
solr全文檢索實現原理
solr那是我1年前使用到的一個搜尋引擎,由於當初對於配置了相應了,但是今天突然面試問到了,哎,太久了,真的忘記了,今天特地寫一篇部落格記下來
solr是一個獨立的企業級搜尋應用伺服器,它對外t提供類似於web-service的api介面。使用者可以通過http請求,向搜尋引擎伺服器提交一定格式的xml檔案,生成索引。;
也可以通過http get操作提出查詢的請求,得到xml/json格式的返回結果
Lucene是一個高效的,基於Java的全文檢索庫。
所以在瞭解Lucene之前要費一番工夫瞭解一下全文檢索。
那麼什麼叫做全文檢索呢?這要從我們生活中的資料說起。
我們生活中的資料總體分為兩種:結構化資料
- 結構化資料:指具有固定格式或有限長度的資料,如資料庫,元資料等。
- 非結構化資料:指不定長或無固定格式的資料,如郵件,word文件等。
當然有的地方還會提到第三種,半結構化資料,如XML,HTML等,當根據需要可按結構化資料來處理,也可抽取出純文字按非結構化資料來處理。
非結構化資料又一種叫法叫全文資料。
按照資料的分類,搜尋也分為兩種:
- 對結構化資料的搜尋:如對資料庫的搜尋,用SQL語句。再如對元資料的搜尋,如利用windows搜尋對檔名,型別,修改時間進行搜尋等。
- 對非結構化資料的搜尋:如利用windows的搜尋也可以搜尋檔案內容,Linux下的grep命令,再如用Google和百度可以搜尋大量內容資料。
對非結構化資料也即對全文資料的搜尋主要有兩種方法:
一種是順序掃描法(Serial Scanning):所謂順序掃描,比如要找內容包含某一個字串的檔案,就是一個文件一個文件的看,對於每一個文件,從頭看到尾,如果此文件包含此字串,則此文件為我們要找的檔案,接著看下一個檔案,直到掃描完所有的檔案。如利用windows的搜尋也可以搜尋檔案內容,只是相當的慢。如果你有一個80G硬碟,如果想在上面找到一個內容包含某字串的檔案,不花他幾個小時,怕是做不到。Linux下的grep命令也是這一種方式。大家可能覺得這種方法比較原始,但對於小資料量的檔案,這種方法還是最直接,最方便的。但是對於大量的檔案,這種方法就很慢了。
有人可能會說,對非結構化資料順序掃描很慢,對結構化資料的搜尋卻相對較快(由於結構化資料有一定的結構可以採取一定的搜尋演算法加快速度),那麼把我們的非結構化資料想辦法弄得有一定結構不就行了嗎?
這種想法很天然,卻構成了全文檢索的基本思路,也即將非結構化資料中的一部分資訊提取出來,重新組織,使其變得有一定結構,然後對此有一定結構的資料進行搜尋,從而達到搜尋相對較快的目的。
這部分從非結構化資料中提取出的然後重新組織的資訊,我們稱之索引。
這種說法比較抽象,舉幾個例子就很容易明白,比如字典,字典的拼音表和部首檢字表就相當於字典的索引,對每一個字的解釋是非結構化的,如果字典沒有音節表和部首檢字表,在茫茫辭海中找一個字只能順序掃描。然而字的某些資訊可以提取出來進行結構化處理,比如讀音,就比較結構化,分聲母和韻母,分別只有幾種可以一一列舉,於是將讀音拿出來按一定的順序排列,每一項讀音都指向此字的詳細解釋的頁數。我們搜尋時按結構化的拼音搜到讀音,然後按其指向的頁數,便可找到我們的非結構化資料——也即對字的解釋。
這種先建立索引,在對索引進行搜尋的過程就叫做全文檢索。全文檢索大體分為2個過程,索引建立和搜尋索引
1.索引建立:將現實世界中的所有結構化和非結構化資料提取資訊,建立索引的過程
2.索引索引:就是得到使用者查詢的請求,搜尋建立的索引,然後返回結果的過程
於是全文檢索就存在3個重要的問題:
1. 索引裡面究竟存了什麼東西?
