
《大資料時代》讀書筆記
大資料開啟了一次重大的時代轉型。就像望遠鏡讓我們能夠感受宇宙,顯微鏡讓我們能夠 觀測微生物一樣,大資料正在改變我們的生活以及理解世界的方式,成為新發明和新服務的源 泉,而更多的改變正蓄勢待發……
大資料的精髓在於我們分析資訊時的三個轉變,這些轉變將改變我們理解和組建社會的方法。
第一個轉變就是,在大資料時代,我們可以分析更多的資料,有時候甚至可以處理和第一個轉變就是,在大資料時代,我們可以分析更多的資料,有時候甚至可以處理和 某個特別現象相關的所有資料,而不再依賴於隨機取樣。 某個特別現象相關的所有資料,而不再依賴於隨機取樣。“樣本=總體”
例如:從未來的審計視角來看,上市公司應該賦予審計師更大的訪問許可權,不再侷限於交易樣本,而是擴充套件至全部的總分類賬和資料庫
第二個改變就是,研究資料如此之多,以至於我們不再熱衷於追求精確度。 第二個改變就是,研究資料如此之多,以至於我們不再熱衷於追求精確度。
第三個轉變因前兩個轉變而促成,即我們不再熱衷於尋找因果關係,而應該尋找事物之間的相關關係。
讀書到這裡,忽然想到應該看政府部門對大資料時代的意見:
《國務院關於印發促進大資料發展行動綱要的通知》說到主要任務[2] :
(一)加快政府資料開放共享,推動資源整合,提升治理能力。
……
6.形成大資料產品體系。圍繞資料採集、整理、分析、發掘、展現、應用等環節,支援大型通用海量資料儲存與管理軟體、大資料分析發掘軟體、資料視覺化軟體等軟體產品和海量資料儲存裝置、大資料一體機等硬體產品發展,帶動晶片、作業系統等資訊科技核心基礎產品發展,打造較為健全的大資料產品體系。大力發展與重點行業領域業務流程及資料應用需求深度融合的大資料解決方案。
7.完善大資料產業鏈。
(三)強化安全保障,提高管理水平,促進健康發展。
大資料時代的思維變革
數字化帶來了資料化,但是數字化無法取代資料化。數字化是把模擬資料變成計算機可讀的資料,和資料化有本質上的不同。
讓資料發聲
小資料的隨機取樣,最少的資料獲得最多的資訊 。取樣分析的精確性隨著取樣隨機性的增加而大幅提高,但與樣本數量取樣分析的精確性隨著取樣隨機性的增加而大幅提高,但與樣本數量 的增加關係不大。的增加關係不大。
大資料是指不用隨機分析法這樣的捷徑,而大資料是指不用隨機分析法這樣的捷徑,而採用所有資料的方法。
允許不精確
不是大量資料優於少量資料那麼簡單了,而是大量資料創造了更好的結果。
大資料基礎上的簡單演算法比小資料基礎上的複雜演算法更加有效。
大資料不僅讓我們不再期待精確性,也讓我們無法實現精確性。 大資料不僅讓我們不再期待精確性,也讓我們無法實現精確性。
例如:麻省理工與通貨緊縮預測軟體。
麻省理工學院(MIT)的兩位經濟學家,阿爾貝託·卡瓦略(Alberto Cavell)和羅伯託·裡哥本(Oberto Rigobon)就對此提出了一個大資料方案,那就是接受更混亂的資料。通過一個軟體在網際網路上收集資訊,他們每天可以收集到50萬種商品的價格。收集到的資料很混亂,也不是 所有資料都能輕易進行比較。但是把大資料和好的分析法相結合,這個專案在2008年9月雷曼兄弟破產之後馬上就發現了通貨緊縮趨勢,然而那些依賴官方資料的人直到11月份才知道這個情況。
值得注意的是,錯誤性並不是大資料本身固有的。它只是我們用來測量、記錄和交流資料 的工具的一個缺陷。如果說哪天技術變得完美無缺了,不精確的問題也就不復存在了。錯誤並不是大資料固有的特性,而是一個亟需我們去處理的現實問題,並且有可能長期存在。
紛繁的資料越多越好
傳統的商業職能,“一個唯一的真理”這種想法已經徹底被改變了。現在不但出現了一種新的認識, 即“一個唯一的真理”的存在是不可能的,而且追求這個唯一的真理是對注意力的分散。要想獲得大規模資料帶來的好處,混亂應該是一種標準途徑,而不應該是竭力避免的。
