
短文字分析----基於python的TF-IDF特徵詞標籤自動化提取
緒論
最近做課題,需要分析短文字的標籤,在短時間內學習了自然語言處理,社會標籤推薦等非常時髦的技術。我們的需求非常類似於從大量短文字中獲取關鍵詞(融合社會標籤和時間屬性)進行使用者畫像。這一切的基礎就是特徵詞提取技術了,本文主要圍繞關鍵詞提取這個主題進行介紹(英文)。
不同版本python混用(官方用法)
Python2 和python3 是一個神一般的存在,如何讓他們共存呢,直到我用了pycharm我才知道為啥這麼多人選擇它,如下圖所示配置兩個目錄直接可以混用了,叼炸天。
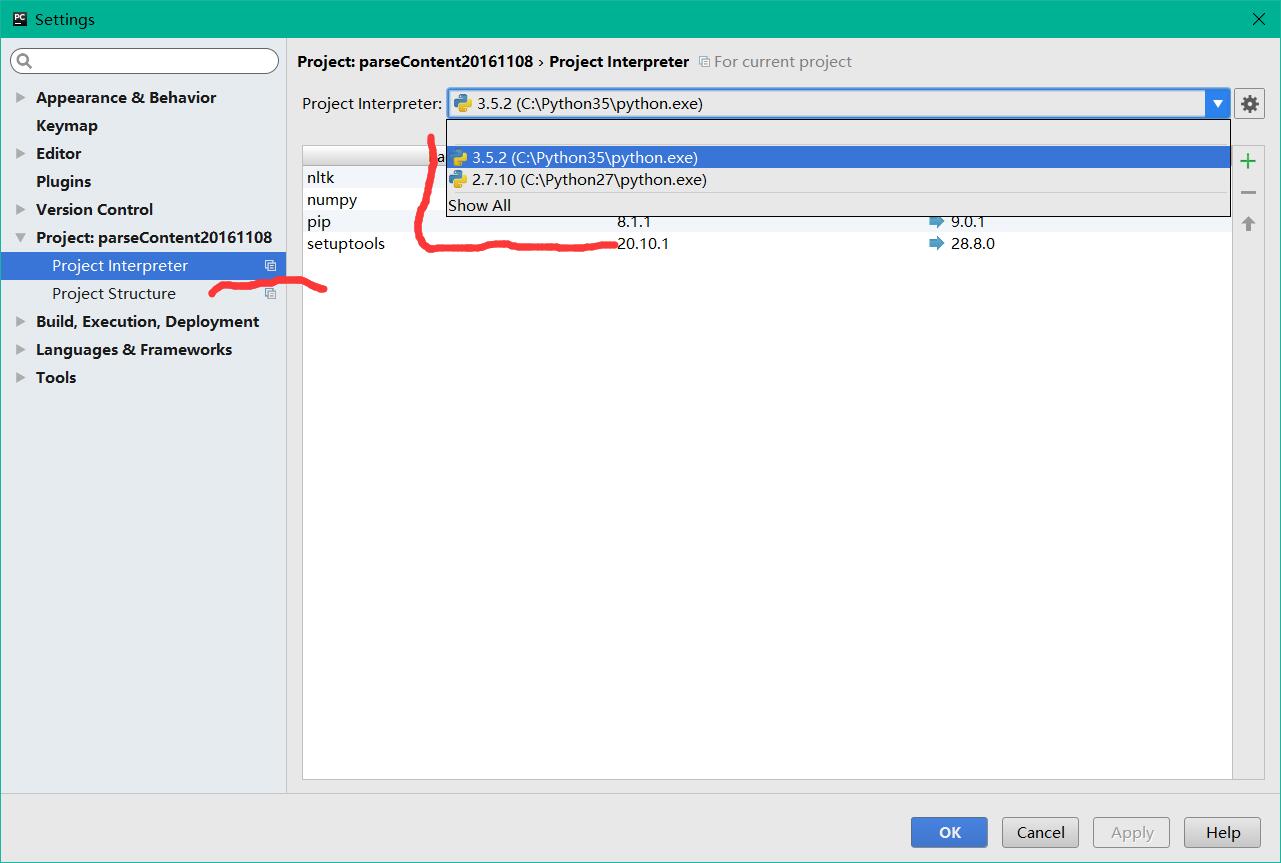
插播一個廣告,想修改pycharm中python註釋的顏色找了半天居然得這麼搞:
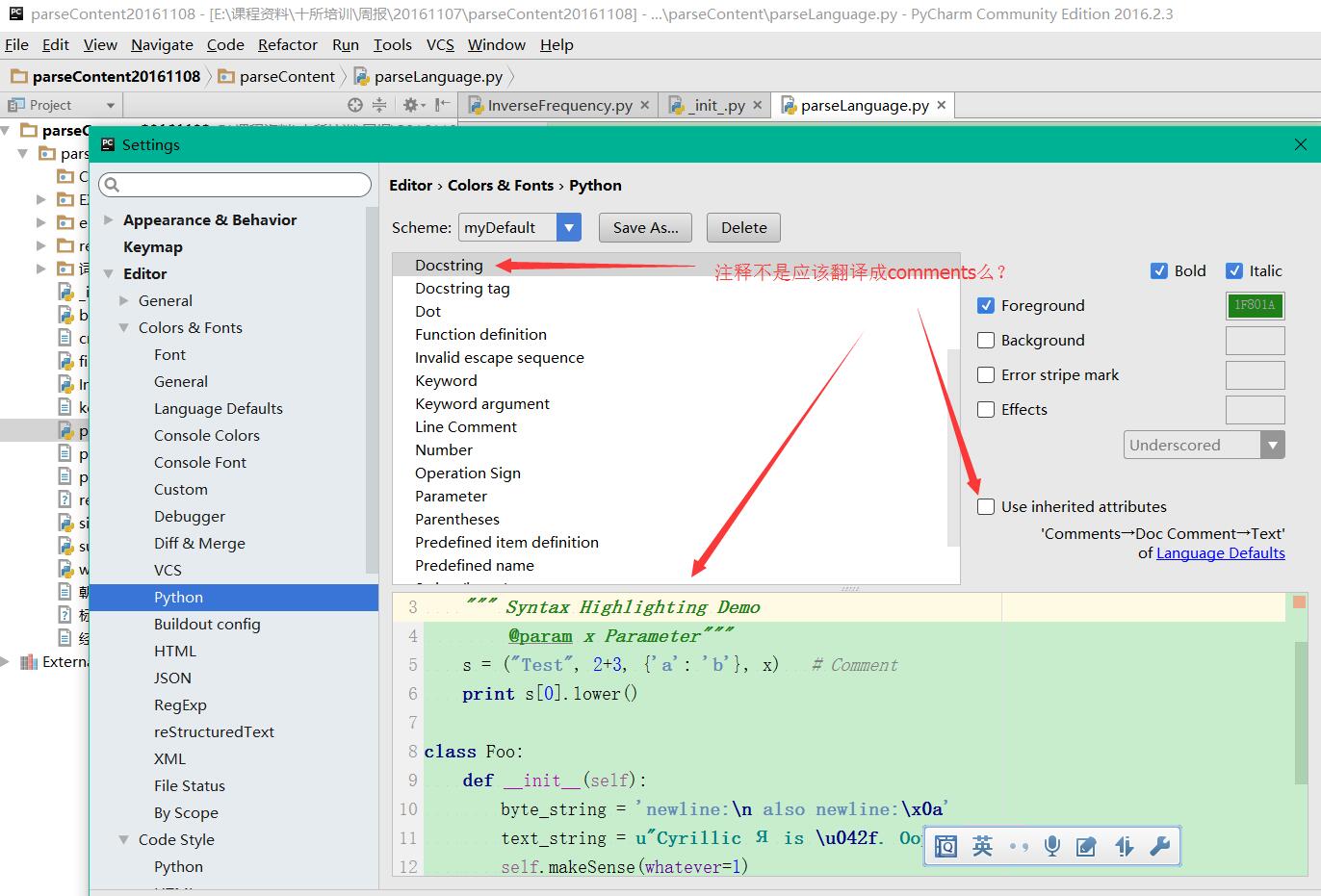
當大家搜尋如何在系統中混合使用python2和python3,國內網站經常會讓大家把其中一個python.exe改個名字,這樣區分開兩個可執行檔案的名字,但是這樣做有一個重大的隱患,就是修改了名字的那個python對應的pip將無法使用。有時候還是需要用用命令列的,怎麼辦?