2.如何建立索引?
3.如何對索引進行搜尋?
下面我們順序對每個個問題進行研究。
二、索引裡面究竟存些什麼
索引裡面究竟需要存些什麼呢?
首先我們來看為什麼順序掃描的速度慢:
其實是由於我們想要搜尋的資訊和非結構化資料中所儲存的資訊不一致造成的。
非結構化資料中所儲存的資訊是每個檔案包含哪些字串,也即已知檔案,欲求字串相對容易,也即是從檔案到字串的對映。而我們想搜尋的資訊是哪些檔案包含此字串,也即已知字串,欲求檔案,也即從字串到檔案的對映。兩者恰恰相反。於是如果索引總能夠儲存從字串到檔案的對映,則會大大提高搜尋速度。
由於從字串到檔案的對映是檔案到字串對映的反向過程,於是儲存這種資訊的索引稱為反向索引。
反向索引的所儲存的資訊一般如下:
假設我的文件集合裡面有100篇文件,為了方便表示,我們為文件編號從1到100,得到下面的結構
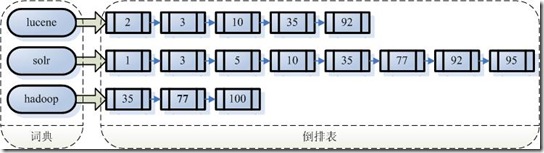
左邊儲存的是一系列字串,稱為詞典。
每個字串都指向包含此字串的文件(Document)連結串列,此文件連結串列稱為倒排表(Posting List)。
有了索引,便使儲存的資訊和要搜尋的資訊一致,可以大大加快搜索的速度。
比如說,我們要尋找既包含字串“lucene”又包含字串“solr”的文件,我們只需要以下幾步:
1. 取出包含字串“lucene”的文件連結串列。
2. 取出包含字串“solr”的文件連結串列。
3. 通過合併連結串列,找出既包含“lucene”又包含“solr”的檔案。

看到這個地方,有人可能會說,全文檢索的確加快了搜尋的速度,但是多了索引的過程,兩者加起來不一定比順序掃描快多少。的確,加上索引的過程,全文檢索不一定比順序掃描快,尤其是在資料量小的時候更是如此。而對一個很大量的資料建立索引也是一個很慢的過程。
然而兩者還是有區別的,順序掃描是每次都要掃描,而建立索引的過程僅僅需要一次,以後便是一勞永逸的了,每次搜尋,建立索引的過程不必經過,僅僅搜尋建立好的索引就可以了。
這也是全文搜尋相對於順序掃描的優勢之一:一次索引,多次使用。
三、如何建立索引
全文檢索的索引建立過程一般有以下幾步:
第一步:一些要索引的原文件(Document)。
為了方便說明索引建立過程,這裡特意用兩個檔案為例:
檔案一:Students should be allowed to go out with their friends, but not allowed to drink beer.
