
解決伺服器存在大量TIME_WAIT和CLOSE_WAIT狀態
裡頭的分析過程有提到,通過檢視伺服器網路狀態檢測到伺服器有大量的CLOSE_WAIT的狀態。
在伺服器的日常維護過程中,會經常用到下面的命令:
- netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
它會顯示例如下面的資訊:
TIME_WAIT 814
CLOSE_WAIT 1
FIN_WAIT1 1
ESTABLISHED 634
SYN_RECV 2
LAST_ACK 1
常用的三個狀態是:ESTABLISHED 表示正在通訊,TIME_WAIT 表示主動關閉,CLOSE_WAIT 表示被動關閉。
具體每種狀態什麼意思,其實無需多說,看看下面這種圖就明白了,注意這裡提到的伺服器應該是業務請求接受處理的一方:
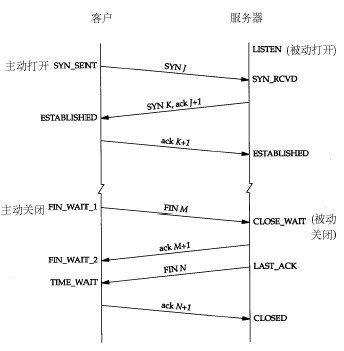
這麼多狀態不用都記住,只要瞭解到我上面提到的最常見的三種狀態的意義就可以了。一般不到萬不得已的情況也不會去檢視網路狀態,如果伺服器出了異常,百分之八九十都是下面兩種情況:
1.伺服器保持了大量TIME_WAIT狀態
2.伺服器保持了大量CLOSE_WAIT狀態
因為linux分配給一個使用者的檔案控制代碼是有限的(可以參考:http://blog.csdn.net/shootyou/article/details/6579139),而TIME_WAIT和CLOSE_WAIT兩種狀態如果一直被保持,那麼意味著對應數目的通道就一直被佔著,而且是“佔著茅坑不使勁”,一旦達到控制代碼數上限,新的請求就無法被處理了,接著就是大量Too Many Open Files異常,tomcat崩潰。。。
下面來討論下這兩種情況的處理方法,網上有很多資料把這兩種情況的處理方法混為一談,以為優化系統核心引數就可以解決問題,其實是不恰當的,優化系統核心引數解決TIME_WAIT可能很容易,但是應對CLOSE_WAIT的情況還是需要從程式本身出發。現在來分別說說這兩種情況的處理方法:
1.伺服器保持了大量TIME_WAIT狀態
這種情況比較常見,一些爬蟲伺服器或者WEB伺服器(如果網管在安裝的時候沒有做核心引數優化的話)上經常會遇到這個問題,這個問題是怎麼產生的呢?
從上面的示意圖可以看得出來,TIME_WAIT是主動關閉連線的一方保持的狀態,對於爬蟲伺服器來說他本身就是“客戶端”,在完成一個爬取任務之後,他就會發起主動關閉連線,從而進入TIME_WAIT的狀態,然後在保持這個狀態2MSL(max segment lifetime)時間之後,徹底關閉回收資源。為什麼要這麼做?明明就已經主動關閉連線了為啥還要保持資源一段時間呢?這個是TCP/IP的設計者規定的,主要出於以下兩個方面的考慮:
1.防止上一次連線中的包,迷路後重新出現,影響新連線(經過2MSL,上一次連線中所有的重複包都會消失)
2.可靠的關閉TCP連線。在主動關閉方傳送的最後一個 ack(fin) ,有可能丟失,這時被動方會重新發fin, 如果這時主動方處於 CLOSED 狀態 ,就會響應 rst 而不是 ack。所以主動方要處於 TIME_WAIT 狀態,而不能是 CLOSED 。另外這麼設計TIME_WAIT 會定時的回收資源,並不會佔用很大資源的,除非短時間內接受大量請求或者受到攻擊。
關於MSL引用下面一段話:
- MSL 為一個 TCP Segment (某一塊 TCP 網路封包) 從來源送到目的之間可續存的時間 (也就是一個網路封包在網路上傳輸時能存活的時間),由於 RFC 793 TCP 傳輸協定是在 1981 年定義的,當時的網路速度不像現在的網際網路那樣發達,你可以想像你從瀏覽器輸入網址等到第一個 byte 出現要等 4 分鐘嗎?在現在的網路環境下幾乎不可能有這種事情發生,因此我們大可將 TIME_WAIT 狀態的續存時間大幅調低,好讓 連線埠 (Ports) 能更快空出來給其他連線使用。
再引用網路資源的一段話:
- 值得一說的是,對於基於TCP的HTTP協議,關閉TCP連線的是Server端,這樣,Server端會進入TIME_WAIT狀態,可 想而知,對於訪問量大的Web Server,會存在大量的TIME_WAIT狀態,假如server一秒鐘接收1000個請求,那麼就會積壓240*1000=240,000個 TIME_WAIT的記錄,維護這些狀態給Server帶來負擔。當然現代作業系統都會用快速的查詢演算法來管理這些TIME_WAIT,所以對於新的 TCP連線請求,判斷是否hit中一個TIME_WAIT不會太費時間,但是有這麼多狀態要維護總是不好。
- HTTP協議1.1版規定default行為是Keep-Alive,也就是會重用TCP連線傳輸多個 request/response,一個主要原因就是發現了這個問題。
也就是說HTTP的互動跟上面畫的那個圖是不一樣的,關閉連線的不是客戶端,而是伺服器,所以web伺服器也是會出現大量的TIME_WAIT的情況的。 現在來說如何來解決這個問題。 解決思路很簡單,就是讓伺服器能夠快速回收和重用那些TIME_WAIT的資源。 下面來看一下我們網管對/etc/sysctl.conf檔案的修改:
- #對於一個新建連線,核心要傳送多少個 SYN 連線請求才決定放棄,不應該大於255,預設值是5,對應於180秒左右時間
- net.ipv4.tcp_syn_retries=2
- #net.ipv4.tcp_synack_retries=2
- #表示當keepalive起用的時候,TCP傳送keepalive訊息的頻度。預設是2小時,改為300秒
- net.ipv4.tcp_keepalive_time=1200
- net.ipv4.tcp_orphan_retries=3
- #表示如果套接字由本端要求關閉,這個引數決定了它保持在FIN-WAIT-2狀態的時間
- net.ipv4.tcp_fin_timeout=30
- #表示SYN佇列的長度,預設為1024,加大佇列長度為8192,可以容納更多等待連線的網路連線數。
- net.ipv4.tcp_max_syn_backlog = 4096
- #表示開啟SYN Cookies。當出現SYN等待佇列溢位時,啟用cookies來處理,可防範少量SYN攻擊,預設為0,表示關閉
- net.ipv4.tcp_syncookies = 1
- #表示開啟重用。允許將TIME-WAIT sockets重新用於新的TCP連線,預設為0,表示關閉
- net.ipv4.tcp_tw_reuse = 1
- #表示開啟TCP連線中TIME-WAIT sockets的快速回收,預設為0,表示關閉
- net.ipv4.tcp_tw_recycle = 1
- ##減少超時前的探測次數
- net.ipv4.tcp_keepalive_probes=5
- ##優化網路裝置接收佇列
- net.core.netdev_max_backlog=3000
修改完之後執行/sbin/sysctl -p讓引數生效。 這裡頭主要注意到的是net.ipv4.tcp_tw_reuse net.ipv4.tcp_tw_recycle
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
這幾個引數。 net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle的開啟都是為了回收處於TIME_WAIT狀態的資源。
net.ipv4.tcp_fin_timeout這個時間可以減少在異常情況下伺服器從FIN-WAIT-2轉到TIME_WAIT的時間。
net.ipv4.tcp_keepalive_*一系列引數,是用來設定伺服器檢測連線存活的相關配置。
[2015.01.13更新] 注意tcp_tw_recycle開啟的風險:http://blog.csdn.net/wireless_tech/article/details/6405755 2.伺服器保持了大量CLOSE_WAIT狀態
