
對於qsort和sort使用效率的詳細對比
測試環境 VS2017
思路:用qsort與sort分別對有n個隨機數的陣列進行m次排序。
平臺:x64
sort:
標頭檔案: algorithm
函式原型:
template< class RandomIt >
void sort( RandomIt first, RandomIt last );
template< class RandomIt, class Compare >
void sort( RandomIt first, RandomIt last, Compare comp );
sort作為STL庫的成員函式,肯定是本著庫通用的目的,採用模板超程式設計實現,可對STL庫提供的大部分(?不知道是不是所有,目前僅排序過vector,string(list有自己的sort))容器進行排序(我猜應該是隻能針對連續地址的資料進行排序)。
引數值:要排序的起始迭代器位置,尾後迭代器位置,比較函式(可選)。預設是升序排列。
如果想要降序排列,可以:1,過載要排序的元素型別的<操作符
2,傳遞一個比較函式,如果第一個引數小於第二個該函式,返回true(升序)。
如果第一個引數大於第二個該函式,返回true(降序)。
比較函式的原型為:
bool cmp(const Type1 &a, const Type2 &b);| cmp 函式的返回值 | 描述 |
|---|---|
| true | elem1將被排在elem2前面 |
| false | 對elem1與elem2的次序不做改變 |
qsort:
標頭檔案: cstdlib
函式原型:
void qsort(void *base , int nelem ,int width , int (*fcmp)(const void *,const void *));qsort作為C語言標準庫函式,可對連續地址儲存的變數進行排序,沒有預設排序方式,必須傳入比較函式,並且相對於sort的操作符過載的方式改變排序規則的策略來講,qsort只能通過改變比較函式的方式進行排序,策略單一。
引數值:排序的起始地址,排序的元素長度,要排序元素在記憶體中的佔位值(即sizeof),比較函式指標
比較函式的原型為:
int compare( (void *) & elem1, (void *) & elem2 );| compare 函式的返回值 | 描述 |
|---|---|
| “< 0” | elem1將被排在elem2前面 |
| “0” | elem1 等於 elem2 |
| “> 0” | elem1 將被排在elem2後面 |
**這裡需要注意的是,不同於qsort的比較函式,fcmp返回的是一個int值型別,而不是單純的true和false
如果比較函式寫成**
int comp(const void*a, const void*b)
{
return *(int*)a>*(int*)b;//當a<b時就會返回false,也就是0,那麼會被qsort認為二者相等,最終導致排序錯誤
/*正確寫法*/
//return *(int*)a-*(int*)b;
}使用例項及效率比較:
最開始我是看到這篇文章中對於二者的比較:http://blog.csdn.net/pku_zzy/article/details/51462417
作者得出的結論是,qsort比sort的效率高,一般情況下前者的用時是後者的三分之一,所以他推薦在一般情況下我們應該選擇qsort而不是sort。
對這一結論我有疑惑:qsort只是實現了快速排序,而STL庫中的sort實現了快排,堆排,歸併排等多種排序,並且針對資料量的不同做了諸多優化,如果最終效率不及qsort,那麼STL實現sort的意義在哪兒?