檔案二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第二步:將原文件傳給分次元件(Tokenizer)。
分片語件(Tokenizer)會做以下幾件事情(此過程稱為Tokenize):
1. 將文件分成一個一個單獨的單詞。
2. 去除標點符號。
3. 去除停詞(Stop word)。
所謂停詞(Stop word)就是一種語言中最普通的一些單詞,由於沒有特別的意義,因而大多數情況下不能成為搜尋的關鍵詞,因而建立索引時,這種詞會被去掉而減少索引的大小。
英語中挺詞(Stop word)如:“the”,“a”,“this”等。
對於每一種語言的分片語件(Tokenizer),都有一個停詞(stop word)集合。
經過分詞(Tokenizer)後得到的結果稱為詞元(Token)。
在我們的例子中,便得到以下詞元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
第三步:將得到的詞元(Token)傳給語言處理元件(Linguistic Processor)。
語言處理元件(linguistic processor)主要是對得到的詞元(Token)做一些同語言相關的處理。
對於英語,語言處理元件(Linguistic Processor)一般做以下幾點:
1. 變為小寫(Lowercase)。
2. 將單詞縮減為詞根形式,如“cars”到“car”等。這種操作稱為:stemming。
3. 將單詞轉變為詞根形式,如“drove”到“drive”等。這種操作稱為:lemmatization
第四步:將得到的詞(Term)傳給索引元件(Indexer)。等等總而言之
1. 索引過程:
1) 有一系列被索引檔案
2) 被索引檔案經過語法分析和語言處理形成一系列詞(Term)。
3) 經過索引建立形成詞典和反向索引表。
4) 通過索引儲存將索引寫入硬碟。
2. 搜尋過程:
a) 使用者輸入查詢語句。
b) 對查詢語句經過語法分析和語言分析得到一系列詞(Term)。
c) 通過語法分析得到一個查詢樹。
d) 通過索引儲存將索引讀入到記憶體。
e) 利用查詢樹搜尋索引,從而得到每個詞(Term)的文件連結串列,對文件連結串列進行交,差,並得到結果文件。
f) 將搜尋到的結果文件對查詢的相關性進行排序。
g) 返回查詢結果給使用者。
相關推薦
solr全文檢索實現原理
solr那是我1年前使用到的一個搜尋引擎,由於當初對於配置了相應了,但是今天突然面試問到了,哎,太久了,真的忘記了,今天特地寫一篇部落格記下來 solr是一個獨立的企業級搜尋應用伺服器,它對外t提供類似於web-service的api介面。使用者可以通過http請求,向搜尋
全文檢索引擎SOLR—–全文檢索基本原理
場景:小時候我們都使用過新華字典,媽媽叫你翻開第38頁,找到“坑爹”所在的位置,此時你會怎麼查呢?毫無疑問,你的眼睛會從38頁的第一個字開始從頭至尾地掃描,直到找到“坑爹”二字為止。這種搜尋方法叫做順序掃描法。對於少量的資料,使用順序掃描是夠用的。但是媽媽叫你查出坑爹的“
基於python+whoosh的全文檢索實現
whoosh的官方介紹:http://whoosh.readthedocs.io/en/latest/quickstart.html 因為做的是中文的全文檢索需要匯入jieba工具包以及whoosh工具包 直接上程式碼吧 from whoosh.qparser import QueryPa
Solr全文檢索伺服器
solr介紹 一、Solr它是一種開放原始碼的、基於 Lucene Java 的搜尋伺服器,易於加入到 Web 應用程式中。 二、Solr 提供了層面搜尋(就是統計)、命中醒目顯示並且支援多種輸出格式(包括XML/XSLT 和JSON等格式)。它易於安裝和配置,而且附帶了
solr全文檢索隨筆
solr的專案配置步驟 (1)在F:\fullsearch\solr\apache-tomcat-8.0.52\webapps\solr\WEB-INF中的web.xml 修改指向solrhome路徑 <env-entry>
java中solr全文檢索的使用
採用SolrInputDocument物件增加、刪除索引 import java.util.ArrayList; import java.util.Collection; import java.util.List; import org.apache.solr.c
solr全文檢索入門
文章目錄 安裝 啟動 建立core 配置core索引MySQL資料 3.2.1 3.2.2 3.2.3 測試定時更新 五、配置中文分詞 SolrJ 操作索引的增
