
JAVA SkipList 跳錶 的原理和使用例子
跳錶的原理與特點
跳躍連結串列是一種隨機化資料結構,基於並聯的連結串列,其效率可比擬於二叉查詢樹(對於大多數操作需要O(log n)平均時間),並且對併發演算法友好。
基本上,跳躍列表是對有序的連結串列增加上附加的前進連結,增加是以隨機化的方式進行的,所以在列表中的查詢可以快速的跳過部分列表(因此得名)。
所有操作都以對數隨機化的時間進行。
跳躍列表是按層建造的。底層是一個普通的有序連結串列。每個更高層都充當下面列表的"快速跑道",這裡在層 i 中的元素按某個固定的概率 p 出現在層 i+1 中。
平均起來,每個元素都在 1/(1-p) 個列表中出現,而最高層的元素(通常是在跳躍列表前端的一個特殊的頭元素)在 O(log1/pn) 個列表中出現。
要查詢一個目標元素,起步於頭元素和頂層列表,並沿著每個連結串列搜尋,直到到達小於或的等於目標的最後一個元素。
通過跟蹤起自目標直到到達在更高列表中出現的元素的反向查詢路徑,在每個連結串列中預期的步數顯而易見是 1/p。所以查詢的總體代價是 O(log1/p n / p),
當p 是常數時是 O(logn)。通過選擇不同p 值,就可以在查詢代價和儲存代價之間作出權衡。
插入和刪除的實現非常像相應的連結串列操作,除了"高層"元素必須在多個連結串列中插入或刪除之外。
跳躍列表不像某些傳統平衡樹資料結構那樣提供絕對的最壞情況效能保證,因為用來建造跳躍列表的扔硬幣方法總有可能(儘管概率很小)生成一個糟糕的不平衡結構。
但是在實際中它工作的很好,隨機化平衡方案比在平衡二叉查詢樹中用的確定性平衡方案容易實現。跳躍列表在平行計算中也很有用,
這裡的插入可以在跳躍列表不同的部分並行的進行,而不用全域性的資料結構重新平衡。
跳躍表的應用
Skip list(跳錶)是一種可以代替平衡樹的資料結構,預設是按照Key值升序的。Skip list讓已排序的資料分佈在多層連結串列中,以0-1隨機數決定一個數據的向上攀升與否,通過“空間來換取時間”的一個演算法,在每個節點中增加了向前的指標,在插入、刪除、查詢時可以忽略一些不可能涉及到的結點,從而提高了效率。
在Java的API中已經有了實現:分別是
1: ConcurrentSkipListMap. 在功能上對應HashTable、HashMap、TreeMap。
2: ConcurrentSkipListSet . 在功能上對應HashSet.
確切來說,SkipList更像Java中的TreeMap。TreeMap基於紅黑樹(一種自平衡二叉查詢樹)實現的,時間複雜度平均能達到O(log n),TreeMap輸出是有序的,ConcurrentSkipListMap和ConcurrentSkipListSet 輸出也是有序的(本博測試過)。下例的輸出是從小到大,有序的。
package MyMap;
import java.util.*;
import java.util.concurrent.*;
/*
* 跳錶(SkipList)這種資料結構算是以前比較少聽說過,它所實現的功能與紅黑樹,AVL樹都差不太多,說白了就是一種基於排序的索引結構,
* 它的統計效率與紅黑樹差不多,但是它的原理,實現難度以及程式設計難度要比紅黑樹簡單。
* 另外它還有一個平衡的樹形索引機構沒有的好處,這也是引導自己瞭解跳錶這種資料結構的原因,就是在併發環境下其表現很好.
* 這裡可以想象,在沒有了解SkipList這種資料結構之前,如果要在併發環境下構造基於排序的索引結構,那麼也就紅黑樹是一種比較好的選擇了,
* 但是它的平衡操作要求對整個樹形結構的鎖定,因此在併發環境下效能和伸縮性並不好.
