
入坑爬蟲(六)某招聘網站資訊採集
前面的章節中,我們說到了如何傳送傳送,對應的,回顧之前的爬蟲流程,在傳送完請求之後,能夠獲取響應,這個時候就需要從響應中提取資料了.
1. 爬蟲中資料的分類
在爬蟲爬取到的資料中有很多不同型別的資料,我們需要了解資料的不同型別來規律的提取和解析資料.
根據響應的內容,我們可以將獲得到的資料分為以下兩類:
-
結構化資料:json,xml等
- 處理方式:直接轉化為python型別
-
非結構化資料:HTML
- 處理方式:正則表示式、xpath
下面以某條的首頁為例,介紹結構化資料和非結構化資料
-
結構化資料例子:
-
非結構化資料:

我們可以看到,第一張圖我們捕獲到的資訊是JSON格式的,那什麼是JSON呢?
JSON(JavaScript Object Notation) 是一種輕量級的資料交換格式,它使得人們很容易的進行閱讀和編寫。同時也方便了機器進行解析和生成。適用於進行資料互動的場景,比如網站前臺與後臺之間的資料互動。
我們可以在Python中匯入JSON庫來解析.方法如下:
import json
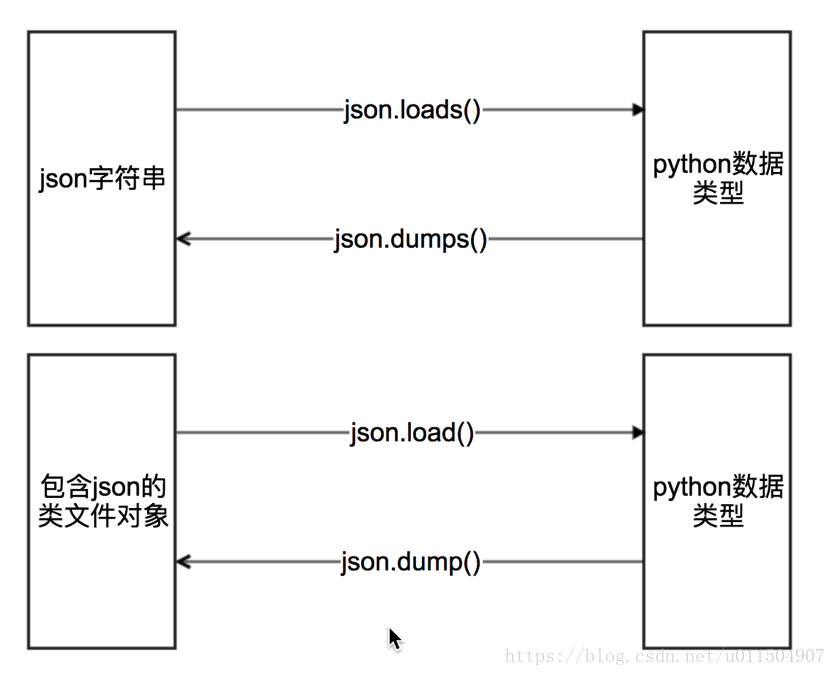
json有四個方法供我們進行資料轉換:
一般常用的就是前兩種.