solr全文檢索應用例項
環境:nginx、solr Lnmp環境的安裝:略 Solr 安裝: 準備檔案 jdk-8u101-linux-x64.tar.gz、apache-tomcat-8.5.4.zip、solr-4.2.1.tgz 安裝jdk: 解壓jdk tar -zxvf jdk-8u
solr全文檢索技術學習(三)-搭建SolrCloud叢集問題總結
什麼是SolrCloud SolrCloud(solr 雲)是Solr提供的分散式搜尋方案,當你需要大規模,容錯,分散式索引和檢索能力時使用 SolrCloud。當一個系統的索引資料量少的時候是不需要使用SolrCloud的,當索引量很大,搜尋請求併發
【搜尋引擎】Solr全文檢索近實時查詢優化
設定多個搜尋建議查詢演算法 <searchComponent name="suggest" class="solr.SuggestComponent"> <lst name="suggester"> &l
solr全文檢索學習
序言: 前面我們說了全域性檢索Lucene,但是我們發現Lucene在使用上還是有些不方便的,例如想要看索引的內容時,就必須自己調api去查,再例如一些新增文件,需要寫的程式碼還是比較多的 另外我們之前說過Lucene只是一個全文檢索的工具包,並不算一個完整的搜尋引擎。很多功能還是需要我們自己去
Lucene全文檢索之倒排索引實現原理、API解析【2018.11】
》 官網 http://lucene.apache.org/ 下載地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/7.5.0/ 》 Lucene的全文檢索是指什麼: 程式掃描文件
基於solr實現商品資訊的全文檢索(windwons)
搭建環境 windows下tomcat+solr 相關軟體準備 1.安裝JDK 2.下載tomcat 3.下載solr-4.10.3.tgz.tgz 4.下載IK分詞器(IKAnalyzer2012FF_hf1.rar) 安裝步驟
【搜尋引擎】Solr Suggester 實現全文檢索功能-分詞和和自動提示
功能需求 全文檢索搜尋引擎都會有這樣一個功能:輸入一個字元便自動提示出可選的短語: 要實現這種功能,可以利用solr的SuggestComponent,SuggestComponent這種方法利用Lucene的Suggester實現,並支援Lucene中可用的所有查詢實現。 實現 1. 配置 manage
oracle仿全文檢索切詞機制實現文本信息類似度查找
pos rom 排除 應用場景 popu ora mar 機制 一個 應用場景: 依據keyword查詢與此keyword相似的信息,當中一些keyword要排除掉比如:“有限公司”、“有限責任公司”、“股份有限公司”等
全文檢索技術---solr
可擴展 spa start common sha https 站內搜索 請求方法 效果 1 Solr介紹 1.1 什麽是solr Solr 是Apache下的一個頂級開源項目,采用Java開發,它是基於Lucene的全文搜索服務器。Solr可以獨立運行在
搜素引擎全文檢索原理
alias img 結構化 com 數據結構 sql lis count jpg 一 全文檢索介紹 先建立索引,再對索引進行搜索的過程就叫全文檢索 搜索引擎核心:建立倒排索引 二 數據庫和 solor搜索引擎對比 1 搜索引擎的索引和 數據庫索引區別 原理相通,只是索引結構
全文檢索的基本原理
pop align 這一 所有 人性 pad 維數 兩個人 img 全文檢索的基本原理 2017年03月15日 22:23:49 閱讀數:8067 一、總論 根據http://lucene.apache.org/java/docs/index.html 定義:
lnmp+coreseek實現站內全文檢索(安裝篇)
lec into .... 第一次 undefine 庫類 rwx rtm ocs 軟件安裝包 安裝環境 系統環境 centos7.2 1核2G 軟件環境 coreseek-3.2.14 lnmp1.5 安裝mmseg 更新依賴包和安裝編譯環境 y
實戰2000W條資料實現全文檢索
一) 前期準備測試: 舊版的MySQL的全文索引只能用在MyISAM表格的char、varchar和text的欄位上。 不過新版的MySQL5.6.24上InnoDB引擎也加入了全文索引,所以具體資訊要隨時關注官網,下載mySql5.7 直接使用,可