
HBASE---LSM樹——放棄讀能力換取寫能力,將多次修改放在記憶體中形成有序樹再統一寫入磁碟
LSM樹(Log-Structured Merge Tree)儲存引擎
代表資料庫:nessDB、leveldb、hbase等
核心思想的核心就是放棄部分讀能力,換取寫入的最大化能力。LSM Tree ,這個概念就是結構化合並樹的意思,它的核心思路其實非常簡單,就是假定記憶體足夠大,因此不需要每次有資料更新就必須將資料寫入到磁碟中,而可以先將最新的資料駐留在磁碟中,等到積累到最後多之後,再使用歸併排序的方式將記憶體內的資料合併追加到磁碟隊尾(因為所有待排序的樹都是有序的,可以通過合併排序的方式快速合併到一起)。
日誌結構的合併樹(LSM-tree)是一種基於硬碟的資料結構,與B-tree相比,能顯著地減少硬碟磁碟臂的開銷,並能在較長的時間提供對檔案的高速插入(刪除)。然而LSM-tree在某些情況下,特別是在查詢需要快速響應時效能不佳。通常LSM-tree適用於索引插入比檢索更頻繁的應用系統。Bigtable在提供Tablet服務時,使用GFS來儲存日誌和SSTable,而GFS的設計初衷就是希望通過新增新資料的方式而不是通過重寫舊資料的方式來修改檔案
磁碟的技術特性:對磁碟來說,能夠最大化的發揮磁碟技術特性的使用方式是:一次性的讀取或寫入固定大小的一塊資料,並儘可能的減少隨機尋道這個操作的次數。
轉自:http://blog.csdn.net/dbanote/article/details/8897599
LSM樹是Hbase裡非常有創意的一種資料結構,它和傳統的B+樹不太一樣,下面先說說B+樹。
1 B+樹
相信大家對B+樹已經非常的熟悉,比如Oracle的普通索引就是採用B+樹的方式,下面是一個B+樹的例子:
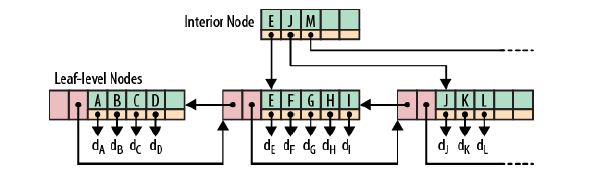
根節點和枝節點很簡單,分別記錄每個葉子節點的最小值,並用一個指標指向葉子節點。
葉子節點裡每個鍵值都指向真正的資料塊(如Oracle裡的RowID),每個葉子節點都有前指標和後指標,這是為了做範圍查詢時,葉子節點間可以直接跳轉,從而避免再去回溯至枝和跟節點。
B+樹最大的效能問題是會產生大量的隨機IO,隨著新資料的插入,葉子節點會慢慢分裂,邏輯上連續的葉子節點在物理上往往不連續,甚至分離的很遠,但做範圍查詢時,會產生大量讀隨機IO。
對於大量的隨機寫也一樣,舉一個插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的資料儲存在磁碟上相隔很遠,會產生大量的隨機寫IO.
從上面可以看出,低下的磁碟尋道速度嚴重影響效能(近些年來,磁碟尋道速度的發展幾乎處於停滯的狀態)。
2 LSM樹
為了克服B+樹的弱點,HBase引入了LSM樹的概念,即Log-Structured Merge-Trees。
為了更好的說明LSM樹的原理,下面舉個比較極端的例子:
現在假設有1000個節點的隨機key,對於磁碟來說,肯定是把這1000個節點順序寫入磁碟最快,但是這樣一來,讀就悲劇了,因為key在磁碟中完全無序,每次讀取都要全掃描;
那麼,為了讓讀效能儘量高,資料在磁碟中必須得有序,這就是B+樹的原理,但是寫就悲劇了,因為會產生大量的隨機IO,磁碟尋道速度跟不上。
LSM樹本質上就是在讀寫之間取得平衡,和B+樹相比,它犧牲了部分讀效能,用來大幅提高寫效能。
它的原理是把一顆大樹拆分成N棵小樹, 它首先寫入到記憶體中(記憶體沒有尋道速度的問題,隨機寫的效能得到大幅提升),在記憶體中構建一顆有序小樹,隨著小樹越來越大,記憶體的小樹會flush到磁碟上。當讀時,由於不知道資料在哪棵小樹上,因此必須遍歷所有的小樹,但在每顆小樹內部資料是有序的。
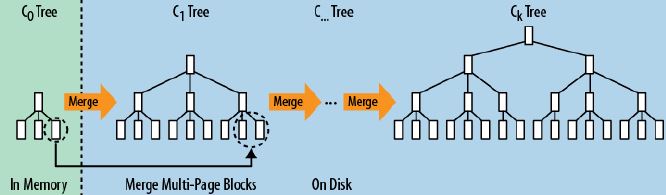
以上就是LSM樹最本質的原理,有了原理,再看具體的技術就很簡單了。
1)首先說說為什麼要有WAL(Write Ahead Log),很簡單,因為資料是先寫到記憶體中,如果斷電,記憶體中的資料會丟失,因此為了保護記憶體中的資料,需要在磁碟上先記錄logfile,當記憶體中的資料flush到磁碟上時,就可以拋棄相應的Logfile。
2)什麼是memstore, storefile?很簡單,上面說過,LSM樹就是一堆小樹,在記憶體中的小樹即memstore,每次flush,記憶體中的memstore變成磁碟上一個新的storefile。
3)為什麼會有compact?很簡單,隨著小樹越來越多,讀的效能會越來越差,因此需要在適當的時候,對磁碟中的小樹進行merge,多棵小樹變成一顆大樹。
關於LSM Tree,對於最簡單的二層LSM Tree而言,記憶體中的資料和磁碟中的資料merge操作,如下圖

