
演算法課堂實驗報告(五)——python回溯法與分支限界法(旅行商TSP問題)
python實現回溯法與分支限界
一、開發環境
開發工具:jupyter notebook 並使用vscode,cmd命令列工具協助程式設計測試演算法,並使用codeblocks輔助編寫C++程式
程式語言:python3.6
二、實驗目標
1. 請用回溯法求對稱的旅行商問題(TSP問題)
2. 請用分支限界法求對稱的旅行商問題(TSP問題)
三、實驗內容
旅行商問題的簡單說明:
旅行商問題(TSP問題)是一個經典的組合優化問題。經典TSP問題可以描述為:一個商品推銷員要去若干個城市推銷商品,該推銷員從一個城市出發,需要經過所有城市後,回到出發地。應如何選擇行進路線,以使總的行程最短
從圖論角度看:
該問題實質是在一個帶權完全無向圖中,找一個權值最小的Hamilton迴路。由於該問題的可行解是所有頂點的全排列,隨著頂點數的增加,會產生組合爆炸,它是一個NP完全問題。
TSP的數學模型為:


使用的測試資料:

使用字典的形式表示:
# 定義圖的字典形式
G = {
'1': {'2': 30, '3': 6, '4': 4},
'2': {'1': 30, '3': 5, '4': 10},
'3': {'1': 6, '2': 5, '4': 20},
'4': {'1': 4, '2': 10, '3': 20}
}
使用資料的形式表示:
# 定義圖的陣列形式
graph = [
[0, 30, 6, 4],
[30, 0, 5, 10],
[6, 5, 0 , 20],
[4, 10, 20, 0]
]
(一)使用回溯法求解旅行商(TSP)問題
回溯法的概念:
回溯演算法實際上一個類似列舉的搜尋嘗試過程,主要是在搜尋嘗試過程中尋找問題的解,當發現已不滿足求解條件時,就“回溯”返回,嘗試別的路徑。
回溯法是一種選優搜尋法,按選優條件向前搜尋,以達到目標。但當探索到某一步時,發現原先選擇並不優或達不到目標,就退回一步重新選擇,這種走不通就退回再走的技術為回溯法,而滿足回溯條件的某個狀態的點稱為“回溯點”。
許多複雜的,規模較大的問題都可以使用回溯法,有“通用解題方法”的美稱。
在我看來,回溯法有點像圖遍歷中的深度優先演算法,不過多了剪枝這一過程,當發現現有的解的值大於最優解的時候,就不再深入遍歷下去,演算法的效能取決於剪枝的多少。
下面給出回溯法的程式碼:
# 回溯法求解旅行商問題
import math
n = 4
x = [0, 1, 2, 3]
# 定義圖的字典形式
G = {
'1': {'2': 30, '3': 6, '4': 4},
'2': {'1': 30, '3': 5, '4': 10},
'3': {'1': 6, '2': 5, '4': 20},
'4': {'1': 4, '2': 10, '3': 20}
}
# 定義圖的陣列形式
graph = [
[0, 30, 6, 4],
[30, 0, 5, 10],
[6, 5, 0 , 20],
[4, 10, 20, 0]
]
bestway = ''
# bestcost = 1<<32 # 這裡只要是一個很大數就行了 無窮其實也可以
bestcost = math.inf # 好吧 乾脆就無窮好了
nowcost = 0 # 全域性變數,現在的花費
def TSP(graph, n, s):
global nowcost, bestcost
if(s == n):
if (graph[x[n-1]][x[0]] != 0 and (nowcost +graph[x[n-1]][x[0]]<bestcost)):
print('best way:', x)
bestcost = nowcost + graph[x[n-1]][x[0]]
print('bestcost', bestcost)
else:
for i in range(s, n):
# 如果下一節點不是自身 而且 求得的值小於目前的最佳值
if (graph[x[i-1]][x[i]] != 0 and nowcost+graph[x[i-1]][i] < bestcost):
x[i], x[s] = x[s], x[i] # 交換一下
