
Python實現決策樹並且使用Graphvize視覺化
一、什麼是決策樹(decision tree)——機器學習中的一個重要的分類演算法
決策樹是一個類似於資料流程圖的樹結構:其中,每個內部節點表示一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉結點代表類或者類的分佈,樹的最頂層是根結點
根據天氣情況決定出遊與否的案例

二、決策樹演算法構建
2.1決策樹的核心思路
- 特徵選擇:從訓練資料的特徵中選擇一個特徵作為當前節點的分裂標準(特徵選擇的標準不同產生了不同的特徵決策樹演算法)。
- 決策樹生成:根據所選特徵評估標準,從上至下遞迴地生成子節點,直到資料集不可分則停止決策樹停止聲場。
- 剪枝:決策樹容易過擬合,需要剪枝來縮小樹的結構和規模(包括預剪枝和後剪枝)。
2.2 熵的概念:度量資訊的方式
實現決策樹的演算法包括ID3、C4.5演算法等。常見的ID3核心思想是以資訊增益度量屬性選擇,選擇分裂後資訊增益最大的屬性進行分裂。
一條資訊的資訊量大小和它的不確定性有直接的關係,要搞清楚一件非常不確定的事情,或者是我們一無所知的事情,需要大量的資訊====>資訊量的度量就等於不確定性的 多少。也就是說變數的不確定性越大,熵就越大
資訊熵的計算公司
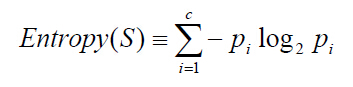
S為所有事件集合,p為發生概率,c為特徵總數。
資訊增益(information gain)是指資訊劃分前後的熵的變化,也就是說由於使用這個屬性分割樣例而導致的期望熵降低。也就是說,資訊增益就是原有資訊熵與屬性劃分後資訊熵(需要對劃分後的資訊熵取期望值)的差值,具體計算如下:
其中,第二項為屬性A對S劃分的期望資訊。
三、IDE3決策樹的Python實現
以下面這個不同年齡段的人買電腦的情況為例子建模型演算法

''' Created on 2018年7月5日 使用python內的科學計算的庫實現利用決策樹解決問題 @author: lenovo ''' #coding:utf-8 from sklearn.feature_extraction import DictVectorizer #資料儲存的格式 python自帶不需要安裝 import csv #預處理的包 from sklearn import preprocessing from sklearn.externals.six import StringIO from sklearn.tree import tree from sklearn.tree import export_graphviz ''' 檔案儲存格式需要是utf-8 window中的目錄形式需要是左斜槓 F:/AA_BigData/test_data/test1.csv excel表格儲存成csv格式並且是utf-8格式的編碼 ''' ''' 決策樹資料來源讀取 scklearn要求的資料型別 特徵值屬性必須是數值型的 需要對資料進行預處理 ''' #裝特徵的值 featureList=[] #裝類別的詞 labelList=[] with open("F:/AA_BigData/test_data/decision_tree.csv", "r",encoding="utf-8") as csvfile: decision =csv.reader(csvfile) headers =[] row =1 for item in decision: if row==1: row=row+1 for head in item: headers.append(head) else: itemDict={} labelList.append(item[len(item)-1]) for num in range(1,len(item)-1): # print(item[num]) itemDict[headers[num]]=item[num] featureList.append(itemDict) print(headers) print(labelList) print(featureList) ''' 將原始資料轉換成包含有字典的List 將建好的包含字典的list用DictVectorizer物件轉換成0-1矩陣 ''' vec =DictVectorizer() dumyX =vec.fit_transform(featureList).toarray(); #對於類別使用同樣的方法 lb =preprocessing.LabelBinarizer() dumyY=lb.fit_transform(labelList) print(dumyY) ''' 1.構建分類器——決策樹模型 2.使用資料訓練決策樹模型 ''' clf =tree.DecisionTreeClassifier(criterion="entropy") clf.fit(dumyX,dumyY) print(str(clf)) ''' 1.將生成的分類器轉換成dot格式的 資料 2.在命令列中dot -Tpdf iris.dot -o output.pdf將dot檔案轉換成pdf圖的檔案 ''' #視訊上講的不適用python3.5 with open("F:/AA_BigData/test_data/decisiontree.dot", "w") as wFile: export_graphviz(clf,out_file=wFile,feature_names=vec.get_feature_names())
Graphvize對決策樹的視覺化

