
HashMap實現原理分析(面試問題:兩個hashcode相同 的物件怎麼存入hashmap的)
1. HashMap的資料結構
資料結構中有陣列和連結串列來實現對資料的儲存,但這兩者基本上是兩個極端。
陣列
陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;
連結串列
連結串列儲存區間離散,佔用記憶體比較寬鬆,故空間複雜度很小,但時間複雜度很大,達O(N)。連結串列的特點是:定址困難,插入和刪除容易。
雜湊表
那麼我們能不能綜合兩者的特性,做出一種定址容易,插入刪除也容易的資料結構?答案是肯定的,這就是我們要提起的雜湊表。雜湊表((Hash table)既滿足了資料的查詢方便,同時不佔用太多的內容空間,使用也十分方便。
雜湊表有多種不同的實現方法,我接下來解釋的是最常用的一種方法—— 拉鍊法,我們可以理解為“連結串列的陣列” ,如圖:
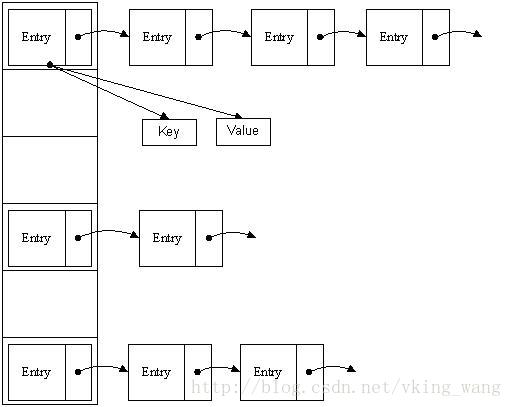
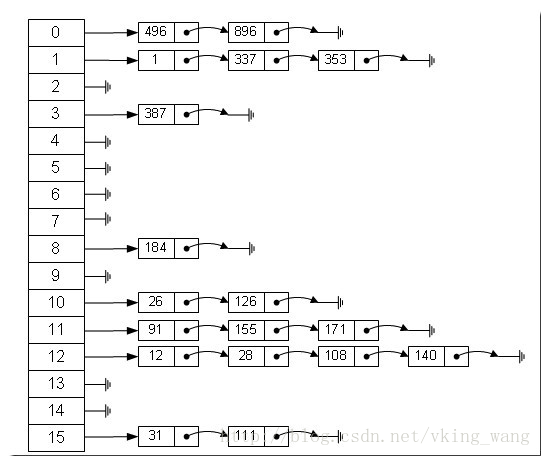
從上圖我們可以發現雜湊表是由陣列+連結串列組成的,一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。那麼這些元素是按照什麼樣的規則儲存到陣列中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。
HashMap其實也是一個線性的陣列實現的,所以可以理解為其儲存資料的容器就是一個線性陣列。這可能讓我們很不解,一個線性的陣列怎麼實現按鍵值對來存取資料呢?這裡HashMap有做一些處理。
首先HashMap裡面實現一個靜態內部類Entry,其重要的屬性有key , value, next,從屬性key,value我們就能很明顯的看出來Entry就是HashMap鍵值對實現的一個基礎bean,我們上面說到HashMap的基礎就是一個線性陣列,這個陣列就是Entry[],Map裡面的內容都儲存在Entry[]裡面。
/** * The table, resized as necessary. Length MUST Always be a power of two. */transient Entry[] table;
2. HashMap的存取實現
既然是線性陣列,為什麼能隨機存取?這裡HashMap用了一個小演算法,大致是這樣實現:
// 儲存時:int hash = key.hashCode(); // 這個hashCode方法這裡不詳述,只要理解每個key的hash是一個固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值時:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put
疑問:如果兩個key通過hash%Entry[].length得到的index相同,會不會有覆蓋的危險?這裡HashMap裡面用到鏈式資料結構的一個概念。上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。打個比方, 第一個鍵值對A進來,通過計算其key的hash得到的index=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其index也等於0,現在怎麼辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等於0,那麼C.next = B,Entry[0] = C;這樣我們發現index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性連結在一起。所以疑問不用擔心。也就是說陣列中儲存的是最後插入的元素。到這裡為止,HashMap的大致實現,我們應該已經清楚了。
public V put(K key, V value) { if (key == null) return putForNullKey(value); //null總是放在陣列的第一個連結串列中 int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); //遍歷連結串列 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果key在連結串列中已存在,則替換為新value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null;}
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//引數e, 是Entry.next //如果size超過threshold,則擴充table大小。再雜湊 if (size++ >= threshold) resize(2 * table.length); }當然HashMap裡面也包含一些優化方面的實現,這裡也說一下。比如:Entry[]的長度一定後,隨著map裡面資料的越來越長,這樣同一個index的鏈就會很長,會不會影響效能?HashMap裡面設定一個因子,隨著map的size越來越大,Entry[]會以一定的規則加長長度。
2)get
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); //先定位到陣列元素,再遍歷該元素處的連結串列 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }3)null key的存取
null key總是存放在Entry[]陣列的第一個元素。
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }4)確定陣列index:hashcode % table.length取模
HashMap存取時,都需要計算當前key應該對應Entry[]陣列哪個元素,即計算陣列下標;演算法如下:
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { return h & (length-1); } 按位取並,作用上相當於取模mod或者取餘%。 這意味著陣列下標相同,並不表示hashCode相同。5)table初始大小
public HashMap(int initialCapacity, float loadFactor) { ..... // Find a power of 2 >= initialCapacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor); table = new Entry[capacity]; init(); }注意table初始大小並不是建構函式中的initialCapacity!!