官方用法為:
在安裝Python3(>=3.3)時,Python的安裝包實際上在系統中安裝了一個啟動器py.exe,預設放置在資料夾C:\Windows\下面。這個啟動器允許我們指定使用Python2還是Python3來執行程式碼(當然前提是你已經成功安裝了Python2和Python3)。
如果你有一個Python檔案叫 hello.py,那麼你可以這樣用Python2執行它
py -2 hello.py
類似的,如果你想用Python3執行它,就這樣
py -3 hello.py
去掉引數 -2/-3
每次執行都要加入引數-2/-3還是比較麻煩,所以py.exe這個啟動器允許你在程式碼中加入說明,表明這個檔案應該是由python2解釋執行,還是由python3解釋執行。說明的方法是在程式碼檔案的最開始加入一行
#! python2
或者
#! python3
分別表示該程式碼檔案使用Python2或者Python3解釋執行。這樣,執行的時候你的命令就可以簡化為
py hello.py
使用pip
當Python2和Python3同時存在於windows上時,它們對應的pip都叫pip.exe,所以不能夠直接使用 pip install 命令來安裝軟體包。而是要使用啟動器py.exe來指定pip的版本。命令如下:
py -2 -m pip install XXXX
-2 還是表示使用 Python2,-m pip 表示執行 pip 模組,也就是執行pip命令了。如果是為Python3安裝軟體,那麼命令類似的變成
py -3 -m pip install XXXX
#! python2 和 # coding: utf-8 哪個寫在前面?
對於Python2使用者還有另外一個困惑,Python2要在程式碼檔案頂部增加一行說明,才能夠在程式碼中使用中文。如果指明使用的Python版本也需要在檔案頂部增加一行,那哪一行應該放在第一行呢?
#! python2 需要放在第一行,編碼說明可以放在第二行。所以檔案開頭應該類似於:
#!python2
# coding: utf-8
資訊檢索概述
資訊檢索是當前應用十分廣泛的一種技術,論文檢索、搜尋引擎都屬於資訊檢索的範疇。通常,人們把資訊檢索問題抽象為:在文件集合D上,對於由關鍵詞w[1] … w[k]組成的查詢串q,返回一個按查詢q和文件d匹配度 relevance (q, d)排序的相關文件列表D。
對於這一基問題,先後出現了布林模型、向量模型等各種經典的資訊檢索模型,它們從不同的角度提出了自己的一套解決方案。
布林模型以集合的布林運算為基礎,查詢效率高,但模型過於簡單,無法有效地對不同文件進行排序,查詢效果不佳。
向量模型把文件和查詢串都視為詞所構成的多維向量,而文件與查詢的相關性即對應於向量間的夾角。不過,由於通常詞的數量巨大,向量維度非常高,而大量的維度都是0,計算向量夾角的效果並不好。另外,龐大的計算量也使得向量模型幾乎不具有在網際網路搜尋引擎這樣海量資料集上實施的可行性。
TF-IDF原理概述
如何衡量一個特徵詞在文字中的代表性呢?以往就是通過詞出現的頻率,簡單統計一下,從高到低,結果發現了一堆的地得,和英文的介詞in of with等等,於是TF-IDF應運而生。
TF-IDF不但考慮了一個詞出現的頻率TF,也考慮了這個詞在其他文件中不出現的逆頻率IDF,很好的表現出了特徵詞的區分度,是資訊檢索領域中廣泛使用的一種檢索方法。
Tf-idf演算法公式以及說明:
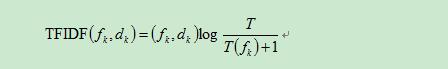
具體實現如下所示,公式分成兩項,詞頻*逆詞頻,逆詞頻取log值。


注意分母中的+1,在很多文獻中並沒有出現,這個可能引發異常。