* 在Java中,skiplist提供了兩種:
* ConcurrentSkipListMap 和 ConcurrentSkipListSet
* 兩者都是按自然排序輸出。
*/
public class SkipListDemo {
public static void skipListMapshow(){
Map<Integer,String> map= new ConcurrentSkipListMap<>();
map.put(1, "1");
map.put(23, "23");
map.put(3, "3");
map.put(2, "2");
/*輸出是有序的,從小到大。
* output
* 1
* 2
* 3
* 23
*
*/
for(Integer key : map.keySet()){
System.out.println(map.get(key));
}
}
public static void skipListSetshow(){
Set<Integer> mset= new ConcurrentSkipListSet<>();
mset.add(1);
mset.add(21);
mset.add(6);
mset.add(2);
//輸出是有序的,從小到大。
//skipListSet result=[1, 2, 6, 21]
System.out.println("ConcurrentSkipListSet result="+mset);
Set<String> myset = new ConcurrentSkipListSet<>();
System.out.println(myset.add("abc"));
System.out.println(myset.add("fgi"));
System.out.println(myset.add("def"));
System.out.println(myset.add("Abc"));
/*
* 輸出是有序的:ConcurrentSkipListSet contains=[Abc, abc, def, fgi]
*/
System.out.println("ConcurrentSkipListSet contains="+myset);
}
}
輸出結果:
1
2
3
23
ConcurrentSkipListSet result=[1, 2, 6, 21]
true
true
true
true
ConcurrentSkipListSet contains=[Abc, abc, def, fgi]
HashMap是基於散列表實現的,時間複雜度平均能達到O(1)。ConcurrentSkipListMap是基於跳錶實現的,時間複雜度平均能達到O(log n)。
Skip list的性質
(1) 由很多層結構組成,level是通過一定的概率隨機產生的。
(2) 每一層都是一個有序的連結串列,預設是升序
(3) 最底層(Level 1)的連結串列包含所有元素。
(4) 如果一個元素出現在Level i 的連結串列中,則它在Level i 之下的連結串列也都會出現。
(5) 每個節點包含兩個指標,一個指向同一連結串列中的下一個元素,一個指向下面一層的元素。
Ø ConcurrentSkipListMap具有Skip list的性質 ,並且適用於大規模資料的併發訪問。多個執行緒可以安全地併發執行插入、移除、更新和訪問操作。與其他有鎖機制的資料結構在巨大的壓力下相比有優勢。
Ø TreeMap插入資料時平衡樹採用嚴格的旋轉(比如平衡二叉樹有左旋右旋)來保證平衡,因此Skip list比較容易實現,而且相比平衡樹有著較高的執行效率。
為什麼選擇跳錶
