
入坑爬蟲(五)Requests庫處理cookie
requess模組處理cookie相關的請求
爬蟲中使用cookie
為了能夠通過爬蟲獲取到登入後的頁面,或者是解決通過cookie的反扒,需要使用request來處理cookie相關的請求
爬蟲中使用cookie的利弊
能夠訪問登入後的頁面
能夠實現部分反反爬帶上cookie的壞處:
一套cookie往往對應的是一個使用者的資訊,請求太頻繁有更大的可能性被對方識別為爬蟲
那麼上面的問題如何解決 ?使用多個賬號requests處理cookie的方法
使用requests處理cookie有三種方法:
cookie字串放在headers中
把cookie字典放傳給請求方法的cookies引數接收
使用requests提供的session模組cookie新增在heades中
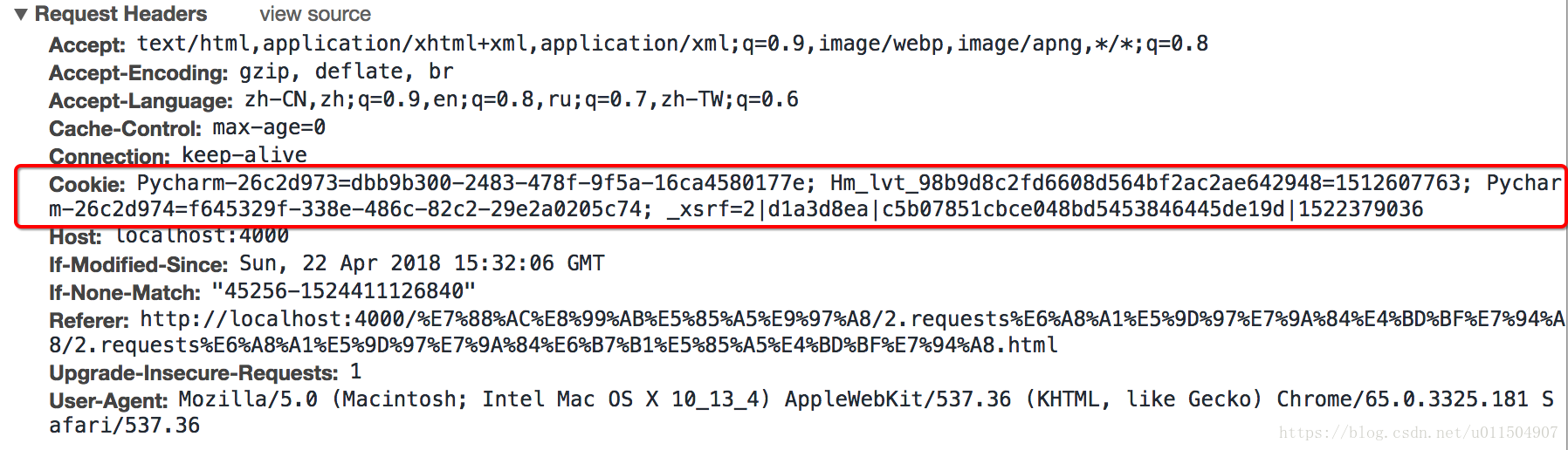
在headers中使用cookie
headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36", "Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"} requests.get(url,headers=headers)注意:
cookie有過期時間 ,所以直接複製瀏覽器中的cookie可能意味著下一程式繼續執行的時候需要替換程式碼中的cookie,對應的我們也可以通過一個程式專門來獲取cookie供其他程式使用;當然也有很多網站的cookie過期時間很長,這種情況下,直接複製cookie來使用更加簡單使用cookies引數接收字典形式的cookie
cookies的形式:字典cookies = {"cookie的name":"cookie的value"} 使用方法: requests.get(url,headers=headers,cookies=cookie_dict}使用requests.session處理cookie
前面使用手動的方式使用cookie,那麼有沒有更好的方法在requets中處理cookie呢?
