
Hadoop分散式叢集環境搭建(三節點)
一、安裝準備
- 建立hadoop賬號
- 更改ip
安裝Java 更改/etc/profile 配置環境變數
export $JAVA_HOME=/usr/java/jdk1.7.0_71修改host檔案域名
172.16.133.149 hadoop101 172.16.133.150 hadoop102 172.16.133.151 hadoop103- 安裝ssh 配置無密碼登入
解壓hadoop
/hadoop/hadoop-2.6.2
二、修改conf下面的配置檔案
依次修改hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves檔案。
1.hadoop-env.sh
`#新增JAVA_HOME:`
`export JAVA_HOME=/usr/java/jdk1.7.0_71`
2.core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.6.2/hdfs/tmp</value>
</property>
<property>
<name> 3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property 4.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6.slaves
hadoop102
hadoop103
7.最後,將整個hadoop-2.6.2資料夾及其子資料夾使用scp複製到兩臺Slave(hadoop102、hadoop103)的相同目錄中:
scp -r \hadoop\hadoop-2.6.2\ [email protected]:\hadoop\
scp -r \hadoop\hadoop-2.6.2\ [email protected]:\hadoop\
三、啟動執行Hadoop(進入hadoop資料夾下)
格式化NameNode
dfs namenode -format啟動Namenode、SecondaryNameNode和DataNode
[[email protected]]$ start-dfs.sh啟動ResourceManager和NodeManager
[[email protected]]$ start-yarn.sh最終執行結果
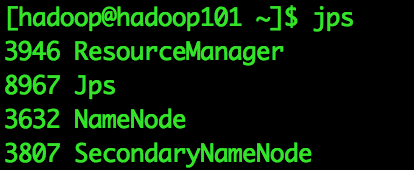
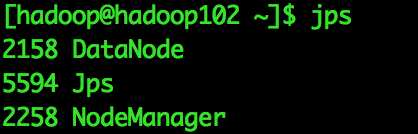
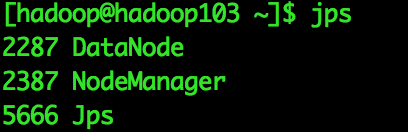
四、測試Hadoop
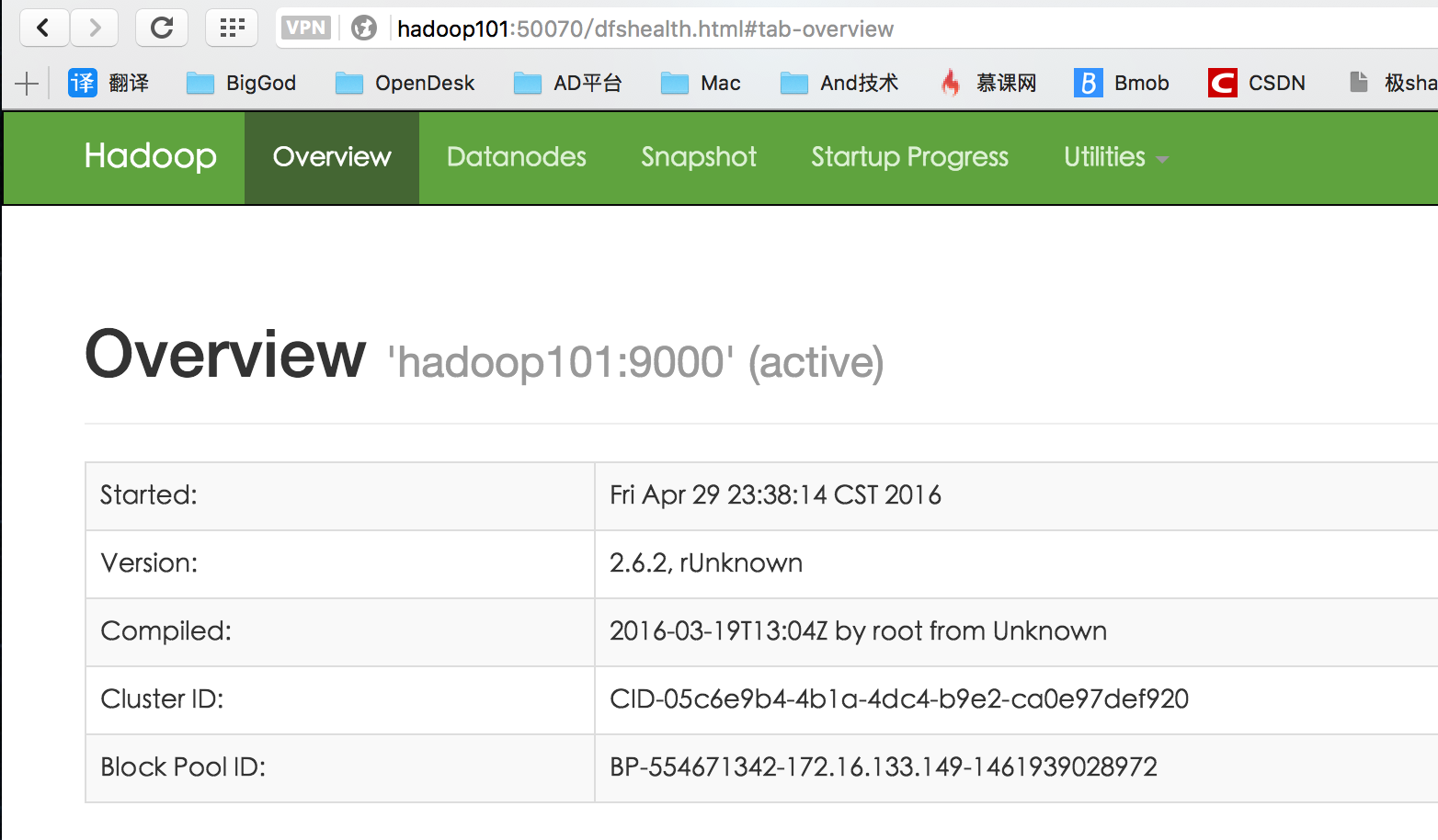
測試HDFS
瀏覽器輸入http://<-NameNode主機名或IP->:50070
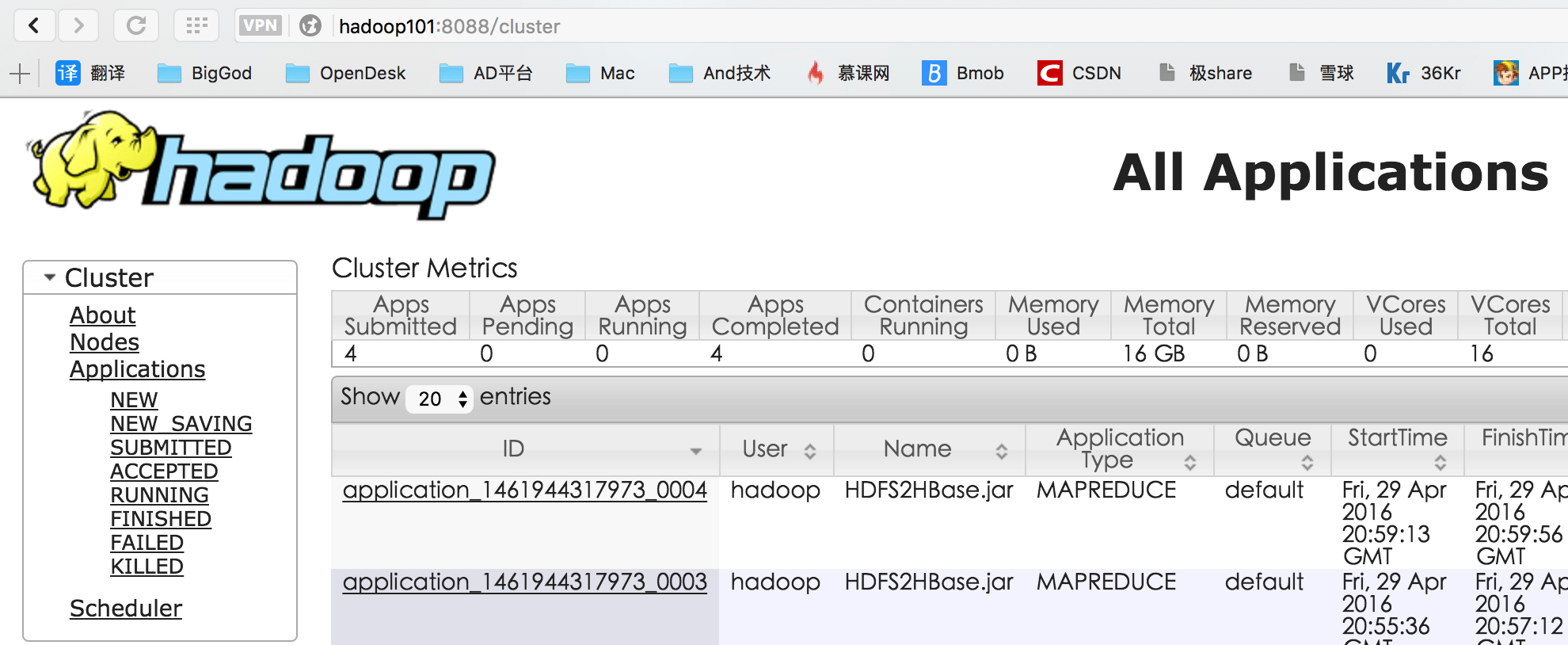
測試ResourceManager
瀏覽器輸入http://<-ResourceManager所在主機名或IP->:8088
相關推薦
Hadoop分散式叢集環境搭建(三節點)
一、安裝準備 建立hadoop賬號 更改ip 安裝Java 更改/etc/profile 配置環境變數 export $JAVA_HOME=/usr/java/jdk1.7.0_71 修改host檔案域名 172.16.133.149 hadoop101
大資料Hadoop叢集環境搭建(三)
在配置hadoop環境中 一、修改Hostname 1. 臨時修改hostname [[email protected] localhost]# hostname hadoop 這種修改方式,系統重啟後就會失效。 2、 永久修改hostname 想永久修改,應
從零開始搭建hadoop分散式叢集環境:(一)新建hadoop使用者以及使用者組