而是 >= initialCapacity的2的n次冪!!!!
————為什麼這麼設計呢?——
3. 解決hash衝突的辦法
- 開放定址法(線性探測再雜湊,二次探測再雜湊,偽隨機探測再雜湊)
- 再雜湊法
- 鏈地址法
- 建立一個公共溢位區
Java中hashmap的解決辦法就是採用的鏈地址法。
4. 再雜湊rehash過程
當雜湊表的容量超過預設容量時,必須調整table的大小。當容量已經達到最大可能值時,那麼該方法就將容量調整到Integer.MAX_VALUE返回,這時,需要建立一張新表,將原表的對映到新表中。
/** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. * * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, but sets threshold to Integer.MAX_VALUE. * This has the effect of preventing future calls. * * @param newCapacity the new capacity, MUST be a power of two; * must be greater than current capacity unless current * capacity is MAXIMUM_CAPACITY (in which case value * is irrelevant). */ void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor);}
/** * Transfers all entries from current table to newTable. */ void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; //重新計算index int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } }}
相關推薦
轉:HashMap實現原理分析(面試問題:兩個hashcode相同 的對象怎麽存入hashmap的)
影響 strong 就會 怎麽 ash 地方 shm nbsp 擔心 原文地址:https://www.cnblogs.com/faunjoe88/p/7992319.html 主要內容: 1)put 疑問:如果兩個key通過hash%Entry[].length得到的
HashMap實現原理分析(面試問題:兩個hashcode相同 的物件怎麼存入hashmap的)
1. HashMap的資料結構 資料結構中有陣列和連結串列來實現對資料的儲存,但這兩者基本上是兩個極端。 陣列 陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難; 連結串列
Java集合---ConcurrentHashMap原理分析(面試問題:ConcurrentHashMap實現原理是怎麼樣的)
集合是程式設計中最常用的資料結構。而談到併發,幾乎總是離不開集合這類高階資料結構的支援。比如兩個執行緒需要同時訪問一箇中間臨界區(Queue),比如常會用快取作為外部檔案的副本(HashMap)。這篇文章主要分析jdk1.5的3種併發集合型別(concurrent,cop
HashMap底層原理分析(put、get方法)
return sta rec oca ati 技術分享 AI TP load 1、HashMap底層原理分析(put、get方法) HashMap底層是通過數組加鏈表的結構來實現的。HashMap通過計算key的hashCode來計算hash值,只要hashCode一樣
HashMap實現原理分析及簡單實現一個HashMap
HashMap實現原理分析及簡單實現一個HashMap 歡迎關注作者部落格 簡書傳送門 轉載@原文地址 HashMap的工作原理是近年來常見的Java面試題。幾乎每個Java程式設計師都知道HashMap,都知道哪裡要用HashMap,知道HashMap和
Guava TreeMultiSet實現原理分析(2)
5 count,size AvlNode為資料統計提供了多個便利引數,不需要遍歷所有的子節點就可以獲得相關的個數資訊。 AvlNode的統計屬性: elemCount:統計key相同的元素個數。 distinctElements:統計子樹中所有節點的個數,即ke
HashMap實現原理分析
1. HashMap的資料結構資料結構中有陣列和連結串列來實現對資料的儲存,但這兩者基本上是兩個極端。 陣列陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;連結串列連結串列儲存