而且,我本人對STL庫是抱著非常敬畏和尊敬的感情的,我不相信STL庫的開發者們會做出這樣沒有意義的事情,並且還把它加到C++的標準庫中。
帶著如上疑問,我決定自己動手寫一個測試,來看看qsort和sort的排序效率到底是怎樣的。
以下為測試程式碼:
#include <cstdio>
#include <windows.h>
#include <cstdlib>
#include<vector>
#include<iostream>
#include<algorithm>
#include<ctime>
using namespace std;
#define MAX_SIZE 1000
#define N_TIMES 10000
int inline comp(const void*a, const void*b)//當返回值大於0時,認為a>b,如果此時與實際情況相符,則按升序排列,相反則按降序排列
//返回值等於0,認為a=b,返回值小於0認為a<b;
//特別需要注意的是,這裡不能返回諸如(*(int*)a) > (*(int*)b)的形式,因為這樣只會返回0和1,而0是被認為二者是相等的
{
return *(int*)a - *(int*)b;
//return 0;
}
inline bool comp_sort(int a, int b)//當返回值為true時,認為a>b,否則,認為a<=b
{
return a < b;
//return false;
}
int main(void)
{
vector<vector<int> > collect_qsort;
vector<vector<int> > collect_sort;
vector<int> temp(MAX_SIZE);
srand((unsigned)time(NULL));//置隨機種子
for (int i = 0; i < MAX_SIZE; i++)//將temp填滿隨機數
{
temp[i] = rand();
}
for (int i = 0; i < N_TIMES; i++)//兩個測試樣例都填充N_TIMES次temp
//這裡兩種排序的測試樣例是完全相同的,都是對temp進行N_TIMES次排序
{
collect_qsort.push_back(temp);
collect_sort.push_back(temp);
}
//下面是計時操作一些相關變數的初始化
LARGE_INTEGER nFreq;
LARGE_INTEGER nBeginTime;
LARGE_INTEGER nEndTime;
double time;
QueryPerformanceFrequency(&nFreq);//獲取系統時鐘頻率
QueryPerformanceCounter(&nBeginTime);//獲取系統當前計數器計數值
/***************************用qsort對樣例進行N_TIMES次排序***************************************/
for(int i=0;i<N_TIMES;i++)
qsort(&collect_qsort[i][0], MAX_SIZE,sizeof(collect_qsort[i][0]),comp);
/****************************************************************************************/
QueryPerformanceCounter(&nEndTime);//獲取系統當前計數器計數值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) / (double)nFreq.QuadPart;//兩次獲取的計數器計數值的差值除以系統時鐘頻率即可得到時間,精確到微秒
printf("cost of Qsort time(%dint data*%d):%f\n", MAX_SIZE,N_TIMES,time);
QueryPerformanceFrequency(&nFreq);//獲取系統時鐘頻率
QueryPerformanceCounter(&nBeginTime);//獲取系統當前計數器計數值