搭建hadoop叢集環境不僅master和slaves安裝的hadoop路徑要完全一樣,也要求使用者和組也要完全一致。因此第一步就是新建使用者以及使用者組。對於新手來言,新建使用者使用者組,並賦予適當的許可權無疑是最大的問題。下面請跟隨我來新建使用者以及使用者組
hadoop分散式叢集環境搭建
參考 http://www.cnblogs.com/zhijianliutang/p/5736103.html 1 wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2
Hadoop+spark+jupyter環境搭建(三):Pyspark+jupyter部署在Linux
Hadoop+spark+jupyter環境搭建順序請參照: 我們已經實現了Spark on Yarn的搭建,但我們還希望有一個友好的開發介面,也便於展示成果,因此我們選擇了jupyter。他的本質就是一個 web app,也支援多種語言,完全滿足我們的要求。1.安裝
zookeeper叢集環境搭建(純zookeeper)
1.首先在三臺機子上放上zookeeper的解壓包,解壓。 然後的話zookeeper是依賴於jdk的,那麼也應該安裝jdk,這裡不詳細說明了。 mv zookeeper-3.4.5 zookeeper 修改節點為zookeeper
Windows_2008_R2+SQL_2008R2 叢集環境搭建(VMware平臺)
一.基礎環境 測試環境IP分配: 主機 主機名 Ip地址 host1 ESXi-31 192.168.120.242 host2 ESXi-32 192.168.120.243 VC vCen
HDFS環境搭建(單節點配置) hadoop叢集搭建(hdfs)
【參考文章】:hadoop叢集搭建(hdfs) 1. Hadoop下載 官網下載地址: https://hadoop.apache.org/releases.html,進入官網根據自己需要下載具體的安裝包 清華大學安裝包的映象檔案下載地址: https://mirrors.tuna.