例如:在某個記錄手機號碼的域中輸入一串漢字。傳統的關係資料庫是為資料稀缺的時代設計的,所以能夠也需要仔細策劃。在那個時代,人們遇到的問題無比清晰,所以資料庫被設計用來有 效地回答這些問題。
據估計,只有5%的數字資料是結構化的且能適用於傳統資料庫。如果不接受混亂,剩下95%的非結構化資料都無法被利用,比如網頁和視訊資源。通過接受不精確性,我們打開了一 個從未涉足的世界的窗戶。
不是因果關係,而是相關關係
亞馬遜的推薦系統梳理出了有趣的相關關係,但不知道背後的原因。知道是什麼就夠了,沒必要知道為什麼。
相關關係的核心是量化兩個資料值之間的數理關係。相關關係強是指當一個數據值增加時,另一個數據值很有可能也會隨之增加。我們已經看到過這種很強的相關關係,比如谷歌流感趨勢:在一個特定的地理位置,越多的人通過谷歌搜尋特定的詞條,該地區就有更多的人患 了流感。
相關關係通過識別有用的關聯物來幫助我們分析一個現象,而不是通過揭示其內部的運作機制。
例如:流程優化後的資料,營業銷售套餐銷售額、利潤的變化…
中醫、西醫的對比,就是相關性、允許不精確的體現。
在哲學界,因果關係是否存在,因果關係與自由意思相對立。
快速思維模式,用因果關係看待周圍世界;
父母經常告訴孩子,天冷時不戴帽子和手套就會感冒。然而,事實上,感冒和穿戴之間卻沒有直接的聯絡。有時,我們在某個餐館用餐後生病了的話,我們就會自然而然地覺得這是餐館食物的問題,以後可能就E4��再去這家餐館了。事實上,我們肚子痛也許是因為其他的傳染途徑,比如和患者握過手之類的。然而,我們的快速思維模式使我們直接將其歸於任何我們能在第一時間想起來的因果關係,因此,這經常導致我們做出錯誤的決定。
與常識相反,經常憑藉直覺而來的因果關係並沒有幫助我們加深對這個世界的理解。很多時候,這種認知捷徑只是給了我們一種自己已經理解的錯覺,但實際上,我們因此完全陷入了理解誤區之中。就像取樣是我們無法處理全部資料時的捷徑一樣,這種找因果關係的方法也是我們大腦用來避免辛苦思考的捷徑。
慢性思維模式
即使是我們用 來發現因果關係的第二種思維方式——慢性思維,也將因為大資料之間的相關關係迎來大的改變。
相關關係分析本身意義重大,同時它也為研究因果關係奠定了基礎。通過找出可能相關的 事物,我們可以在此基礎上進行進一步的因果關係分析,如果存在因果關係的話,我們再進一 步找出原因。這種便捷的機制通過嚴格的實驗降低了因果分析的成本。我們也可以從相互聯絡 中找到一些重要的變數,這些變數可以用到驗證因果關係的實驗中去。
大資料時代的商業變革
資料化:一切皆可“量化”
量化一切,資料化的核心。計量和記錄一起促成了資料的誕生,它們是資料化最早的根基。
複式記賬法通常被看成是會計業和金融業不斷髮展的成果。事實上,在資料利用的推進過程中,它也是一個里程碑似的存在。它的出現實現了相關賬戶資訊的“分門別類”記錄。 它建立在一系列記錄資料的規則之上,也是最早的資訊記錄標準化的例子,使得會計們能夠讀 懂彼此的賬本。複式記賬法可以使查詢每個賬戶的盈虧情況變得簡單容易。它會提供交易的記 賬線索,這樣就更容易找到需要的資料。它的設計理念中包含了“糾錯”的思想,這也是今天的 技術人才們應該學習的。
資料化內容:
| 資料化內容 | 大資料先鋒 |
|---|---|
| 文字變成資料 | 谷歌的數字圖書館 |
| 方位變成資料 | 多效地理定位與UPS的最佳行車路徑 |
| 溝通變成資料 | 微博關聯與疫苗接種 |
有了大資料的幫助,我們不會再將世界看作 有了大資料的幫助,我們不會再將世界看作 是一連串我們認為或是自然或是社會現象的事件,我們會意識到本質上世界是由資訊構成 是一連串我們認為或是自然或是社會現象的事件,我們會意識到本質上世界是由資訊構成 的。