/***************************用qsort對樣例進行N_TIMES次排序***************************************/
for (int i = 0; i<N_TIMES; i++)
sort(collect_sort[i].begin(), collect_sort[i].end(), comp_sort);
/****************************************************************************************/
QueryPerformanceCounter(&nEndTime);//獲取系統當前計數器計數值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) / (double)nFreq.QuadPart;//兩次獲取的計數器計數值的差值除以系統時鐘頻率即可得到時間,精確到微秒
printf("cost of sort time(%dint data*%d):%f\n", MAX_SIZE, N_TIMES, time);
system("Pause");
return 0;
}在該項測試中,我們選取了1000個int型的隨機資料進行排列,分別用sort與qsort對其進行1e4次排列。
在debug模式下,我發現確實如上面那篇部落格的作者所言,sort的用時幾乎是qsort的三倍甚至更多
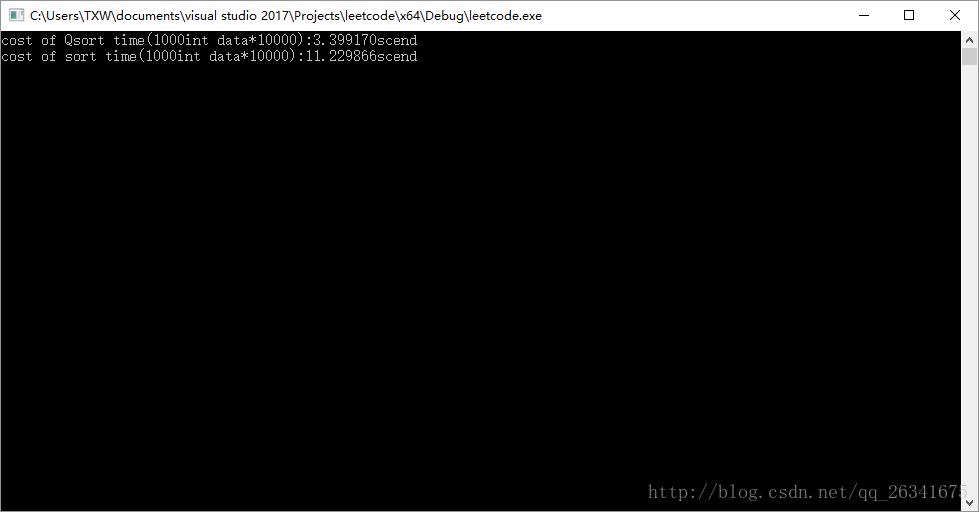
但是IDE在debug模式下對程式碼的監視是要耗費資源的,越大規模的演算法,在debug模式下對其監視所花費的資源也就越多,龐大如VS這樣的IDE,debug所消耗的資源更甚。
因此同樣的程式碼我又在release模式下跑了一遍:
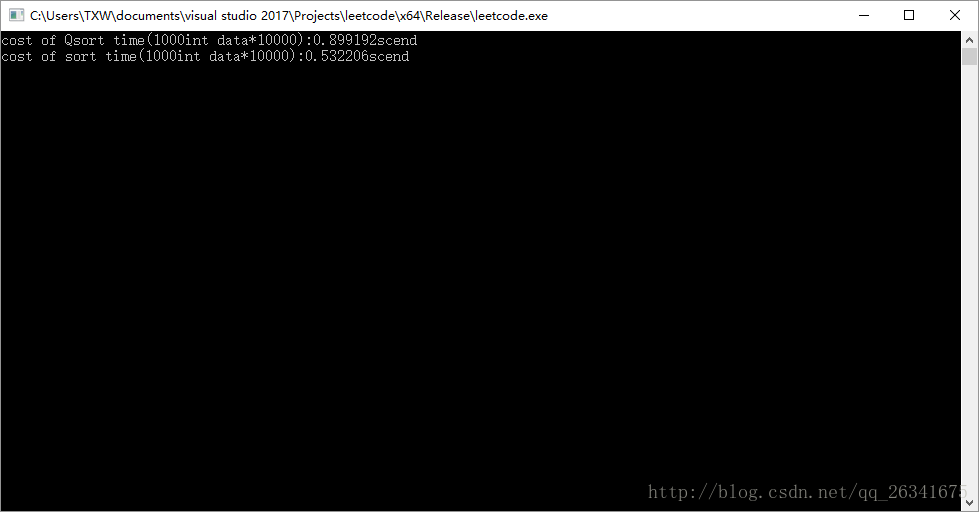
可以看到,在release模式下,兩種排序的時間都大幅降低了,並且sort的用時是明確小於qsort的用時的。
所以,到這裡我可以肯定,上面那篇部落格的作者的測試就是在debug和release的選擇上出了問題。
為了得出一般性的結論,我們選擇不同的輸入規模,來看一看二者的效率是否會發生逆轉
修改測試程式碼中的MAX_SIZE 與 N_TIMES(N_TIMES的作用僅僅是在小規模輸入下增加對同樣的資料的排序次數,以消除計時誤差帶來的影響,不影響sort與qsort的效率的排名結果)
我們來看一看不同規模的輸入下,二者的相對錶現如何:
| 輸入規模(MAX_SIZE ) | 排序次數(N_TIMES) | qsort用時 | sort用時 | qsort:sort |
|---|---|---|---|---|
| 10 | 10000000 | 1.915217s | 0.853853s | 2.24:1 |
| 100 | 1000000 | 3.634150s | 2.172662s | 1.67:1 |
| 1000 | 100000 | 8.398367s | 5.571055s | 1.51:1 |
| 10000 | 10000 | 10.812114s | 8.111797s | 1.33:1 |
| 100000 | 1000 | 13.201909s | 10.600798s | 1.25:1 |
| 1000000 | 100 | 11.275247s | 9.838172s | 1.15:1 |
| 10000000 | 10 | 11.255788s | 9.987730s | 1.13:1 |
| 100000000 | 1 | 10.782703s | 9.452227s | 1.14:1 |
由上表我們可以看出,從10到1e8(即1億)的資料量級的比較中,雖然隨著資料量級的增長,qsort的效率越來越接近sort的效率,但是qsort:sort的值始終是大於1的。 因此不難得出結論,一般情況下而言,sort的效率始終是高於qsort的效率的
因為int是內建型別,我想可能會有影響,所以又定義了一個自定義型別Point
class Point
{
public:
int x;
int y;
};以Point點到座標原點的距離作為排序的依據:
程式碼實現如下
#include <cstdio>
#include <windows.h>
#include <cstdlib>