休息一下,喘口氣,一開始只是打算說說TIME_WAIT和CLOSE_WAIT的區別,沒想到越挖越深,這也是寫部落格總結的好處,總可以有意外的收穫。 TIME_WAIT狀態可以通過優化伺服器引數得到解決,因為發生TIME_WAIT的情況是伺服器自己可控的,要麼就是對方連線的異常,要麼就是自己沒有迅速回收資源,總之不是由於自己程式錯誤導致的。 但是CLOSE_WAIT就不一樣了,從上面的圖可以看出來,如果一直保持在CLOSE_WAIT狀態,那麼只有一種情況,就是在對方關閉連線之後伺服器程式自己沒有進一步發出ack訊號。換句話說,就是在對方連線關閉之後,程式裡沒有檢測到,或者程式壓根就忘記了這個時候需要關閉連線,於是這個資源就一直被程式佔著。個人覺得這種情況,通過伺服器核心引數也沒辦法解決,伺服器對於程式搶佔的資源沒有主動回收的權利,除非終止程式執行。 在那邊日誌裡頭我舉了個場景,來說明CLOSE_WAIT和TIME_WAIT的區別,這裡重新描述一下: 伺服器A是一臺爬蟲伺服器,它使用簡單的HttpClient去請求資源伺服器B上面的apache獲取檔案資源,正常情況下,如果請求成功,那麼在抓取完資源後,伺服器A會主動發出關閉連線的請求,這個時候就是主動關閉連線,伺服器A的連線狀態我們可以看到是TIME_WAIT。如果一旦發生異常呢?假設請求的資源伺服器B上並不存在,那麼這個時候就會由伺服器B發出關閉連線的請求,伺服器A就是被動的關閉了連線,如果伺服器A被動關閉連線之後程式設計師忘了讓HttpClient釋放連線,那就會造成CLOSE_WAIT的狀態了。
所以如果將大量CLOSE_WAIT的解決辦法總結為一句話那就是:查程式碼。因為問題出在伺服器程式裡頭啊。 參考資料:
相關推薦
解決伺服器存在大量TIME_WAIT和CLOSE_WAIT狀態
裡頭的分析過程有提到,通過檢視伺服器網路狀態檢測到伺服器有大量的CLOSE_WAIT的狀態。 在伺服器的日常維護過程中,會經常用到下面的命令: netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) prin
伺服器開發之大量time_wait 和 close_wait現象
一.tcp狀態轉換圖因為time_wait和close_wait狀態都是在tcp四次揮手狀態下觸發的,所以小夥伴們直接看下圖狀態變化的解釋過程:從客戶端來看:1.客戶端主動斷開連線時,會先發送FIN包,客戶端此時進入FIN_WAIT_1狀態;2.客戶端收到伺服器的ACK包(對
CentOS, 解決伺服器存在大量time_wait的問題
近期伺服器出現大量time_wait的TCP連線造成伺服器連線數過多而最終導致tomcat假死狀態。連線伺服器檢視連線數的時候提示如下。 [[email protected] apache-tomcat-7.0.53]# netstat -n | awk '/^
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法 伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法 來自:http://blog.csdn.net/shootyou/article/details/6622226 昨天解決了一個HttpClient呼叫錯誤導致的
伺服器TIME_WAIT和CLOSE_WAIT區別及解決方案
系統上線之後,通過如下語句檢視伺服器時,發現有不少TIME_WAIT和CLOSE_WAIT。 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 列印顯示如下: TIME_WAIT
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
昨天解決了一個HttpClient呼叫錯誤導致的伺服器異常,具體過程如下: 裡頭的分析過程有提到,通過檢視伺服器網路狀態檢測到伺服器有大量的CLOSE_WAIT的狀態。 在伺服器的日常維護過程中,會經常用到下面的命令: [plain] view plaincopyprint?