mydict = {'name': 'xiaoming', 'age': 18} #json.dumps 實現python型別轉化為json字串 json_str = json.dumps(mydict) #json.loads 實現json字串轉化為python的資料型別 my_dict = json.loads(json_str) #json.dump 實現把python型別寫入類檔案物件 with open("temp.txt","w") as f: json.dump(mydict,f,ensure_ascii=False,indent=2) # json.load 實現類檔案物件中的json字串轉化為python型別 with open("temp.txt","r") as f: my_dict = json.load(f)
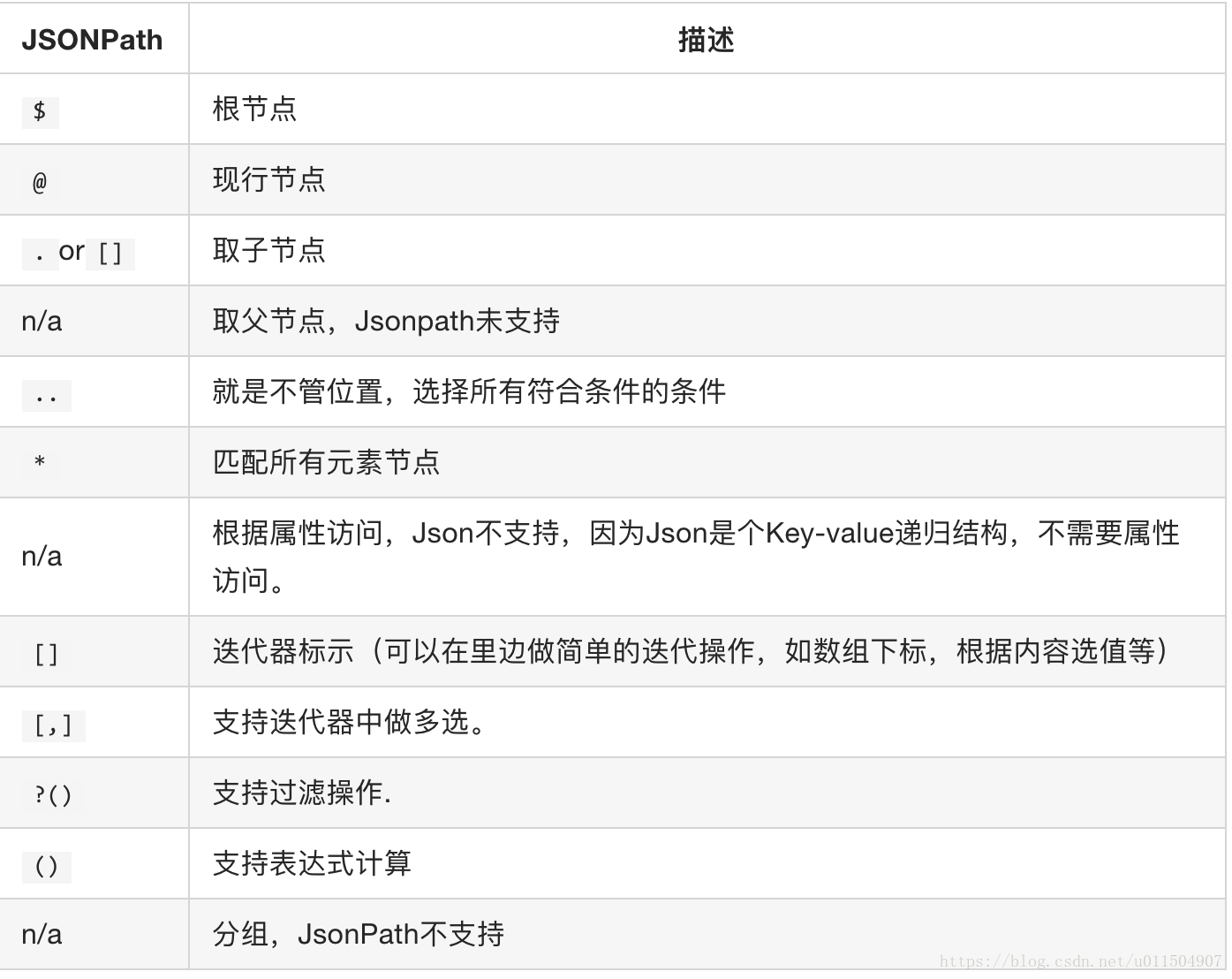
jsonpath模組
JsonPath 模組是用來解析多層巢狀的json資料;
JsonPath 是一種資訊抽取類庫,是從JSON文件中抽取指定資訊的工具,提供多種語言實現版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 對於 JSON 來說,相當於 XPath 對於 XML。
安裝方法:pip install jsonpath
官方文件:http://goessner.net/articles/JsonPath
JsonPath與XPath語法對比:
import requests import jsonpath import json url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json' response =requests.get(url) html_str = response.content.decode() # 把json格式字串轉換成python物件 jsonobj = json.loads(html_str) # 從根節點開始,匹配name節點 citylist = jsonpath.jsonpath(jsonobj,'$..name') fp = open('city.json','wb') content = json.dumps(citylist, ensure_ascii=False) fp.write(content.encode('utf-8')) fp.close()
原始碼:
import requests
import jsonpath
import json
import time
class LaGou(object):
def __init__(self, work):
self.url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput='
}
self.proxies = {
'http': 'http://219.141.153.36'
}
self.work = work
self.file = open('work.json', 'w', encoding='utf-8')
def get_data(self, url, count):
session = requests.session()
data = {
'first': 'true',
'pn': str(count),
'kd': self.work
}
r = session.post(url, headers=self.headers, data=data)
print(r.status_code)
return r.content
def parse_data(self, data):
data_dict = json.loads(data.decode())
result = jsonpath.jsonpath(data_dict, '$..positionResult.result')
details_url = []
for res in result:
for content in res:
temp = dict()
temp['company'] = content['companyFullName']
temp['work'] = content['positionName']
temp['education'] = content['education']
temp['salary'] = content['salary']