#include<vector>
#include<iostream>
#include<algorithm>
#include<ctime>
using namespace std;
class Point
{
public:
int x;
int y;
};
int inline comp(const void*a, const void*b)//當返回值大於0時,認為a>b,如果此時與實際情況相符,則按升序排列,相反則按降序排列
//返回值等於0,認為a=b,返回值小於0認為a<b;
//特別需要注意的是,這裡不能返回諸如(*(Point*)a) > (*(Point*)b)的形式,因為這樣只會返回0和1,而0是被認為二者相等的
{
return ((Point*)a)->x* ((Point*)a)->x + ((Point*)a)->y* ((Point*)a)->y - ((Point*)b)->x* ((Point*)b)->x - ((Point*)b)->y* ((Point*)b)->y;
}
inline bool comp_sort(Point &a, Point &b)//當返回值為true時,認為a>b,否則,認為a<=b
{
return a.x*a.x + a.y*a.y < b.x*b.x + b.y*b.y;
}
#define MAX_SIZE 10000
#define N_TIMES 10000
int main(void)
{
vector<vector<Point> > collect_qsort;
vector<vector<Point> > collect_sort;
vector<Point> temp(MAX_SIZE);
srand((unsigned)time(NULL));//置隨機種子
for (int i = 0; i < MAX_SIZE; i++)//將temp填滿隨機數
{
temp[i].x = rand() % 100;
temp[i].y = rand() % 100;
}
for (int i = 0; i < N_TIMES; i++)//兩個測試樣例都填充N_TIMES次temp
//這裡兩種排序的測試樣例是完全相同的,都是對temp進行N_TIMES次排序
{
collect_qsort.push_back(temp);
collect_sort.push_back(temp);
}
//下面是計時操作一些相關變數的初始化
LARGE_INTEGER nFreq;
LARGE_INTEGER nBeginTime;
LARGE_INTEGER nEndTime;
double time;
QueryPerformanceFrequency(&nFreq);//獲取系統時鐘頻率
QueryPerformanceCounter(&nBeginTime);//獲取系統當前計數器計數值
/***************************用qsort對樣例進行N_TIMES次排序***************************************/
for (int i = 0; i<N_TIMES; i++)
qsort(&collect_qsort[i][0], MAX_SIZE, sizeof(collect_qsort[i][0]), comp);
/****************************************************************************************/
QueryPerformanceCounter(&nEndTime);//獲取系統當前計數器計數值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) / (double)nFreq.QuadPart;//兩次獲取的計數器計數值的差值除以系統時鐘頻率即可得到時間,精確到微秒
printf("cost of Qsort time(%dPoint data*%d):%f\n", MAX_SIZE, N_TIMES, time);
QueryPerformanceFrequency(&nFreq);//獲取系統時鐘頻率
QueryPerformanceCounter(&nBeginTime);//獲取系統當前計數器計數值