服務器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
src 並不會 blog 目的 core 沒有 解決辦法 ++ 重用 來自:http://blog.csdn.net/shootyou/article/details/6622226 昨天解決了一個HttpClient調用錯誤導致的服務器異常,具體過程如下:
再談應用環境下的 TIME_WAIT 和 CLOSE_WAIT
ech 防範 生效 場景 closed 防止 減少 進入 top 轉自:http://blog.csdn.net/shootyou/article/details/6622226 昨天解決了一個HttpClient調用錯誤導致的服務器異常,具體過程如下: http://
time_wait和close_wait
發生 運行 -i 導致 自己 異常 可控 time_wait 進程 TIME_WAIT狀態可以通過優化服務器參數得到解決,因為發生TIME_WAIT的情況是服務器自己可控的,要麽就是對方連接的異常,要麽就是自己沒有迅速回收資源,總之不是由於自己程序錯誤導致的。 如果一直保持
TIME_WAIT和CLOSE_WAIT 小分享-運維筆記
相信很多運維工程師遇到過這樣一個情形: 使用者反饋網站訪問巨慢, 網路延遲等問題, 然後就迫切地登入伺服器,終端輸入命令"netstat -a | grep TIME_WAIT | wc -l " 檢視一下, 接著發現有幾百甚至幾千個TIME_WAIT 連線數. 頓時慌了~, 接著嘗
解決伺服器上 w3wp.exe 和 sqlservr.exe 的記憶體佔用率居高不下的方案
SQL Server是如何使用記憶體 最大的開銷一般是用於資料快取,如果記憶體足夠,它會把用過的資料和覺得你會用到的資料統統扔到記憶體中,直到記憶體不足的時候,才把命中率低的資料給清掉。所以一般我們在看statistics io的時候,看到的physics read都是
系統調優,你所不知道的TIME_WAIT和CLOSE_WAIT
http://mp.weixin.qq.com/s?__biz=MzA3MzYwNjQ3NA==&mid=403319808&idx=1&sn=ddae082f5b844d040b9ab23c9c0eb778&scene=23&srcid=0311hhv2oaIbIdk
解決-伺服器Linux存在大量time_wait的問題,導致服務效能問題,甚至嚴重的將訪問不了應用
netstat -an檢視到大量的TIME_WAIT狀態的解決辦法 近期伺服器出現大量time_wait的TCP連線造成伺服器連線數過多而最終導致tomcat假死狀態。連線伺服器檢視連線數的時候提示如下。 [[email protected] apache-tomcat-7.
close_wait狀態和time_wait狀態
根據TCP協議,主動發起關閉的一方,會進入TIME_WAIT狀態,持續2*MSL(Max Segment Lifetime),預設為240秒,在這個post中簡潔的介紹了為什麼需要這個狀態。 值得一說的是,對於基於TCP的HTTP協議,關閉TCP連線的是Server端,這樣,Server端會進入TIME
Resin伺服器出現大量的ESTABLISHED和TIME_WAIT連線造成響應緩慢
Resin服務的埠為8080,執行 lsof -i:8080 命令出現大量的ESTABLISHED連線: 然後執行netstat -n | awk ‘/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}’ 命令發現
大量TIME_WAIT的終極詳解和解決方案
上篇筆記主要介紹了與TIME_WAIT相關的基礎知識,本文則從實踐出發,說明如何解決文章標題提出的問題。 1. 檢視系統網路配置和當前TCP狀態在定位並處理應用程式出現的網路問題時,瞭解系統預設網路配置是非常必要的。以x86_64平臺Linux kernelversion
網路伺服器-解決伺服器大量TIME_WAIT而無法訪問的方法
前段時間我在進行線上專案壓力測試的時候,遇到了一個吞吐量的效能問題,當時我的Server和Client之間的通訊協議採用了Json Over HTTP的方式(並且在同一個機器上面,其實應該是出現在Client的那個機器上),而且由於Client的實現原因,沒有任何KeepAlive機制,同時必須有大量的請
Nginx造成後端伺服器大量TIME_WAIT的解決辦法
1 Linux下調引數 2 Windows下修改登錄檔 以上兩種方法滿處都是,不再贅述。 據說Nginx預設使用短連線和後端伺服器通訊,所以可以嘗試改成長連線,也就是keepalive, 我這裡是把Nginx升級到1.2版本,會帶ngx_http_upstream_ke
內存溢出和內存泄漏的區別、產生原因以及解決方案 轉
服務 har 操作 ger 遞歸調用 問題 let share 查錯 內存溢出 out of memory,是指程序在申請內存時,沒有足夠的內存空間供其使用,出現out of memory;比如申請了一個integer,但給它存了long才能存下的數,那就是內存溢出。 內
Memcache 內存分配策略和性能(使用)狀態檢查
asd一直在使用Memcache,但是對其內部的問題,如它內存是怎麽樣被使用的,使用一段時間後想看看一些狀態怎麽樣?一直都不清楚,查了又忘記,現在整理出該篇文章,方便自己查閱。本文不涉及安裝、操作。有興趣的同學可以查看之前寫的文章和Google。1:參數memcached -h memcached 1.4.