temp['CreateTime'] = content['formatCreateTime']
temp['details_url'] = 'https://www.lagou.com/jobs/' + str(content['positionId']) + '.html'
details_url.append(temp)
return details_url
def save_data(self, work):
data = json.dumps(work, ensure_ascii=False) + ',\r'
self.file.write(data)
def __del__(self):
self.file.close()
def run(self):
url = self.url
count = 0
while True:
count += 1
time.sleep(4)
data = self.get_data(url, count)
work_list = self.parse_data(data)
print('正在儲存第{}頁資料!'.format(count))
for work in work_list:
self.save_data(work)
print('儲存完畢')
print('--------------------------------')
if __name__ == '__main__':
lagou = LaGou('爬蟲')
lagou.run()
相關推薦
入坑爬蟲(六)某招聘網站資訊採集
前面的章節中,我們說到了如何傳送傳送,對應的,回顧之前的爬蟲流程,在傳送完請求之後,能夠獲取響應,這個時候就需要從響應中提取資料了. 1. 爬蟲中資料的分類 在爬蟲爬取到的資料中有很多不同型別的資料,我們需要了解資料的不同型別來規律的提取和解析資料. 根據響應的
Python爬蟲——4.4爬蟲案例——requests和xpath爬取招聘網站資訊
# -*-coding:utf-8 -*- ''' 使用requests模組進行資料採集,XPath進行資料篩選''' import requests from lxml import etree #
爬取某招聘網站的招聘資訊(獵聘)
這該找工作了,俗話說的胡奧,金九銀十嘛。一個一個招聘資訊找著看,有點麻煩。所以心動了下,不如把我想找的資訊都爬取下來,直接sql語句查詢所有相關資訊,多方便,是吧~ 注: 如果start-urls只設置一個的話,那麼只會爬取等於或者小於40條資料
某招聘網站職位分析專案操作整理
考察的知識點:Excel函式、圖表、資料透視表 這是一份某求職網站上關於資料分析的資料 求每家公司的最高薪資和最低薪資以及平均薪資 最低薪資:=IF(ISBLANK(D2),"",LEFT(D2,FIND("k",D2)-1)) 最高薪資:=IF(ISBLANK(D
Excel函式,資料透視表圖,某招聘網站職位分析專案
求每家公司的最高薪資和最低薪資以及平均薪資 將職位包含資料分析、資料運營、分析師等的公司找出來 獲取每家公司對應的公司地址放到Sheet1表裡顯示出來 得到一些具體資料:最低薪資大於15K的公司一共有多少家和最高薪資低於15K的公司一共有多少家 根據公司規模判斷該公司屬於大公司、中公司還是小公司
某招聘網資訊統計視覺化
0x00 前言 資料截至:2016.02.23 你應該猜到是哪個網站了,用python3寫了個多執行緒(非同步也不錯)+多代理爬蟲,大致實現是在執行中不斷往資料庫加入新代理,在獲取中把無效代理去掉及將任務ID添加回佇列,最後剩下穩定的代理迴圈使用,也
利用scrapy輕鬆爬取招聘網站資訊並存入MySQL
前言 Scrapy版本:1.4; Python版本:3.6; OS:win10; 本文完整專案程式碼:完整示例; 本文目標: 通過爬取騰訊招聘網站招聘崗位,熟悉scrapy,並掌握資料庫儲存操作; 一、準備工作 ♣ 基礎工作 首先你要安裝S
入坑爬蟲(五)Requests庫處理cookie
requess模組處理cookie相關的請求 爬蟲中使用cookie 為了能夠通過爬蟲獲取到登入後的頁面,或者是解決通過cookie的反扒,需要使用request來處理cookie相關的請求 爬蟲中使用cookie的利弊 能夠訪問登入後的頁面 能夠實現
Kotlin入坑(六)函式