requests 提供了一個叫做session類,來實現客戶端和服務端的會話保持
會話保持有兩個內涵:
儲存cookie,下一次請求會帶上前一次的cookie
實現和服務端的長連線,加快請求速度使用方法
session = requests.session()
response = session.get(url,headers)
session例項在請求了一個網站後,對方伺服器設定在本地的cookie會儲存在session中,下一次再使用session請求對方伺服器的時候,會帶上前一次的cookie動手練習一下:
動手嘗試使用session來登入人人網: http://www.renren.com/PLogin.do (先不考慮這個url地址從何而來),請求體的格式:{“email”:”username”, “password”:”password”}
思路分析
準備url地址和請求引數
構造session傳送post請求
使用session請求個人主頁,觀察是否請求成功原始碼
#coding:utf-8 import requests import re url = 'http://www.renren.com/PLogin.do' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', } post_data = { 'email':'此處填寫賬號', 'password': '此處填寫密碼' } # 建立session物件 session = requests.Session() session.headers = headers # 傳送post請求,模擬登陸 session.post(url, data=post_data) # 驗證登入 response = session.get('此處填寫人人網個人中心頁面的url') print(response.url)
相關推薦
入坑爬蟲(五)Requests庫處理cookie
requess模組處理cookie相關的請求 爬蟲中使用cookie 為了能夠通過爬蟲獲取到登入後的頁面,或者是解決通過cookie的反扒,需要使用request來處理cookie相關的請求 爬蟲中使用cookie的利弊 能夠訪問登入後的頁面 能夠實現
Python爬蟲之requests庫(五):Cookie、超時、重定向和請求歷史
import requests 一、Cookie 獲取伺服器響應中的cookie資訊 url = 'http://example.com/some/cookie/setting/url'
爬蟲之requests庫
響應 image ocs dex ren 人性化 setting req ems Why requests python的標準庫urllib2提供了大部分需要的HTTP功能,但是API太逆天了,一個簡單的功能就需要一大堆代碼。 Requests 使用的是 urllib3
爬蟲基礎(requests庫的基本使用)--02
證書 wid text 關系 info 簡單 出現 storage 傳遞數據 什麽是Requests Requests是用python語言基於urllib編寫的,采用的是Apache2 Licensed開源協議的HTTP庫如果你看過上篇文章關於urllib庫的使用,你會發現
【Python爬蟲】Requests庫的安裝
comm AS imp pypi pan span douban OS host 1.按照普通的pip不能行,說find不能 有位小傑控的大牛說了一句:換一個國內的更新源吧, pip install requests -i http://pypi.douban.com/si
爬蟲入門requests庫疑惑
nbsp 疑惑 url style code class sougou clas req kv={‘query‘:‘小明‘,‘query‘:‘小麗‘} r=requests.get(‘www.sougou.com/‘,params=kv) print(r.url)
爬蟲之 Requests庫的基本使用
什麼是Requests Requests是用python語言基於urllib編寫的,採用的是Apache2 Licensed開源協議的HTTP庫如果你看過上篇文章關於urllib庫的使用,你會發現,其實urllib還是非常不方便的,而Requests它會比urllib更加方便,可以節約我們大量的工作
【 爬蟲】Requests 庫的入門學習
此為北理嵩天老師mooc課程【網路爬蟲與資訊提取】的課程學習筆記,附帶一些其他書籍部落格的資料。 1、安裝 Requests 庫 使用命令列輸入: pip install requests 或者: python -m pip install requests 2
Cookiejar 庫處理 cookie 儲存回話視窗的登陸狀態
像什麼知乎,酷狗,拉鉤這些大網站,模擬登陸有點複雜,所以還是學校的教務系統最友好 目錄 1.無 cookie 處理模擬登陸教務系統 import urllib.request import urllib.parse url = 'http://es.bn
Python網路爬蟲之requests庫Scrapy爬蟲比較
requests庫Scrapy爬蟲比較 相同點: 都可以進行頁面請求和爬取,Python爬蟲的兩個重要技術路線 兩者可用性都好,文件豐富,入門簡單。 兩者都沒有處理JS,提交表單,應對驗證碼等功能(可擴充套件) 想爬取有驗證碼的,換需要學習別的庫知識。 不同點: Scrapy,非同
Python爬蟲之Requests庫的基本使用
1 import requests 2 response = requests.get('http://www.baidu.com/') 3 print(type(response)) 4 print(response.status_code) 5 print(type(respon
Python爬蟲系列-Requests庫詳解
Requests基於urllib,比urllib更加方便,可以節約我們大量的工作,完全滿足HTTP測試需求。 例項引入 import requests response = requests.get('https://www.baidu.com/') print(type(response))
爬蟲之Requests庫應用例項
1.京東商品頁的爬取 import requests url = "https://item.jd.com/100000400014.html" try: r = requests.get(url) r.raise_for_status()
第十二章避開採集的陷阱 使用selenium庫處理cookie
#!/usr/bin/env python # _*_ coding:utf-8 _*_ #根據cookie訪問網站 #思路:第一個webdriver獲取網站和cookie,然後第二個web網站載入同一
【爬蟲】Requests 庫的入門學習
此為北理嵩天老師mooc課程【網路爬蟲與資訊提取】的課程學習筆記。 1安裝 Requests 庫 使用命令列輸入: pip install requests 或者: python -m pip install requests 2 requests 的常用
python爬蟲之requests庫詳解(一,如何通過requests來獲得頁面資訊)
前言: 爬蟲的基礎是與網頁建立聯絡,而我們可以通過get和post兩種方式來建立連線,而我們可以通過引入urllib庫[在python3的環境下匯入的是urllib;而python2的環境下是urllib和urllib2]或者requests庫來實現,從程式的複雜度和可讀性
[python爬蟲學習] requests庫的使用
前言 昨天寫了一下爬蟲,但發現requests庫的使用有些忘了,所以準備記錄下來!! 稍微介紹下,給第一次接觸這個庫的人。 您肯定經常看到urllib,urllib2,這些python標準庫。requests庫的功能其實和它們差不多,但方便上手,容易學習!!!
Python 爬蟲基礎Requests庫的使用(二十一)
(一)人性化的Requests庫 在Python爬蟲開發中最為常用的庫就是使用Requests實現HTTP請求,因為Requests實現HTTP請求簡單、操作更為人性化。 (二)get請求的基本用法 def get(url, params=N
入坑爬蟲(六)某招聘網站資訊採集
前面的章節中,我們說到了如何傳送傳送,對應的,回顧之前的爬蟲流程,在傳送完請求之後,能夠獲取響應,這個時候就需要從響應中提取資料了. 1. 爬蟲中資料的分類 在爬蟲爬取到的資料中有很多不同型別的資料,我們需要了解資料的不同型別來規律的提取和解析資料. 根據響應的
Python爬蟲之requests庫(三):傳送表單資料和JSON資料
import requests 一、傳送表單資料 要傳送表單資料,只需要將一個字典傳遞給引數data payload = {'key1': 'value1', 'key2': 'value