目前經常使用的平衡資料結構有:B樹,紅黑樹,AVL樹,Splay Tree, Treep等。想象一下,給你一張草稿紙,一隻筆,一個編輯器,你能立即實現一顆紅黑樹,
或者AVL樹出來嗎? 很難吧,這需要時間,要考慮很多細節,要參考一堆演算法與資料結構之類的樹,
還要參考網上的程式碼,相當麻煩。
用跳錶吧,跳錶是一種隨機化的資料結構,目前開源軟體 Redis 和 LevelDB 都有用到它,它的效率和紅黑樹以及 AVL 樹不相上下,
但跳錶的原理相當簡單,只要你能熟練操作連結串列,就能輕鬆實現一個 SkipList。
有序表的搜尋
考慮一個有序表:

從該有序表中搜索元素 < 23, 43, 59 > ,需要比較的次數分別為 < 2, 4, 6 >,總共比較的次數
為 2 + 4 + 6 = 12 次。有沒有優化的演算法嗎? 連結串列是有序的,但不能使用二分查詢。類似二叉
搜尋樹,我們把一些節點提取出來,作為索引。得到如下結構:
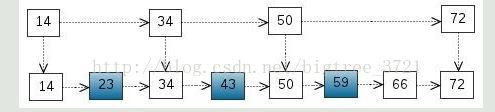
這裡我們把 < 14, 34, 50, 72 > 提取出來作為一級索引,這樣搜尋的時候就可以減少比較次數了。
我們還可以再從一級索引提取一些元素出來,作為二級索引,變成如下結構:
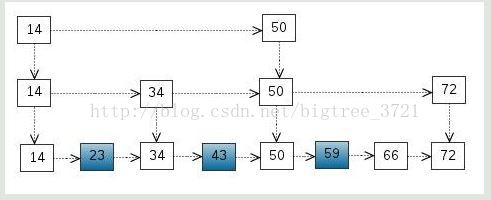
這裡元素不多,體現不出優勢,如果元素足夠多,這種索引結構就能體現出優勢來了。
這基本上就是跳錶的核心思想,其實也是一種通過“空間來換取時間”的一個演算法,通過在每個節點中增加了向前的指標,從而提升查詢的效率。
跳錶
下面的結構是就是跳錶:
其中 -1 表示 INT_MIN, 連結串列的最小值,1 表示 INT_MAX,連結串列的最大值。
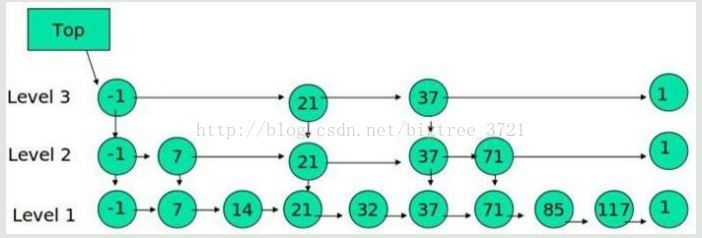
跳錶具有如下性質:
(1) 由很多層結構組成
(2) 每一層都是一個有序的連結串列
(3) 最底層(Level 1)的連結串列包含所有元素
(4) 如果一個元素出現在 Level i 的連結串列中,則它在 Level i 之下的連結串列也都會出現。
(5) 每個節點包含兩個指標,一個指向同一連結串列中的下一個元素,一個指向下面一層的元素。
跳錶的搜尋
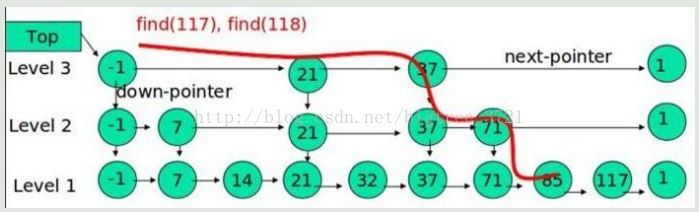
例子:查詢元素 117
(1) 比較 21, 比 21 大,往後面找
(2) 比較 37, 比 37大,比連結串列最大值小,從 37 的下面一層開始找
(3) 比較 71, 比 71 大,比連結串列最大值小,從 71 的下面一層開始找
(4) 比較 85, 比 85 大,從後面找
(5) 比較 117, 等於 117, 找到了節點。
具體的搜尋演算法如下:
C程式碼
1.
3. find(x)
4. {
5. p = top;
6. while (1) {
7. while (p->next->key < x)
8. p = p->next;
9. if (p->down == NULL)
10. return p->next;
11. p = p->down;
12. }
13. }
跳錶的插入
先確定該元素要佔據的層數 K(採用丟硬幣的方式,這完全是隨機的)
然後在 Level 1 ... Level K 各個層的連結串列都插入元素。
例子:插入 119, K = 2
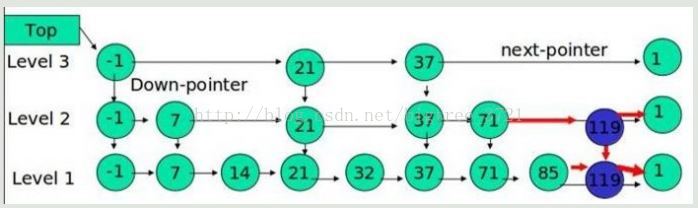
如果 K 大於連結串列的層數,則要新增新的層。
例子:插入 119, K = 4
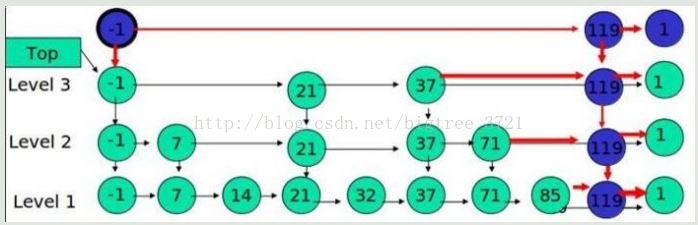
丟硬幣決定 K
插入元素的時候,元素所佔有的層數完全是隨機的,通過一下隨機演算法產生:
1. int random_level()
2. {
3. K = 1;
4.