阿里雲ECS伺服器部署HADOOP叢集(一):Hadoop完全分散式叢集環境搭建
準備: 兩臺配置CentOS 7.3的阿里雲ECS伺服器; hadoop-2.7.3.tar.gz安裝包; jdk-8u77-linux-x64.tar.gz安裝包; hostname及IP的配置: 更改主機名: 由於系統為CentOS 7,可以直接使用‘hostnamectl set-hostname 主機
centos7.3中搭建hadoop分散式叢集環境詳細過程
一、準備工作 1、準備3臺物理機或者虛擬機器; 2、安裝centos7系統; 3、準備好相關軟體包並拷貝相關軟體到目標伺服器上 hadoop-2.9.0.tar.gz jdk-8u131-linux-x64.tar.gz 二、配置網路 1、設定靜態網路ip 1)設定靜
Hadoop叢集環境搭建(雲伺服器,虛擬機器都適用)
為了配置方便,為每臺電腦配置一個主機名: vim /etc/hostname 各個節點中,主節點寫入:master , 其他從節點寫入:slavexx 如果這樣修改不能生效,則繼續如下操作 vim /etc/cloud/cloud.cfg 做preserve_hostname: true 修改 reb
hadoop叢集環境搭建之偽分散式叢集環境搭建
搭建叢集的模式有三種 1.偽分散式:在一臺伺服器上,啟動多個執行緒分別代表多個角色(因為角色在叢集中使用程序表現的) 2.完全分散式:在多臺伺服器上,每臺伺服器啟動不同角色的程序,多臺伺服器構成叢集 node01:NameNode node02:
Hadoop最完整分散式叢集環境搭建
分散式環境搭建之環境介紹 之前我們已經介紹瞭如何在單機上搭建偽分散式的Hadoop環境,而在實際情況中,肯定都是多機器多節點的分散式叢集環境,所以本文將簡單介紹一下如何在多臺機器上搭建Hadoop的分散式環境。 我這裡準備了三臺機器,IP地址如下: 192.16
大資料平臺Hadoop的分散式叢集環境搭建,官網推薦
1 概述 本文章介紹大資料平臺Hadoop的分散式環境搭建、以下為Hadoop節點的部署圖,將NameNode部署在master1,SecondaryNameNode部署在master2,slave1、slave2、slave3中分別部署一個DataNode節點 NN
Hadoop叢集化搭建(三)配置SSH互信
軟體環境 作業系統 CentOS 6.4 64bit (Basic Server + 桌面環境) 虛擬機器 VMware Workstation 12.0
基於Hadoop生態圈的資料倉庫實踐 —— 環境搭建(三)
三、建立資料倉庫示例模型 Hadoop及其相關服務安裝配置好後,下面用一個小而完整的示例說明多維模型及其相關ETL技術在Hadoop上的具體實現。1. 設計ERD 操作型系統是一個銷售訂單系統,初始時只有產品、客戶、訂單三個表,ERD如下圖所示。
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的叢集搭建(單節點)(Ubuntu系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的叢集搭建(單節點)(CentOS系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言
hadoop-2.6.0.tar.gz的叢集搭建(3節點)(不含zookeeper叢集安裝)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython或s
大資料Hadoop叢集環境搭建(五)
Hadoop環境搭建Hadoop本地模式安裝 Hadoop部署模式 Hadoop部署模式有:本地模式、偽分佈模式、完全分散式模式。 區分的依據是NameNode、DataNode、ResourceManager、NodeManager等模組執行在幾個JVM程序、幾個機器。 一、本地模