本人寫了一份程式碼近期正在修改,後續傳到github 上,再貼出來。文章末尾貼出了兩份我認為比較好的程式碼,一份是面向物件的實現一份是分散式的。
tfidf原始碼實現及相關部落格資料:
python scikit-learn計算tf-idf詞語權重(scikit-learn包中提供了tfidf的矩陣實現,缺點是詞數量過大可能溢位)
http://www.tuicool.com/articles/U3uiiu
參考文獻
github程式碼:
相關推薦
短文字分析----基於python的TF-IDF特徵詞標籤自動化提取
緒論 最近做課題,需要分析短文字的標籤,在短時間內學習了自然語言處理,社會標籤推薦等非常時髦的技術。我們的需求非常類似於從大量短文字中獲取關鍵詞(融合社會標籤和時間屬性)進行使用者畫像。這一切的基礎就是特徵詞提取技術了,本文主要圍繞關鍵詞提取這個主題進行介紹(
深度學習與中文短文字分析總結與梳理
1.緒論 過去幾年,深度神經網路在模式識別中佔絕對主流。它們在許多計算機視覺任務中完爆之前的頂尖演算法。在語音識別上也有這個趨勢了。而中文文字處理,以及中文自然語言處理上,似乎沒有太厲害的成果?尤其是中文短文字處理的問題上,尚且沒有太成功的應用於分散式
基於TF-IDF的新聞標簽提取
出現 結果 方式 通過 一是 時間 -i 輸出 衡量 基於TF-IDF的新聞標簽提取 1. 新聞標簽 新聞標簽是一條新聞的關鍵字,可以由編輯上傳,或者通過機器提取。新聞標簽的提取主要用於推薦系統中,所以,提取的準確性影響推薦系統的有效性。同時,對於將標簽展示出來的新聞網
(NLP)基於分詞標籤的中文短文字相似度
基於分詞標籤的中文短文字相似度 最近接觸到了一些關於中文短文字相似度的演算法,將它們總結在此: 中文編輯距離 基於詞頻的餘弦相似度 Python difflib github傳送門:https://github.com/gongpx20069/DIY
用 TF-IDF 和詞袋錶示文件特徵
使用 CounterVectorizer 和 TfidfTransformer 計算 TF-IDF import jieba from sklearn.feature_extraction.text import CountVectorizer, TfidfTr
王仲遠 | 基於概念知識圖譜的短文字理解
3月10日,美團點評AI Lab NLP負責人王仲遠博士,給大家進行了題為“基於概念化的短文字理
開源專案kcws程式碼分析--基於深度學習的分詞技術
分詞原理 本小節內容參考待字閨中的兩篇博文: 簡單的說,kcws的分詞原理就是: 對語料進行處理,使用word2vec對語料的字進行嵌入,每個字特徵為50維。 得到字嵌入後,用字嵌入特徵餵給雙向LSTM, 對輸出的隱層加一個線性層,然後加一個CRF就
利用目前的三個分詞工具(jieba、snownlp、pynlpir)簡單的實現了短文字的分詞效果
part one 利用jieba分詞結果為:part two 利用snownlp分詞結果為:part one 利用pynlpir分詞程式碼如下:測試結果如下:在執行過程中遇到了pynlpir授權過期的問題,即報錯為:pynlpir.LicenseError:
文字情感分析(二):基於word2vec和glove詞向量的文字表示
上一篇部落格用詞袋模型,包括詞頻矩陣、Tf-Idf矩陣、LSA和n-gram構造文字特徵,做了Kaggle上的電影評論情感分類題。 這篇部落格還是關於文字特徵工程的,用詞嵌入的方法來構造文字特徵,也就是用word2vec詞向量和glove詞向量進行文字表示,訓練隨機森林分類器。 一、訓練word2vec詞
3W字乾貨深入分析基於Micrometer和Prometheus實現度量和監控的方案