將世界看作資訊,看作可以理解的資料的海洋,為我們提供了一個從未有過的審視現 將世界看作資訊,看作可以理解的資料的海洋,為我們提供了一個從未有過的審視現 實的視角。它是一種可以滲透到所有生活領域的世界觀。
價值:“取之不盡,用之不竭”的資料創新
| 資料創新 | 案例 |
|---|---|
| 1:資料的再利用 | 移動運營商與資料再利用 |
| 2:重組資料 | 丹麥癌症協會:手機是否增加致癌率 |
| 3:可擴充套件資料 | 谷歌街景與GPS採集 |
| 4:資料的折舊值 | |
| 5:資料廢氣 | 微軟與谷歌的拼寫檢查 |
| 6:開放資料 | FlyOnTime的航班時間預測 |
其中,資料廢氣和開發資料需要重新認識:
資料廢氣是許多電腦化服務背後的機制,如語音識別、垃圾郵件過濾、翻譯等。當用戶指 出語音識別程式誤解了他們的意思時,他們實際上有效地“訓練”了這個系統,讓它變得更好。
很多企業都開始設計他們的系統,以這種方式收集和使用資訊。
例如:大資料在業務流程系統上的應用:
流程流轉資料、待辦處理資料、訪問操作日誌;
如果沒有訪問操作日誌,可以從Apache HTTP日誌中獲取,每次的URL。
BPM做為粘合劑,將為大資料收集資料、整理資料提供便捷的方法,也為大資料分析提供了一個緯度。[3]
政府才是大規模資訊的原始採集者,並且還在與私營企業競爭他們所控制的大量資料。讓“開放政府資料”的倡議響徹全球。
注意觀察:冠名政府的大資料資產管理公司,將如雨後春筍般的冒出來。
資料價值的關鍵是看似無限的再利用,即它的潛在價值。收集資訊固然至關重要,但還遠 遠不夠,因為大部分的資料價值在於它的使用,而不是佔有本身。
角色定位:資料、技術與思維的三足鼎立
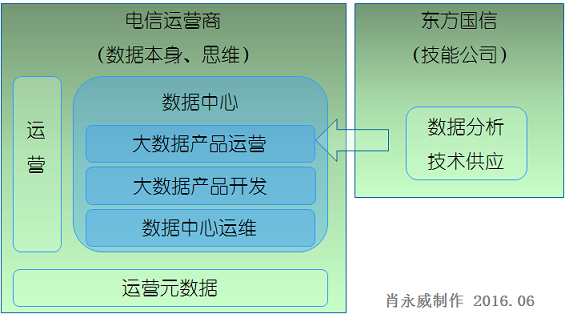
根據所提供價值的不同來源,分別出現了三種大資料公司。這三種來源是指:資料本身、 技能與思維。
第一種是基於資料本身的公司。 第一種是基於資料本身的公司。這些公司擁有大量資料或者至少可以收集到大量資料,卻 不一定有從資料中提取價值或者用資料催生創新思想的技能。最好的例子就是Twitter,它擁有 海量資料這一點是毫無疑問的,但是它的資料都通過兩個獨立的公司授權給別人使用。
第二種是基於技能的公司。 第二種是基於技能的公司。它們通常是諮詢公司、技術供應商或者分析公司。它們掌握了 專業技能但並不一定擁有資料或提出資料創新性用途的才能。比方說,沃爾瑪和Pop-Tarts這兩 個零售商就是藉助天睿公司(Teradata)的分析來獲得營銷點子,天睿就是一家大資料分析公 司。
第三種是基於思維的公司。 第三種是基於思維的公司。皮特·華登(Pete Warden),Jetpac的聯合創始人,就是通過想 法獲得價值的一個例子。Jetpac通過使用者分享到網上的旅行照片來為人們推薦下次旅行的目的 地。對於某些公司來說,資料和技能並不是成功的關鍵。讓這些公司脫穎而出的是其創始人和 員工的創新思維,他們有怎樣挖掘資料的新價值的獨特想法。
結合實際工作,典型專業化大資料運營公司案例如圖所示。
大資料時代的管理變革
風險:讓資料主宰一切的隱憂 ,無處不在的“第三隻眼”,謹防資料獨裁。
大資料大大地威脅到了我們的隱私和自由,這都是大資料帶來的新威脅。但是與此同時, 它也加劇了一箇舊威脅:過於依賴資料,而資料遠遠沒有我們所想的那麼可靠。
美國軍方在越戰時對資料的使用、濫用和誤用給我們提了一個醒,在由“小資料”時代向大 資料時代轉變的過程中,我們對資訊的一些侷限性必須給予高度的重視。資料的質量可能會很 差;可能是不客觀的;可能存在分析錯誤或者具有誤導性;更糟糕的是,資料可能根本達不到 量化它的目的。