/***************************用qsort對樣例進行N_TIMES次排序***************************************/
for (int i = 0; i<N_TIMES; i++)
sort(collect_sort[i].begin(), collect_sort[i].end(), comp_sort);
/****************************************************************************************/
QueryPerformanceCounter(&nEndTime);//獲取系統當前計數器計數值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) / (double)nFreq.QuadPart;//兩次獲取的計數器計數值的差值除以系統時鐘頻率即可得到時間,精確到微秒
printf("cost of sort time(%dPoint data*%d):%f\n", MAX_SIZE, N_TIMES, time);
system("Pause");
return 0;
}最終結論沒有改變:
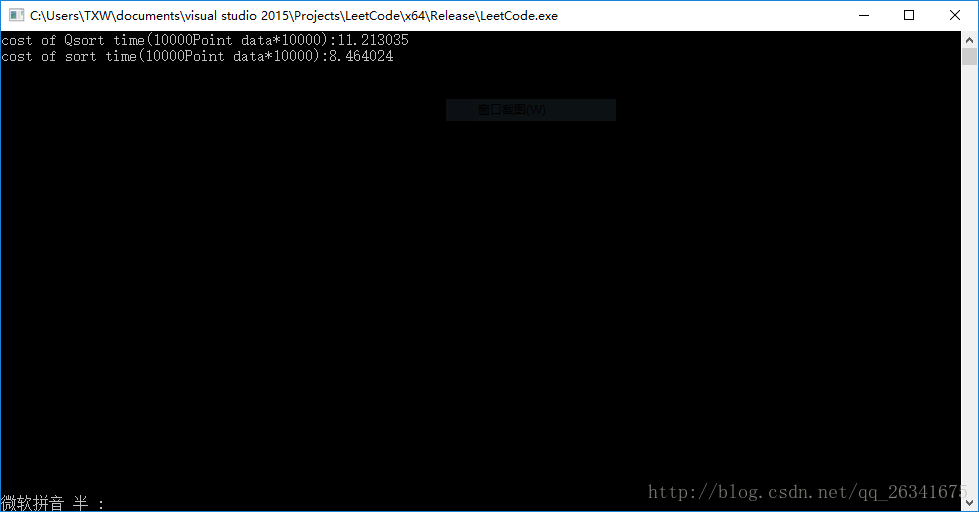
**
因此,任何情況下,我都推薦你使用sort。
**
相關推薦
對於qsort和sort使用效率的詳細對比
測試環境 VS2017 思路:用qsort與sort分別對有n個隨機數的陣列進行m次排序。 平臺:x64 sort: 標頭檔案: algorithm 函式原型: template< class RandomIt > void so
常見資料結構和演算法效率的對比
1. 資料結構部分 資料結構中常用的操作的效率表 通用資料結構 查詢 插入 刪除 遍歷
C語言和C++自帶排序比較(qsort和sort)
我們先來看看C語言的,qsort函式,下面是具體的實現。 #include <stdio.h> #include <stdlib.h> /*const 讓它不能被修改,以只讀型別被用 如果函式引數是任意型別指標,就用void* */ /*qsor
qsort和sort的區別
qsort 基本快速排序的方法,每次把陣列分成兩分和中間的一個劃分值,而對於有多個重複值的陣列來說,基本排序的效率較低。整合在C語言庫函式裡面的的qsort函式,使用 三 路劃分的方法解決這個問題。所謂三路劃分,是指把陣列劃分成小於劃分值,等於劃分值和大於劃分值的三
VC介面庫BCGControlBar和Xtreme Toolkit詳細對比評測
筆者最近專案中正好要用到VC介面庫,於是在網上搜索一下,發現以前大家分享了不少MFC相關的介面庫,但大多都已經多年不更新,甚至連地址都不復存在。最後筆者鎖定了兩款"存活"至今的VC介面庫: 和。它們的共同特點是都支援微軟Office和Visual Studio風格,這裡就跟大家分享一下筆者的一些試用體驗。
JavaWeb學習篇之----容器Response詳解(有關response setCharacterEncoding和setContentType)詳細對比說明
今天在來看一下Response容器的相關知識,其實這篇blog早就應該編寫了,只是最近有點忙,所以被中斷了。下面我們就來看一下Response容器的相關知識吧。Response和我們即將在後面說到的Request容器是一一對應的,他是web容器在使用者每次請求服務端的
雲端計算廠商國內和海外價格詳細對比
隨著雲端計算的不斷髮展,各個廠家的競爭也越來越激烈,但是綜合資料分析還是“品牌”廠商可以提供更加可靠、可信、穩定的雲服務,廠商、配置、地域等因素不同,雲產品價格不同,此外雲端計算廠商各有所長,下面我主要從IAAS層面針對阿里雲、騰訊雲、微軟雲、AWS和華為雲國內、海外做一個詳細全面的價
SSH和SSM——詳細對比總結
當下流行的兩種企業開發MVC開源框架,是我們Java程式猿必備知識能力。MVC,即模型(model)-檢視(view)-控制器(controller)的縮寫,一種軟體設計典範,用一種業務邏輯、資料、介面顯示分離的方法組織程式碼,將業務
redis使用管道和普通模式下執行效率的對比