Codeforces Round #459 (Div. 2) D. MADMAX 博弈和記憶化搜尋(同時照顧兩個起點的記憶化搜尋)
D. MADMAXtime limit per test1 secondmemory limit per test256 megabytesinputstandard inputoutputstandard outputAs we all know, Max is the b
HashMap實現原理及原始碼分析(轉載)
作者: dreamcatcher-cx 出處: <http://www.cnblogs.com/chengxiao/> 雜湊表(hash table)也叫散列表,是一種非常重要的資料結構,應用場景及其豐富,
(轉)HashMap實現原理及原始碼分析
雜湊表(hash table)也叫散列表,是一種非常重要的資料結構,應用場景及其豐富,許多快取技術(比如memcached)的核心其實就是在記憶體中維護一張大的雜湊表,而HashMap的實現原理也常常出現在各類的面試題中,重要性可見一斑。本文會對java集合框架中的對應實
Master原理剖析與原始碼分析:資源排程機制原始碼分析(schedule(),兩種資源排程演算法)
1、主備切換機制原理剖析與原始碼分析 2、註冊機制原理剖析與原始碼分析 3、狀態改變處理機制原始碼分析 4、資源排程機制原始碼分析(schedule(),兩種資源排程演算法) * Dri
面試高頻問題:HashMap實現原理
今天給同學們講講一個面試經常遇到的高頻問題,HashMap實現原理,希望在金三銀四的季節對同學們有幫助。 HashMap結
XSS的原理分析與解剖:第三章(技巧篇)**************未看*****************
第二章 != chrom 插入 是把 調用 bject innerhtml ats ??0×01 前言: 關於前兩節url: 第一章:http://www.freebuf.com/articles/web/40520.html 第二章:http://www.free
1.Java集合-HashMap實現原理及源碼分析
int -1 詳細 鏈接 理解 dac hash函數 順序存儲結構 對象儲存 哈希表(Hash Table)也叫散列表,是一種非常重要的數據結構,應用場景及其豐富,許多緩存技術(比如memcached)的核心其實就是在內存中維護一張大的哈希表,而HashMap的實
HashMap實現原理及源碼分析
響應 應用場景 取模運算 圖片 mat 直接 maximum 計算 時間復雜度 哈希表(hash table)也叫散列表,是一種非常重要的數據結構,應用場景及其豐富,許多緩存技術(比如memcached)的核心其實就是在內存中維護一張大的哈希表,而HashMap的實現原理也
Android系統的智能指針(輕量級指針、強指針和弱指針)的實現原理分析【轉】
其中 sin 類的定義 reason ava tab eas file 現在 Android系統的運行時庫層代碼是用C++來編寫的,用C++ 來寫代碼最容易出錯的地方就是指針了,一旦使用不當,輕則造成內存泄漏,重則造成系統崩潰。不過系統為我們提供了智能指針,避免出現上述問題
HashMap實現原理和源碼分析
aci 鍵值對 creat 變化 遍歷數組 沖突的解決 查看 seed 二分 作者: dreamcatcher-cx 出處: <http://www.cnblogs.com/chengxiao/>原文:https://www.cnblogs.com/cheng
Spring Cloud Eureka原理分析(一):註冊過程-服務端
Eureka的官方文件和Spring Cloud Eureka文件都有很多含糊的地方,其他資料也不多,只有讀讀原始碼維持生活這樣子…… 本文將不會詳細介紹每個細節,而是講述一些關鍵的地方,便於查閱。 一些好的參考資料 對讓人一臉懵逼的region和zone的解釋 攜程對Eureka機制的剖析
Spring Cloud Eureka原理分析(二):續租、下線、自我保護機制和自動清理(服務端)
續租、下線等操作比較直觀,實際上也不復雜。讓我們自己想想它們大概會在服務端有什麼操作。 renew: 更新Lease的lastUpdateTimestamp, 更新一下InstanceInfo的最新狀態。然後呼叫其他同伴節點的renew介面。 cancel:把lease從registry中移除,設
HashMap實現原理(jdk1.7/jdk1.8)
HashMap的底層實現: 1、簡單回答 JDK1.7:HashMap的底層實現是:陣列+連結串列 JDK1.8:HashMap的底層實現是:陣列+連結串列/紅黑樹 為什麼要紅黑樹? 紅黑樹:一個自平衡的二