下面說說詳細例子:
LSM Tree弄了很多個小的有序結構,比如每m個數據,在記憶體裡排序一次,下面100個數據,再排序一次……這樣依次做下去,就可以獲得N/m個有序的小的有序結構。
在查詢的時候,因為不知道這個資料到底是在哪裡,所以就從最新的一個小的有序結構裡做二分查詢,找得到就返回,找不到就繼續找下一個小有序結構,一直到找到為止。
很容易可以看出,這樣的模式,讀取的時間複雜度是(N/m)*log2N 。讀取效率是會下降的。
這就是最本來意義上的LSM tree的思路。那麼這樣做,效能還是比較慢的,於是需要再做些事情來提升,怎麼做才好呢?
LSM Tree優化方式:
a、Bloom filter: 就是個帶隨即概率的bitmap,可以快速的告訴你,某一個小的有序結構裡有沒有指定的那個資料的。於是就可以不用二分查詢,而只需簡單的計算幾次就能知道資料是否在某個小集合裡啦。效率得到了提升,但付出的是空間代價。
b、compact:小樹合併為大樹:因為小樹他效能有問題,所以要有個程序不斷地將小樹合併到大樹上,這樣大部分的老資料查詢也可以直接使用log2N的方式找到,不需要再進行(N/m)*log2n的查詢了
更詳細的可以參考:http://weakyon.com/2015/04/08/Log-Structured-Merge-Trees.html
相關推薦
HBASE---LSM樹——放棄讀能力換取寫能力,將多次修改放在記憶體中形成有序樹再統一寫入磁碟
LSM樹(Log-Structured Merge Tree)儲存引擎代表資料庫:nessDB、leveldb、hbase等核心思想的核心就是放棄部分讀能力,換取寫入的最大化能力。LSM Tree ,這個概念就是結構化合並樹的意思,它的核心思路其實非常簡單,就是假定記憶體足夠
【多次過】Lintcode 94. 二叉樹中的最大路徑和
給出一棵二叉樹,尋找一條路徑使其路徑和最大,路徑可以在任一節點中開始和結束(路徑和為兩個節點之間所在路徑上的節點權值之和) 樣例 給出一棵二叉樹: 1 / \ 2 3 返回 6 解題思路: 利用分治法 解決問題 需要
【多次過】Lintcode 595. 二叉樹最長連續序列
給一棵二叉樹,找到最長連續路徑的長度。 這條路徑是指 任何的節點序列中的起始節點到樹中的任一節點都必須遵循 父-子 聯絡。最長的連續路徑必須是從父親節點到孩子節點(不能逆序)。 樣例 舉個例子: 1 \ 3 / \ 2 4 \
Java 寫一個方法判斷一個字串是否對稱 "asdfgasdfg"、編寫一個程式,將下面的一段文字中的各個單詞的字母順序翻轉,
1、寫一個方法判斷一個字串是否對稱 "asdfgasdfg" public class Demo22 {public static void main(String[] args) { String string="asdfgasdfg";
害你加班的bug就是我寫的,記一次升級Jenkins外掛引發的加班
## 主旨 本文主要記錄了下Jenkins升級外掛過程中出現的場景,一次加班經歷,事發時沒有截圖,有興趣可以看看。 ## 起因 ### 需求 最近有個需求:在Jenkins流水線中完成下載Git上的檔案簡單修改並提交的功能 起初找到了相關的外掛用法,即使用 `SSH Agent Plugin` 來完成這個
HBASE系統架構圖以及各部分的功能作用,物理儲存,HBASE定址機制,讀寫過程,Region管理,Master工作機制
1.1 hbase內部原理 1.1.1 系統架構 Client 1 包含訪問hbase的介面,client維護著一些cache來加快對hbase的訪問,比如regione的位置資訊。 Zookeeper 1 保證任何時候,叢集中只有一個master&
HBase-LSM樹理解
講LSM樹之前,需要提下三種基本的儲存引擎,這樣才能清楚LSM樹的由來: 雜湊儲存引擎 是雜湊表的持久化實現,支援增、刪、改以及隨機讀取操作,但不支援順序掃描,對應的儲存系統為key-value儲存系統。對於key-value的插入以及查詢,雜湊表的複雜度都是O(1),
hbase 寫資料,存資料,讀資料的詳細過程
Client寫入 -> 存入MemStore,一直到MemStore滿 -> Flush成一個StoreFile,直至增長到一定閾值 -> 出發Compact合併操作 -> 多個StoreFile合併成一個StoreFile,同時進行版本合併和資料刪
redis讀寫分離,主從復制
req con word redis讀寫分離 分離 bsp onf 服務 master master配置:(主服務 redis.conf) requirepass masterpassword (配置密碼) port 6379 (配置端口) slave配置 re