nowcost += graph[x[s - 1]][x[s]] # 將花費加入
TSP(graph, n, s+1)
nowcost -= graph[x[s - 1]][x[s]] # 回溯上去還需要減去
x[i], x[s] = x[s], x[i] # 別忘記交換回來
TSP(graph, n, 1)
執行的結果為:

一共輸出了兩個結果,說明完整路徑搜尋了兩次,其餘情況下,均在搜尋到中途的時候進行了剪枝操作。
(二)使用分支限界法求解旅行商(TSP)問題
分支限界法概念:
回溯法的求解目標是找出T中滿足約束條件的所有解,而分支限界法的求解目標則是找出滿足約束條件的一個解,或是在滿足約束條件的解中找出使某一目標函式值達到極大或極小的解,即在某種意義下的最優解。
我覺得分支限界法像圖的廣度遍歷,從上往下進行層級的遍歷,一步一步直到最終找到解,不過,不同的地方在於,分支限界法採用了優先佇列的方式進行了優化,首先找尋可能滿足目標函式的解,再利用剪枝進行了優化處理
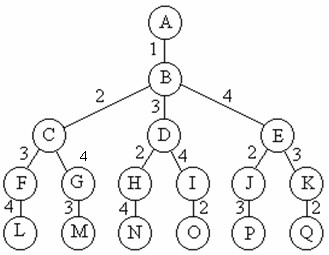
寫演算法的時候,利用上面這張圖,進行了自定義節點類的構造和編寫,並利用優先佇列儲存各個節點,程式碼量大大減少,不同過存在的問題是,如果不是一個完全圖進行輸入,結果會報錯,沒有做到很好的容差性與健壯性,同時新生成的物件太多了,會佔用很大的空間,不過及時的刪除節點將會解決這一問題。
分支限界法的程式碼如下:
# 分支限界法求解旅行商問題
import math
from heapq import *
n=4
x = [1, 2, 3, 4]
# 定義圖的字典形式
G = {
'1': {'2': 30, '3': 6, '4': 4},
'2': {'1': 30, '3': 5, '4': 10},
'3': {'1': 6, '2': 5, '4': 20},
'4': {'1': 4, '2': 10, '3': 20}
}
# 定義圖的陣列形式
graph = [
[0, 30, 6, 4],
[30, 0, 5, 10],
[6, 5, 0 , 20],
[4, 10, 20, 0]
]
bestway = ''
# bestcost = 1<<32 # 這裡只要是一個很大數就行了 無窮其實也可以
bestcost = math.inf # 好吧 乾脆就無窮好了
nowcost = 0 # 全域性變數,現在的花費
# 設定節點類
class Node:
# 建構函式,現在的花費,到目前的路徑
def __init__(self, w=math.inf, route=[], cost=0):
self.weight = w
self.route = route
self.cost = cost
# 過載比較,用於堆的排序
def __lt__(self,other):
return int(self.weight) < int(other.weight)
# 列印
def __str__(self):
return "節點的權重為"+str(self.weight)+" 節點的路徑為"+str(self.route)+" 花費為"+str(self.cost)
def BBTSP(graph, n, s):
global bestcost, bestroute
heap = []
start = Node(route=[str(s)])
heap.append(start)
# 當堆中有數的時候,迴圈繼續
while heap:
nownode = heappop(heap) # 取出權重最大的那個數
# 生成權重最大的那個數的下結點,並且把下結點加入堆中
for e in [r for r in graph if r not in nownode.route]:
node = Node(w=graph[nownode.route[-1]][e], route=nownode.route+[e], cost=nownode.cost+graph[nownode.route[-1]][e])
# 如果現在的值大於最優值,剪枝操作
if node.cost >= bestcost:
continue
# 如果到了最後一個點,加上回去的路,並計算最小值
if len(node.route)==4:
wholecost = graph[node.route[-1]][s]+node.cost
if wholecost < bestcost:
bestcost = wholecost
bestroute = node.route
print("最佳花費為:"+str(bestcost))
print("最佳路徑為:"+str(bestroute))
heap.append(node)
return bestcost
BBTSP(G, n, '1')
實驗結果的如下所示:

結果只是恰好與上面一樣,但是其實裡面內部的機制是完全不一樣的,為什麼使用優先佇列進行優化還是會出現這樣的結果呢?我自己分析了一下,發現優先佇列使用的步驟只是找到三個節點,而從最後一個節點到第一個節點是沒有考慮在內的,所以會出現前面最優而總體結果並不是最優的情況。
相關推薦
演算法課堂實驗報告(五)——python回溯法與分支限界法(旅行商TSP問題)
python實現回溯法與分支限界 一、開發環境 開發工具:jupyter notebook 並使用vscode,cmd命令列工具協助程式設計測試演算法,並使用codeblocks輔助編寫C++程式 程式語言:python3.6 二、實驗目標 1. 請用回溯法求對稱的旅
演算法課堂實驗報告(四)——python動態規劃(最長公共子序列LCS問題)
python實現動態規劃 一、開發環境 開發工具:jupyter notebook 並使用vscode,cmd命令列工具協助程式設計測試演算法,並使用codeblocks輔助編寫C++程式 程式語言:python3.6 二、實驗內容 1.最長公共子序列問題。分別求x=
演算法課堂實驗報告(二)——python遞迴和分治(第k小的數,大數乘法問題)
python實現遞迴和分治 一、開發環境 開發工具:jupyter notebook 並使用vscode,cmd命令列工具協助程式設計測試演算法,並使用codeblocks輔助編寫C++程式 程式語言:python3.6 二、實驗目標 1. 熟悉遞迴和分治演算法實現的
分支界限法 | 裝載問題(先入先出佇列式分支限界法)
輸入要求 有多組資料。每組資料包含2行。第一行包含2個整數 C(1 <= C <= 1000)、和 n(1 <= n <= 10),分別表示的輪船的載重量和集裝箱的個數。第二行包含n個整數,依次表示
0/1揹包問題(回溯法、分支限界法、動態規劃法、貪心法)(C++版)
此篇整理自李老師上課PPT --- On one way by myself(1)問題描述 有n個重量分別為{w1,w2,…,wn}的物品,它們的價值分別為{v1,v2,…,vn},給定一個容量為W的揹包。設計從這些物品中選取一部分物品放入該揹包的方
六中常用演算法設計:窮舉法、分治法、動態規劃、貪心法、回溯法和分支限界法
演算法設計之六種常用演算法設計方法 1.直接遍歷態(窮舉法) 程式執行狀態是可以遍歷的,遍歷演算法執行每一個狀態,最終會找到一個最優的可行解;適用於解決極小規模或者複雜度線性增長,而線
常用演算法:分治演算法、動態規劃演算法、貪心演算法、回溯法、分支限界法
1、概念 回溯演算法實際上一個類似列舉的搜尋嘗試過程,主要是在搜尋嘗試過程中尋找問題的解,當發現已不滿足求解條件時,就“回溯”返回,嘗試別的路徑。 回溯法是一種選優搜尋法,按選優條件向前搜尋,以達到目標。但當探索到某一步時,發現原先選擇並不優或達不到目標,就退回一步重新選擇,這種走不通就退回再
0033演算法筆記——【分支限界法】分支限界法與單源最短路徑問題
1、分支限界法 (1)描述:採用廣度優先產生狀態空間樹的結點,並使用剪枝函式的方法稱為分枝限界法。 所謂“分支”是採用廣度優先的策略,依次生成擴充套件結點的所有分支(即:兒子結點)。所謂“限界”是在結點擴充套件過程中,計算結點的上界(或下界),邊搜尋邊減掉搜尋
第五次作業——python效能分析與幾個問題(個人作業)
結合 撰寫 porting tin 設計實現 cti personal 設計文檔 hub 第五次作業——效能分析與幾個問題(個人作業) 前言 閱讀了大家對於本課程的目標和規劃之後,想必很多同學都躍躍欲試,迫不及待想要提高自身實踐能力,那麽就從第一個個人項目開始吧,題目要求見