相關推薦
Python實現決策樹並且使用Graphvize視覺化
一、什麼是決策樹(decision tree)——機器學習中的一個重要的分類演算法決策樹是一個類似於資料流程圖的樹結構:其中,每個內部節點表示一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉結點代表類或者類的分佈,樹的最頂層是根結點根據天氣情況決定出遊與否的案例二、決策
決策樹演算法及視覺化實現
序 本文旨在對決策樹演算法的python實現及利用matplotlib繪製樹進行學習。 演算法描述 (1)最小二乘迴歸樹生成演算法 (2)CART生成演算法 其中,5.25如下
Python實現決策樹應用之判斷隱形眼鏡的型別
程式碼模組一、DecisionTreePlot # -*- coding:utf-8 -*- __author__ = 'yangxin_ryan' import matplotlib.pyplot as plt """ 定義文字框 和 箭頭格式 【 sawtooth 波浪方框, rou
python實現決策樹程式碼
資料圖片 from sklearn.feature_extraction import DictVectorizer import csv from sklearn import preprocessing from numpy import * import nu
python實現決策樹
# -*- coding: utf-8 -*- """ Created on Thu Sep 27 10:40:47 2018 @author: Administrator """ # de template # Importing the libraries impor
python實現決策樹演算法
1. #!/usr/bin/python3 import numpy as np from sklearn import tree from sklearn.metrics import precision_recall_curve from sklearn.metrics
Python實現決策樹對西瓜進行分類
使用的周志華老師書上的例子,因為習主席講過一切不給資料集的演算法都是耍流氓,所以我這裡先給出資料集: 0,色澤,根蒂,敲聲,紋理,臍部,觸感,密度,含糖率,好瓜 1,青綠,蜷縮,濁響,清晰,凹陷,硬滑,0.697,0.46,是 2,烏黑,蜷縮,沉悶,清晰,凹陷,硬滑
機器學習經典演算法詳解及Python實現--決策樹(Decision Tree)
(一)認識決策樹 1,決策樹分類原理 決策樹是通過一系列規則對資料進行分類的過程。它提供一種在什麼條件下會得到什麼值的類似規則的方法。決策樹分為分類樹和迴歸樹兩種,分類樹對離散變數做決策樹,迴歸樹對連續變數做決策樹。 近來的調查表明決策樹也是最經常使用的資料探勘演算法,它
詳解決策樹、python實現決策樹
決策樹模型 定義 決策過程 決策樹學習 特徵選擇 資訊增益 計算方法 ID3演算法 決策樹模型 定義 分類決策樹模型是一種描述對例項進行分類的樹形結構。決策樹由節點(Node)和有向邊(directed edge)組成。節
python實現決策樹分類(三)
在上一篇文章中,我們已經構建了決策樹,接下來可以使用它用於實際的資料分類。在執行資料分類時,需要決策時以及標籤向量。程式比較測試資料和決策樹上的數值,遞迴執行直到進入葉子節點。 這篇文章主要使用決策樹分類器就行分類,資料集採用UCI資料庫中的紅酒,白酒資料,主要特徵包括12
Python實現——決策樹實例(離散數據/香農熵)
遍歷 values 最適 比例 刪除 類型 取值 val creat 決策樹的實現太...繁瑣了。 如果只是接受他的原理的話還好說,但是要想用代碼去實現比較糟心,目前運用了《機器學習實戰》的代碼手打了一遍,決定在這裏一點點摸索一下該工程。 實例的代碼在使用上運用了香農熵,並
python決策樹(二叉樹、樹)的視覺化
問題描述 在我學習機器學習實戰-決策樹部分,欲視覺化決策樹結構。最終視覺化結果: 解決方案 決策樹由巢狀字典組成,如: {“no surfacing”: {0: “no”, 1: {“flippers”: {0: “no”, 1: “yes”}}}}
【Python】決策樹的python實現
uia bmp say 不知道 times otto outlook lru bgm 【Python】決策樹的python實現 2016-12-08 數據分析師Nieson 1. 決策樹是什麽? 簡單地理解,就是根據一些 feature 進行分類,每個節點提一個問
python機器學習實戰2:實現決策樹
1.決策樹的相關知識 在之前的接觸中決策樹直觀印象應該就是if-else的迴圈,if會怎麼樣,else之後再繼續if-else直至最終的結果。在上節講的kNN它其實已經可以完成很多工,但是它最大的缺點就是無法給資料集的內在含義,決策樹的主要優勢在於資料形式非常
Python資料處理 | (三) Matplotlib資料視覺化
本篇部落格所有示例使用Jupyter NoteBook演示。 Python資料處理系列筆記基於:Python資料科學手冊電子版 下載密碼:ovnh 示例程式碼 下載密碼:02f4 目錄 一、Matplotlib常用技巧 1.匯入
NLP之WE之Skip-Gram:基於TF利用Skip-Gram模型實現詞嵌入並進行視覺化、過程全記錄
NLP之WE之Skip-Gram:基於TF利用Skip-Gram模型實現詞嵌入並進行視覺化 輸出結果 程式碼設計思路 程式碼執行過程全記錄 3081 originated -> 12 as 3081 originated
Python建立決策樹—解決隱形眼鏡選擇問題
現在我們碰到這樣一個問題,一個人去醫院想配一副隱形眼鏡。我們需要通過問他4個問題,決定他需要帶眼鏡的型別。那麼如何解決這個問題呢?我們決定用決策樹。首先我們去下載一個隱形眼鏡資料集,資料來源於UCI資料庫。下載了lenses.data檔案,如下: 1 1 1 1 1 3 2 1 1
在OpenCV中實現決策樹和隨機森林
目錄 1.決策樹 2.隨機森林 1.決策樹 需要注意的點: Ptr<TrainData> data_set = TrainData::loadFromCSV("mushroom.data",//檔名
Pyhton實現決策樹演算法 MNIST資料集
Pyhton實現決策樹演算法 MNIST資料集 決策樹是一種比較接近人類思維方式的演算法,將樣本通過每個特徵值的資訊增益進行劃分,從而保證每個劃分之後的結果資訊熵的消減量達到最大。具體的原理請大家自己查詢相關資料。 sklearn實現程式碼如下, 準確率可以達到90%左右。 fr
利用Python進行資料分析——繪圖和視覺化(八)(2)
1、註釋以及在Subplot上繪圖 除標準的圖表物件之外,你可能還希望繪製一些自定義的註釋(比如文字、箭頭或其他圖形等)。 註釋可以通過text、arrow和annotate等函式進行新增。text可以將文字繪製在圖表的指定座標(x, y),還可以加上一些自定義格式: In [41]: ax.t