocessor 1、 起源 Hbase 作為列族資料庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執 行求和、計數、排序等操作。比如,在舊版本的(<0.92)Hbase 中,統
mysql 建立、刪除 索引 key 、primary key 、unique key 與index區別
建立:creta index test_suoying(索引的欄位名) on 表名; 刪除:drop index index_name on table_name ; 一、key與primary key區別CREATE TABLE wh_logrecord ( logre