5. while (random(0,1))
6. K++;
7.
8. return K;
9. }
相當與做一次丟硬幣的實驗,如果遇到正面,繼續丟,遇到反面,則停止,
用實驗中丟硬幣的次數 K 作為元素佔有的層數。顯然隨機變數 K 滿足引數為 p = 1/2 的幾何分佈,
K 的期望值 E[K] = 1/p = 2. 就是說,各個元素的層數,期望值是 2 層。
跳錶的高度。
n 個元素的跳錶,每個元素插入的時候都要做一次實驗,用來決定元素佔據的層數 K,
跳錶的高度等於這 n 次實驗中產生的最大 K,待續。。。
跳錶的空間複雜度分析
根據上面的分析,每個元素的期望高度為 2, 一個大小為 n 的跳錶,其節點數目的
期望值是 2n。
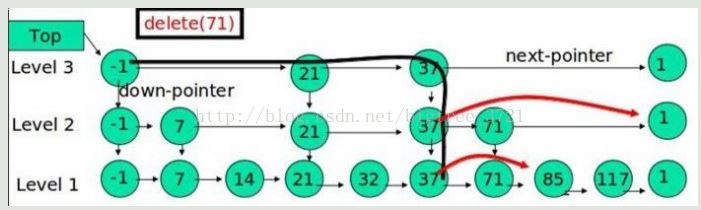
跳錶的刪除
在各個層中找到包含 x 的節點,使用標準的 delete from list 方法刪除該節點。
例子:刪除 71
相關推薦
JAVA SkipList 跳錶 的原理和使用例子
跳錶的原理與特點跳躍連結串列是一種隨機化資料結構,基於並聯的連結串列,其效率可比擬於二叉查詢樹(對於大多數操作需要O(log n)平均時間),並且對併發演算法友好。基本上,跳躍列表是對有序的連結串列增加上附加的前進連結,增加是以隨機化的方式進行的,所以在列表中的查詢可以快速的
Java集合-ConcurrentHashMap工作原理和實現JDK7
概述 本文學習知識點 1.ConcurrentHashMap與HashMap的區別。 2.資料儲存結構。 3.如何提高併發讀寫效能。 4.put和get方法原始碼實現分析。 5.size方法如何實現。 與HashMap的區別 1.ConcurrentHashMap和Ha
Java集合-ConcurrentHashMap工作原理和實現JDK8
概述 本文主要介紹ConcurrentHashMap在JDK8中的原始碼實現和原理。在JDK8中,開發人員幾乎把ConcurrentHashMap的原始碼重寫了一遍,原始碼由之前的2000多行增加到了6300行左右,因此實現也就複雜很多。在學習之前,最好先了解下如下知識: 1、Ree
SkipList跳錶
為什麼選擇跳錶 目前經常使用的平衡資料結構有:B樹,紅黑樹,AVL樹,Splay Tree, Treep等。想象一下,給你一張草稿紙,一隻筆,一個編輯器,你能立即實現一顆紅黑樹,或者AVL樹出來嗎? 很難吧,這需要時間,要考慮很多細節,要參考一堆演算法與資料結構之類的樹,還要參考網上的程式碼,相當麻煩
Java語言跨平臺的原理和Java程式的執行流程
Java語言跨平臺的特殊性: 一般高階語言如要在不同的平臺上執行,需要編譯成不同的目的碼。引入Java虛擬機器後,Java語言在不同平臺上執行時不需要重新編譯。所以Java語言是跨平臺的,此特性也是基於Java虛擬機器的。 Java語言跨平臺性的實現原理:
Java HashMap的工作原理和實現
目錄 概述 HashMap的基本操作如下: map.put("Chinese", 1); map.put("Math", 2); map.put("Englist", 3); map.put("Chemistry", 4); map.pu
Java AOP & Spring AOP 原理和實現
1 定義介面,並建立介面實現類 public interface HelloWorld { void printHelloWorld(); void doPrint(); } public class HelloWorldImpl1 implements HelloWorld {
Java原子類Atomic原理和應用
jdk所提供的原子類可以大致分為四種類型: 原子更新基本資料型別 原子更新陣列型別 原子更新抽象資料型別 原子更新欄位 先來看看jdk提供的原子類(rt.jar包下java.util.concurrent.atomic): 首先我們來寫一個數字自增生成