 ## 前提 最近線上的專案使用了`spring-actuator`做度量統計收集,使用`Prometheus`進行資料收集,
銷量預測和用戶行為的分析--基於ERP的交易數據
測試數據 為什麽 5% 重要 思考 發的 span 左右 參考 寫在前面: 這段時間一直都在看一些機器學習方面的內容,其中又花了不少時間在推薦系統這塊,然後自己做了一套簡單的推薦系統,但是跑下來的結果總覺得有些差強人意,我在離線實驗中得到Precision,Recall一般
005推斷兩個字符串是否是變位詞 (keep it up)
right sans color amp 兩個 我們 nag 排序 isa 寫一個函數推斷兩個字符串是否是變位詞。變位詞(anagrams)指的是組成兩個單詞的字符同樣,但位置不同的單詞。比方說, abbcd和abcdb就是一對變位詞 這也是簡單的題。 我們能夠排序然
u-boot-201611 啟動過程分析——基於smdk2410
u-bootu-boot-201611 啟動過程分析——基於smdk2410
字符串問題----判斷兩個字符串是否互為變形詞
public ati i++ created orm str 存儲 判斷 是否 判斷兩個字符串是否互為變形詞 給定兩個字符串 str1 和str2 ,如果兩個字符串中出現的字符種類一樣,次數也一樣,則互為變形詞,實現一個函數判斷兩個字符串是否互為變形詞。例如 st
判斷兩個字符串是否互為變形詞
比對 種類 字符串變量 取值 字母 ebo 如果 html als 題目 給定兩個字符串str1和str2,如果str1和str2中出現的字符種類一樣且每種字符出現的次數也一樣,那麽str1和str2互為變形詞。請實現函數判斷兩個字符串是否互為變形詞。 例如: str1=
判斷兩個字符串是否互為旋轉詞
public 實現 bool 方式 code rem 是否 bcd 題目 題目 對於一個字符串str,把前面任意部分挪到後面形成的字符串叫作str的旋轉詞。比如str=”12345”,其旋轉詞有”23451”、”34512”、”45123”、”51234”。給定兩個字符串a
python 基於TF-IDF演算法的關鍵詞提取
import jiaba.analyse jieba.analyse.extract_tags(content, topK=20, withWeight=False, allowPOS=()) content:為輸入的文字 topK:為返回tf-itf權重最大的關鍵詞,預設值為20個詞 wit
《基於影象點特徵的多檢視三維重建》——相關概念彙總筆記
1. 基於影象的影象3D重建 傳統上首先使用 Structure-from-Motion 恢復場景的稀疏表示和輸入影象的相機姿勢。 然後,此輸出用作Multi-View Stereo(多檢視立體)的輸入,以恢復場景衝密集表示。
Linux 核心中獲取時間分析基於do_gettimeofday()
Linux 核心中獲取時間分析基於do_gettimeofday() 核心程式碼能一直獲取一個當前時間的表示,通過檢視jifies的值。通常這個值只代表從最後一次啟動以來的時間,這個事實對驅動來說無關,因為它的生命週期受限於系統的uptime。 驅動可以使用jifie
全面講解分析基於區鏈塊的實現貨幣中心化的商城報單系統
1、前言: 系統是基於區鏈塊分散式智慧合約技術,實現貨幣的去中心化、點對點無損無痕流通,讓流通產生價值,也可以通證(雙倍積分釋放)提現,對接交易所可用錢包轉出。年賺百萬,只要輕鬆轉動通證。 2、名稱說明: 商城】1、贈送積分套餐購物板塊 2、商城商家版(餘額和通證可以購物) 【註冊】