函式宣告 使用 fun 關鍵字 引數使用 name: type 的形式表示 左邊是引數的名字 右邊是引數的型別,最後的冒號後面代表返回值的型別。如果這個函式沒有返回值可以省略或者使用Unit 代替 fun double(x: Int): Int {
如何用爬蟲抓取招聘網站的職位並分析
最近有不少程式設計師又開始找工作了,為了瞭解目前技術類各職位的數量、薪資、招聘公司、崗位職責及要求,我爬取了拉勾網北上廣深4個城市的招聘資料,共3w條。職位包括:人工智慧(AI)、大資料、資料分析、後端(Java、C|C++、PHP、Python)、前端、Android、iOS、嵌入式和測試。下面我將分兩部分
Python爬蟲獲取招聘網站職位資訊
作為一名Pythoner,相信大家對Python的就業前景或多或少會有一些關注。索性我們就寫一個爬蟲去獲取一些我們需要的資訊,今天我們要爬取的是前程無憂!說幹就幹!進入到前程無憂的官網,輸入關鍵字“Python”,我們會得到下面的頁面 我們可以看到這裡羅列了"職位名"、"公司名"、"工作地
網路爬蟲之scrapy爬取某招聘網手機APP釋出資訊
1 引言 2 APP抓包分析 3 編寫爬蟲昂 4 總結 1 引言 過段時間要開始找新工作了,爬取一些崗位資訊來分析一下吧。目前主流的招聘網站包括前程無憂、智聯、BOSS直聘、拉勾等等。有
使用sqlmap對某php網站進行註入實戰及安全防範
使用sqlmap php註入 滲透實戰 使用sqlmap對某php網站進行註入實戰 一般來講一旦網站存在sql註入漏洞,通過sql註入漏洞輕者可以獲取數據,嚴重的將獲取webshell以及服務器權限,但在實際漏洞利用和測試過程中,也可能因為服務器配置等情況導致無法獲取權限。1.1php註入點的
Python爬蟲:爬取網站電影資訊
以爬取電影天堂喜劇片前5頁資訊為例,程式碼如下: 1 # coding:UTF-8 2 3 import requests 4 import re 5 6 def mov(): 7 headers={'User-Agent':'Mozilla/5.0 (Windo
[Python] [爬蟲] 1.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲概要——脫離Scrapy框架
目錄 1.Intro 2.Details 3.Theory 4.Environment and Configuration 5.Automation 6.Conclusion 1.Intro 作為Python的擁蹩,開源支持者,深信Python大
[Python] [爬蟲] 10.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——排程引擎
目錄 1.Intro 2.Source 1.Intro 檔名:scheduleEngine.py 模組名:排程引擎 引用庫: random time gc os sys date
[Python] [爬蟲] 9.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——爬蟲日誌
目錄 1.Intro 2.Source 1.Intro 檔名:spiderLog.py 模組名:爬蟲日誌 引用庫: logging 功能:日誌寫入到文字,包含普通訊息、警告、錯誤、異常等,可以跟蹤爬蟲執行過程。 &nb
[Python] [爬蟲] 8.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——資料推送模組
目錄 1.Intro 2.Source (1)dataPusher (2)dataPusher_HTML 1.Intro 檔名:dataPusher.py、dataPusher_HTML.py 模組名:資料推送模組 引用庫: smtpl
[Python] [爬蟲] 7.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——資料處理器
目錄 1.Intro 2.Source 1.Intro 檔名:dataDisposer.py 模組名:資料處理器 引用庫: pymongo datetime time sys
[Python] [爬蟲] 6.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——網頁解析器
目錄 1.Intro 2.Source 1.Intro 檔名:pageResolver.py 模組名:網頁解析器 引用庫: re lxml datetime sys retry