Java自定義註解(原理和API)初探
今天稍稍學習了下註解,關於註解,我想大家都不陌生,目前可能在hibernate配置中可能會用的多一點,在JPA中也會用到。我想說的是學習註解可以幫助我們更好的理解註解在框架中(比如hibernate和Spirng等)的應用。 Annotation是JDK5版本以來的新特性。目前在JavaSE
Java執行緒池原理和使用
為什麼要用執行緒池? 諸如 Web 伺服器、資料庫伺服器、檔案伺服器或郵件伺服器之類的許多伺服器應用程式都面向處理來自某些遠端來源的大量短小的任務。請求以某種方式到達伺服器,這種方式可能是通過網路協議(例如 HTTP、FTP 或 POP)、通過 JMS 佇列或者可能通過
Java 執行緒池原理和佇列詳解
http://blog.csdn.net/xx326664162/article/details/51701508 執行緒池的框架圖: 1、Executor任務提交介面與Executors工具類 Executor框架同Java.util.
跳錶(SkipList)原理篇
1、什麼是跳錶? 維基百科:跳錶是一種資料結構。它使得包含n個元素的有序序列的查詢和插入操作的平均時間複雜度都是 O(logn),優於陣列的 O(n)複雜度。快速的查詢效果是通過維護一個多層次的連結串列實現的,且與前一層(下面一層)連結串列元素的數量相比,每一層連結串列中的元素的數量更少。 優於陣列的插入
(轉)Java 詳解 JVM 工作原理和流程
移植 獲得 代碼 適配 調用 tac 階段 main方法 等待 作為一名Java使用者,掌握JVM的體系結構也是必須的。說起Java,人們首先想到的是Java編程語言,然而事實上,Java是一種技術,它由四方面組成:Java編程語言、Java類文件格式、Java虛擬機和Ja
Java 詳解 JVM 工作原理和流程
str literal 狀態 應用 流程 href ctu 局部變量 自定義 作為一名Java使用者,掌握JVM的體系結構也是必須的。說起Java,人們首先想到的是Java編程語言,然而事實上,Java是一種技術,它由四方面組成:Java編程語言、Java類文件格式、Jav
Java Token的原理和生成使用機制
=== 舉例 dap 被人 depend 內容 cto contex jws 在此之前我們先了解一下什麽是Cookie、Session、Token 1、什麽是Cookie? cookie指的就是瀏覽器裏面能永久存儲數據的一種數據存儲功能。cookie由服務器生成,發送給瀏
JAVA 動態代理原理和實現
ror binary lose ole jdk 動態代理 參數 try lob rac 在 Java 中動態代理和代理都很常見,幾乎是所有主流框架都用到過的知識。在面試中也是經常被提到的話題,於是便總結了本文。 Java動態代理的基本原理為:被代理對象需要實現某個接口(這是
java——繼承、封裝、多態概念和例子
pub int sta blog ima protect 參考資料 成員方法 order 一、封裝 java是面向對象的語言,為了讓類的內部數據不被隨意的訪問修改,我們會用訪問修飾符對其被訪問權限進行修飾。例如我們經常看見的實體類。裏面的成員變量我們就是用priva
JAVA RMI分布式原理和應用
讀取 create host 實現邏輯 傳遞 not 綁定 per args RMI(Remote Method Invocation)是JAVA早期版本(JDK 1.1)提供的分布式應用解決方案,它作為重要的API被廣泛的應用在EJB中。隨著互聯網應用的發展,分布式
Java:Future、Callable和FutureTask原理解析(學習筆記)
Future表示一個任務的生命週期,並提供了方法來判斷是否已經完成或取消,以及獲取任務的結果和取消任務等。Future介面: public interface Future<V> { boolean cancel(boolean mayInterruptIfRunni