1 普通模式 $redis = new Redis; $redis->connect("127.0.0.1","6379"); $redis->auth("123456"); for($i=0;$i<10000;$i++){
LINUX下兩種tar打包(.bz2)和(.gz)壓縮效率時間對比試驗
試驗檔案大小:204M,檔名:xx.dat 壓縮 1. tar czvf test.tar.gz xx.dat 耗時20秒,打包後大小:123M 2.tar cjvf test.tar.bz2 xx.dat 耗時82秒,打包後大小:133M 解壓 1. tar
常用資料結構和演算法操作效率的對比總結
歡迎關注我新搭建的部落格:[http://www.itcodai.com/](http://www.itcodai.com/) 前面介紹了經典的資料結構和演算法,這一節我們對這些資料結構和演算法做一個總結,具體細節,請參見各個章節的詳細介紹,這裡我們用表
qsort()函式和sort()函式
2. STL 中 sort 函式用法簡介 做 ACM 題的時候,排序是一種經常要用到的操作。如果每次都自己寫個冒泡之類的O(n^2) 排序,不但程式容易超時,而且浪費寶貴的比賽時間,還很有可能寫錯。 STL 裡面有個 sort 函式,可以直接對陣列排序,複雜度為n*log2(n) 。 使用這個函式,需要包
關於php strtr 和 str_replace 效率的問題
abcde 優化 bcd php 7 abcdefg 5.6 nginx 網上 環境 在網上看了一些php優化的指南,裏面提到:使用strtr 函數 比 str_replace快4倍。 本著探索的精神動手驗證。 代碼 $string = ‘abcdefg‘; set_
Android Dalvik虛擬機和ART虛擬機對比
x文件 開始 過程 優秀 clas 編譯 apk 但是 好的 1.概述 Android4.4以上開始使用ART虛擬機,在此之前我們一直使用的Dalvik虛擬機,那麽為什麽Google突然換了Android運行的虛擬機呢?答案只有一個:ART虛擬機更優秀。 2.Dalvik
mapreduce shuffle 和sort 詳解
改變 struct 堆內存 傳輸 工具 默認 臨時 arc 快速排序 MapReduce 框架的核心步驟主要分兩部分:Map 和Reduce。當你向MapReduce 框架提交一個計算作業時,它會首先把計算作業拆分成若幹個Map 任務,然後分配到不同的節點上去執
Python基礎課:定義一個函數,可以對序列逆序的輸出(對於列表和元組可以不用考慮嵌套的情況)
int 情況 type spa list bsp pri not log 1 15 def fun(arg): 2 16 if type(arg) is not tuple 3 17 and type(arg) is not str 4 18
MySQL與Oracle的語法區別詳細對比
變量 into lpad while循環 獲得 var 無符號 這樣的 ims Oracle和mysql的一些簡單命令對比 1) SQL> select to_char(sysdate,‘yyyy-mm-dd‘) from dual; SQL> select
shuffle和sort分析
理解 不同 http 寫入 mapr 中一 重復 進入 ons MapReduce中的Shuffle和Sort分析 MapReduce 是現今一個非常流行的分布式計算框架,它被設計用於並行計算海量數據。第一個提出該技術框架的是Google 公司,而Google 的靈感則來自
MyBatis和Hibernate的優缺點對比
hiberna 編寫 完全 都是 關聯 生成 模式 相對 臟數據 Hibernate的優點: 1、hibernate是全自動,hibernate完全可以通過對象關系模型實現對數據庫的操作,擁有完整的JavaBean對象與數據庫的映射結構來自動生成sql。 2、功能強大,數據
【持久化框架】Mybatis與Hibernate的詳細對比
很大的 效率 myba 今天 http 目的 ping pin 增刪 作為一位優秀的程序員,只知道一種ORM框架是遠遠不夠的。在開發項目之前,架構的技術選型對於項目是否成功起到至關重要的作用。我們不僅要了解同類型框架的原理以及技術實現,還要深入的理解各自的優缺點,以便我們能