責任與自由並舉的資訊管理,
一場管理規範的變革
我們在生產和資訊交流方式上的變革必然會引發自我管理所用規範的變革。同時,這些變革也會帶動社會需要維護的核心價值觀的轉變。
可是,變革並不止於規範。大資料時代,對原有規範的修修補補已經滿足不了需要,也不足以抑制大資料帶來的風險 ——我們需要全新的制度規範。
將責任從民眾轉移到資料使用者很有意義,也存在充分的理由,因為資料使用者比任何人 都明白他們想要如何利用資料。除了管理上的轉變,即從個人許可到資料使用者承擔相應責任的轉變,我們也需要發明並推行新技術方式來促進隱私保護。一個創新途徑就是“差別隱私”:故意將資料模糊處理,促使 對大資料庫的查詢不能顯示精確的結果,而只有相近的結果。
在自由與隱私的範疇裡,還需要大資料審計和大資料監督。
這一切都意味著,一個員工是否對公司有貢獻的判斷標準改變了。這也就意味著,你要學的東西、你要了解的人,你要為你的 職業生涯所做的準備都改變了。
大資料時代,名副其實的“資訊社會”。
相關推薦
實戰大資料(讀書筆記)
與線下實體經營輕易對接 1、將電子券傳送到手機上,使用者可以直接拿著手機去消費 2、利用手機上的位置定位功能,公司推出“簽到”服務,可以直接把手機使用者帶到企業活動地點 精準的位置服務 1、移動終端可以隨時隨地為消費者收集、分析資料,讓消費者與身邊的人更好地互
《大資料時代》讀書筆記
大資料開啟了一次重大的時代轉型。就像望遠鏡讓我們能夠感受宇宙,顯微鏡讓我們能夠 觀測微生物一樣,大資料正在改變我們的生活以及理解世界的方式,成為新發明和新服務的源 泉,而更多的改變正蓄勢待發…… 大資料的精髓在於我們分析資訊時的三個轉變,這些轉變將改變
《大資料時代》讀書筆記——知道“是什麼”就夠了,沒必要知道“為什麼”。我們不必非得知道現象背後的原因,而是要讓資料自己“發聲”
引言——一場生活、工作與思維的大變革 今天,一種可能的方式,亦是本書採取的方式,認為大資料是人們在大規模資料的基礎上可以做到的事情,而這些事情在小規模資料的基礎上是無法完成的。大資料是人們獲得新的認知、創造新的價值的源泉;大資料還為改變市場、組織機構,以及政府與公民關係
《大資料時代:生活、工作與思維的大變革》讀書筆記
1、 大資料與雲端計算是一個問題的兩面:一個是問題,一個是解決問題的方法。通過雲端計算對大資料進行分析、預測,會是的決策更為精準,釋放出更多資料的隱藏價值。資料,這個21世紀人類探索的新邊疆,正在被雲計算髮現、征服。 2、 人類儲存資訊量的增
《大資料時代:生活、工作與思維的大變革》讀書筆記
引言 1、 大資料與雲端計算是一個問題的兩面:一個是問題,一個是解決問題的方法。通過雲端計算對大資料進行分析、預測,會是的決策更為精準,釋放出更多資料的隱藏價值。資料,這個21世紀人類探索的新邊疆,正在被雲計算髮現、征服。 2、 人類儲存資訊量
《爆發·大資料時代預見未來的新思維》筆記與心得
馬克·吐溫曾說過: 歷史不會重演,卻自有其韻律 雖然萬事皆顯出自發偶然之態,但實際上它遠比你想象中容易預測。 在日常生活中,雖然我們可以針對某些事情自由做決定,但似乎人生的大部分時光還是 處於“無
《爆發·大資料時代預見未來的新思維》筆記與心得(一)
馬克·吐溫曾說過: 歷史不會重演,卻自有其韻律 雖然萬事皆顯出自發偶然之態,但實際上它遠比你想象中容易預測。 在日常生活中,雖然我們可以針對某些事情自由做決定,但似乎人生的大部分時光還是 處於“無
《大資料時代生活、工作與思維的大變革》閱讀筆記
引言 1、大資料如何變革公共衛生 例子,甲型h1n1流感谷歌通過分析人們的搜尋記錄來判斷這些人是否患上了流感。其他公司做不到的原因:缺乏像谷歌公司一樣龐大的資料資源、處理能力和統計技術。 2、大資料如何變革商業領域 例子,預測當前的機票價格在未來一段時間內會上漲還是下降——