python資料分析與挖掘學習筆記(6)-電商網站資料分析及商品自動推薦實戰與關聯規則演算法
這一節主要涉及到的資料探勘演算法是關聯規則及Apriori演算法。 由此展開電商網站資料分析模型的構建和電商網站商品自動推薦的實現,並擴充套件到協同過濾演算法。 關聯規則最有名的故事就是啤酒與尿布的故事,非常有效地說明了關聯規則在知識發現和資料探勘中起的作用和意義。 其中有
PSO解決TSP問題(粒子群演算法解決旅行商問題)--python實現
歡迎私戳關注這位大神! 有任何問題歡迎私戳我->給我寫信 首先來看一下什麼是TSP: The travelling salesman problem (TSP) asks the following question: "Given a list
五大常用演算法之五:分支限界法(轉)
轉載自:http://www.cnblogs.com/steven_oyj/archive/2010/05/22/1741378.html 一、基本描述 類似於回溯法,也是一種在問題的解空間樹T上搜索問題解的演算法。但在一般情況下,分支限界法與回溯法的求解目標
五大常用演算法(五)分支限界法
分支限界法 一、基本描述 類似於回溯法,也是一種在問題的解空間樹T上搜索問題解的演算法。但在一般情況下,分支限界法與回溯法的求解目標不同。回溯法的求解目標是找出T中滿足約束條件的所有解,而分支限界法的求解目標則是找出滿足約束條件的一個解,或是在滿足約束條件的解中找出使某一目標函式值達到極大或極小的解
在路上---學習篇(一)Python 數據結構和算法 (4) --希爾排序、歸並排序
改進 randint 循環 打印 中一 隨機 關鍵詞 shel 條件 獨白: 希爾排序是經過優化的插入排序算法,之前所學的排序在空間上都是使用列表本身。而歸並排序是利用增加新的空間,來換取時間復雜度的減少。這倆者理念完全不一樣,註定造成的所消耗的時間不同以及空間上的不同
python序列化與反序列化(json與pickle)
類型 成了 數據類型 進行 pick 直接 python 優點 一個 在python中,序列化可以理解為將python中對象的編碼格式轉換為json(pickle)格式的字符串,而反序列化可以 理解為將json(pickle)格式的字符串轉換為python中對象的編碼格式
SQL Server 2008 實驗報告 - 第五次實驗報告
實驗五 1.使用T-SQL語句建立資料庫 建立資料庫stuinfo_2,要求: (1)包含三個資料檔案(MF.mdf、F1.ndf、F2.ndf)和兩個日誌檔案(L1.ldf、L2.ldf),檔案的其他屬性自定義。 (2)F1.ndf和F2.ndf放到自定義的檔案組G1中。 (3)資
python 歷險記(六)— python 對正則表示式的使用(上篇)
目錄 引言 什麼是正則表示式? 正則表示式有什麼用? 正則表示式的語法及使用例項 正則表示式語法有哪些? 這些正則到底該怎麼用? 小結 參考文件 系列文章列表 引言 剛接觸正則表示式,我也曾被它們天書似的符號組合給嚇住,但經過一段時間的深入
Python之日期與時間處理模組(date和datetime)
本節內容 前言 相關術語的解釋 時間的表現形式 time模組 datetime模組 時間格式碼 總結 前言 在開發工作中,我們經常需要用到日期與時間,如: 作為日誌資訊的內容輸出 計算某個功能的執行時間 用日期命名一個日誌檔案的名稱 記錄或展示某文章的釋出或修改
Python資料分析與挖掘學習筆記(2)使用pandas進行資料匯入
一、匯入pandas模組: import pandas as pda 二、匯入CSV格式資料: #資料匯入 i=pda.read_csv("E:/hexun.csv") 可對匯入的資料進行統計以及按列排序: #統計 i.describe() #排序 i
Python資料分析與挖掘學習筆記(4)淘寶商品資料探索與清洗實戰
一、相關理論: 資料探索的核心: (1)資料質量分析(跟資料清洗密切聯絡) (2)資料特徵分析(分佈、對比、週期性、相關性、常見統計量等) 資料清洗的步驟: (1)缺失值處理(通過describe與len直接發現、通過0資料發現) (2)異常值處理(通過散點圖發現