EF通用數據層封裝類(支持讀寫分離,一主多從)
dto cte 功能 pes getc mes 工廠 好的 靈活 淺談orm 記得四年前在學校第一次接觸到 Ling to Sql,那時候瞬間發現不用手寫sql語句是多麽的方便,後面慢慢的接觸了許多orm框架,像 EF,Dapper,Hibernate,ServiceSta
node.js 利用流實現讀寫同步,邊讀邊寫
write 使用 類型 同步 node.js tar 利用 關閉 console //10個數 10個字節,每次讀4b,寫1b let fs=require("fs"); function pipe(source,target) { //先創建可讀流,再創
用樹鏈剖分來寫LCA
ostream 第一次 pri def -- != dfs roo truct 當兩個點在一條鏈上,它們的LCA就是深度較小的那個點。 於是這種樹鏈剖分寫LCA的思想就是把要求的兩個點想辦法靠到一條鏈上。 而且要靠到盡量更優的一條鏈上(重鏈)。 做法: 預處理出每
Linux的企業-Mysql讀寫分離,組的復制Group-based Replication(2)
mysql讀寫分離 組的復制 基於組的復制(Group-based Replication)是一種被使用在容錯系統中的技術。Replication-group(復制組)是由能夠相互通信的多個服務器(節點)組成的。在通信層,Group replication實現了一系列的機制:比如原子消息(atomic
STM32F407 讀保護,寫保護,解鎖過程【芯片已設置讀保護,無法讀取更多信息】
寫保護 stm32f407 讀保護 解鎖過程 硬件準備:CH340 USB轉TTL串口一個STM32F407 板子一塊設置從ISP啟動軟件準備:1,flash_loader_demo_v2.8.0.exe 或者 FlashLoader Demonstrator 2.8.0.msi 都可以下載地址:
【JavaNIO的深入研究4】內存映射文件I/O,大文件讀寫操作,Java nio之MappedByteBuffer,高效文件/內存映射
int start lib 交換文件 bsp 沒有 res collected str time 內存映射文件能讓你創建和修改那些因為太大而無法放入內存的文件。有了內存映射文件,你就可以認為文件已經全部讀進了內存,然後把它當成一個非常大的數組來訪問。這種解決辦法能大大簡化修
實現MySQL讀寫分離,MySQL性能調優
affect iad list cte 軟件包 密碼 sts 要求 select 實現MySQL讀寫分離 1.1 問題 本案例要求配置2臺MySQL服務器+1臺代理服務器,實現MySQL代理的讀寫分離: 用戶只需要訪問MySQL代理服務器,而實際的SQL查詢、寫入操作交給
WINDOWS 同步(Interlocked,InterlockedExchangeAdd,Slim讀/寫鎖,WaitForSingleObject,CreateWaitableTimer等等)
延遲 align .net 屬於 替代 技巧 led 存在 resume NOTE0 在以下兩種基本情況下,線程之間需要相互通信: 需要讓多個線程同時訪問一個共享資源,同時不能破壞資源的完整性; 一個線程需要通知其它線程某項任務已經完成 1.原子訪問:Int
代寫二叉查找樹程序作業、代寫BST 作業、代寫Data Structures
oca fur hand contex ins drop rest nat HA 代寫二叉查找樹程序作業、代寫BST 作業、代寫Data StructuresKIT205 Data Structures and AlgorithmsAssignment 1: Data St
springboot2.0.3:讀寫分離,使用AOP根據方法名動態切換數據源。
move net 流程 adl rim tis sig mov put springboot版本:2.0.3!!! springboot版本:2.0.3!!! springboot版本:2.0.3!!! 我搭好的環境是:springboot 2.0.3+mybatis 大致
讀出局域網其他服務器的共享目錄並通過php顯示目錄樹
mb star () wro windows == path table 共享服務 mount 工作上有這樣一個任務。有兩個服務器, A,B,在一個局域網內。A, 192.168.1.20 B, 192.168.1.21A 服務器是共享服務器,安裝了smb, 在/home