hadoop 配置hive 詳細流程
阿新 • • 發佈:2019-01-21
解壓hive壓縮包

將hive目錄下conf資料夾下 hive-env.sh.template 拷貝成 hive-env.sh,並增加四行內容

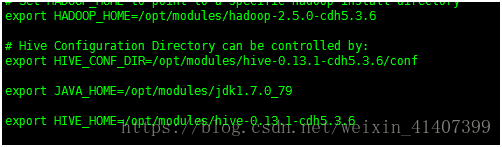
在hive-env.sh增加四行內容
exportHADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
exportHIVE_CONF_DIR=/opt/modules/hive-0.13.1-cdh5.3.6/conf
export JAVA_HOME=/opt/modules/jdk1.7.0_79
exportHIVE_HOME=/opt/modules/hive-0.13.1-cdh5.3.6
將conf資料夾下hive-default.xml.template 拷貝成 hive-site.xml

將hive-site.xml 配置內容全部刪除,並增加以下內容
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> </configuration>

將conf資料夾下hive-log4j.properties.template 改名為 hive-log4j.properties

修改hive-log4j.properties 中hive.log.dir路徑
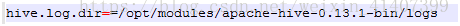
在hive 目錄下建立 logs資料夾

解壓mysql驅動器

將驅動器jar包拷貝至hive目錄下lib資料夾下

在hdfs上建立/user/hive/warehouse

修改/tmp和/user/hive/warehouse 給使用者組增加執行許可權

為了方便hive執行,可以增加hive環境變數 root使用者下修改/etc/profile


啟動hive

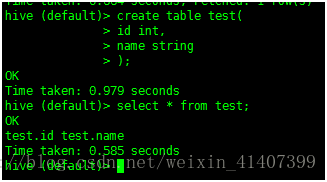
建立一個表,並查詢測試,配置成功!