大資料時代,如何提升格局
大資料時代,格局非常重要,想學習大資料技術的小夥伴,一定要認真閱讀此文 其實大資料時代的人才只分為三種:做事的人、做式的人、做局的人。 道生一,一生二,二生三,三生萬物。這三種人,組建起了一個龐大的社會體系。 先看做事的人。 把一件事情最好是一個人的基本能力,它遵循的是“事道”,講究
資料脫敏平臺-大資料時代的隱私保護利器
什麼是資料脫敏 又稱資料漂白、資料去隱私化或資料變形。是對核心業務資料中敏感的資訊,進行變形、轉換、混淆,使得對業務資料中的身份、組織等隱私敏感資訊進行去除或掩蓋,以保護資料能被合理、安全地利用。 ◆ ◆ ◆ 資料脫敏的重要性 1)敏
大資料時代,IT行業的熱門崗位有哪些?
雲端計算、大資料、BYOD、社交媒體、3D印表機、物聯網……在網際網路時代,各種新詞層出不窮,令人應接不暇。這些新的技術、新興應用和對應的IT發展趨勢,使得IT人必須瞭解甚至掌握最新的IT技能。 另一方面,雲端計算和大資料乃至其他助推各個行業發展的IT基礎設施的新一輪部署與運維,都將帶來更多的I
大資料Hadoop學習筆記(三)
1.HDFS架構講解 2.NameNode啟動過程 3.YARN架構組建功能詳解 4.MapReduce 程式設計模型 HDFS架構講解 源自谷歌的GFS論文 HDFS: *抑鬱擴充套件的分散式系統 *執行在大量普通的鏈家機器上,提供容錯機制 *為
大資料Hadoop學習筆記(二)
Single Node Setup 官網地址 1. 本地模式 2.偽分散式模式 ************************* 本地模式 **************************** . grep input output ‘dfs[a-
大資料Hadoop學習筆記(一)
大資料Hadoop2.x hadoop用來分析儲存網路資料 MapReduce:對海量資料的處理、分散式。 思想————> 分而治之,大資料集分為小的資料集,每個資料集進行邏輯業務處理合並統計資料結果(reduce) 執行模式:本地模式和yarn模式 input—
大資料Hadoop學習筆記(五)
分散式部署 本地模式Local Mode 分散式Distribute Mode 偽分散式 一臺機器執行所有的守護程序 從節點DN和NM只有一個 完全分散式
大資料Hadoop學習筆記(四)
MapReduce執行過程 ======== step1 : input InputFormat 讀取資料 轉換成<key, value>
大資料Hadoop學習筆記(六)
HDFS HA 背景: 在hadoop2.0之前,HDFS叢集中的NameNode存在單點故障(SPOF)對於只有一個NameNode的叢集,若NameNode機器出現故障,則整個叢集將無法使用,直到NameNode重新啟動 NameNode主要在一下兩方面影響
大資料入門學習筆記(叄)- 布式檔案系統HDFS
文章目錄 HDFS概述及設計目標 什麼是HDFS HDFS的設計目標 HDFS架構 HDFS副本機制 副本存放策略
大資料分析學習筆記(Z檢驗,分類器以及Association Rule) Task 1 – Hypothesis Testing To improve student learning performance, a teacher developed two new learning app
大資料入門學習筆記(貳)- 初識Hadoop
文章目錄 Hadoop概述 Hadoop能做什麼 Hadoop核心元件 分散式檔案系統HDFS 分散式檔案系統HDDS 資源排程系統YARN 分散式計算框架MapReduce Had