
從Hadoop框架與MapReduce模式中談海量資料處理(含淘寶技術架構)
從hadoop框架與MapReduce模式中談海量資料處理
前言
幾周前,當我最初聽到,以致後來初次接觸Hadoop與MapReduce這兩個東西,我便稍顯興奮,覺得它們很是神祕,而神祕的東西常能勾起我的興趣,在看過介紹它們的文章或論文之後,覺得Hadoop是一項富有趣味和挑戰性的技術,且它還牽扯到了一個我更加感興趣的話題:海量資料處理。
由此,最近凡是空閒時,便在看“Hadoop”,“MapReduce”“海量資料處理”這方面的論文。但在看論文的過程中,總覺得那些論文都是淺嘗輒止,常常看的很不過癮,總是一個東西剛要講到緊要處,它便結束了,讓我好生“憤懣”。
儘管我對這個Hadoop與MapReduce知之甚淺,但我還是想記錄自己的學習過程,說不定,關於這個東西的學習能督促我最終寫成和“經典演算法研究系列”一般的一系列文章。
Ok,閒話少說。本文從最基本的mapreduce模式,Hadoop框架開始談起,然後由各自的架構引申開來,談到海量資料處理,最後談談淘寶的海量資料產品技術架構,以為了兼備淺出與深入之效,最終,希望得到讀者的喜歡與支援。謝謝。
由於本人是初次接觸這兩個東西,文章有任何問題,歡迎不吝指正。Ok,咱們開始吧。
第一部分、mapreduce模式與hadoop框架深入淺出
架構扼要
想讀懂此文,讀者必須先要明確以下幾點,以作為閱讀後續內容的基礎知識儲備:
- Mapreduce是一種模式。
- Hadoop是一種框架。
- Hadoop是一個實現了mapreduce模式的開源的分散式並行程式設計框架。
所以,你現在,知道了什麼是mapreduce,什麼是hadoop,以及這兩者之間最簡單的聯絡,而本文的主旨即是,一句話概括:在hadoop的框架上採取mapreduce的模式處理海量資料。下面,咱們可以依次深入學習和了解mapreduce和hadoop這兩個東西了。
Mapreduce模式
前面說了,mapreduce是一種模式,一種什麼模式呢?一種雲端計算的核心計算模式,一種分散式運算技術,也是簡化的分散式程式設計模式,它主要用於解決問題的程式開發模型,也是開發人員拆解問題的方法。
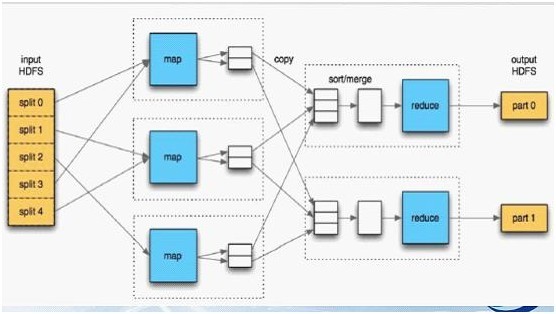
Ok,光說不上圖,沒用。如下圖所示,mapreduce模式的主要思想是將自動分割要執行的問題(例如程式)拆解成map(對映)和reduce(化簡)的方式,流程圖如下圖1所示:
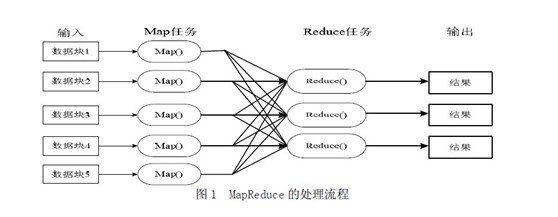
在資料被分割後通過Map 函式的程式將資料對映成不同的區塊,分配給計算機機群處理達到分散式運算的效果,在通過Reduce 函式的程式將結果彙整,從而輸出開發者需要的結果。
MapReduce 借鑑了函式式程式設計語言的設計思想,其軟體實現是指定一個Map 函式,把鍵值對(key/value)對映成新的鍵值對(key/value),形成一系列中間結果形式的key/value 對,然後把它們傳給Reduce(規約)函式,把具有相同中間形式key 的value 合併在一起。Map 和Reduce 函式具有一定的關聯性。函式描述如表1 所示:

MapReduce致力於解決大規模資料處理的問題,因此在設計之初就考慮了資料的區域性性原理,利用區域性性原理將整個問題分而治之。MapReduce叢集由普通PC機構成,為無共享式架構。在處理之前,將資料集分佈至各個節點。處理時,每個節點就近讀取本地儲存的資料處理(map),將處理後的資料進行合併(combine)、排序(shuffle and sort)後再分發(至reduce節點),避免了大量資料的傳輸,提高了處理效率。無共享式架構的另一個好處是配合複製(replication)策略,叢集可以具有良好的容錯性,一部分節點的down機對叢集的正常工作不會造成影響。
ok,你可以再簡單看看下副圖,整幅圖是有關hadoop的作業調優引數及原理,圖的左邊是MapTask執行示意圖,右邊是ReduceTask執行示意圖:
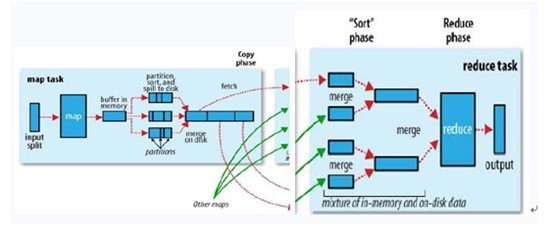
如上圖所示,其中map階段,當map task開始運算,併產生中間資料後並非直接而簡單的寫入磁碟,它首先利用記憶體buffer來對已經產生的buffer進行快取,並在記憶體buffer中進行一些預排序來優化整個map的效能。而上圖右邊的reduce階段則經歷了三個階段,分別Copy->Sort->reduce。我們能明顯的看出,其中的Sort是採用的歸併排序,即merge sort。
瞭解了什麼是mapreduce,接下來,咱們可以來了解實現了mapreduce模式的開源框架—hadoop。
Hadoop框架
前面說了,hadoop是一個框架,一個什麼樣的框架呢?Hadoop 是一個實現了MapReduce 計算模型的開源分散式並行程式設計框架,程式設計師可以藉助Hadoop 編寫程式,將所編寫的程式運行於計算機機群上,從而實現對海量資料的處理。
此外,Hadoop 還提供一個分散式檔案系統(HDFS)及分散式資料庫(HBase)用來將資料儲存或部署到各個計算節點上。所以,你可以大致認為:Hadoop=HDFS(檔案系統,資料儲存技術相關)+HBase(資料庫)+MapReduce(資料處理)。Hadoop 框架如圖2 所示:

藉助Hadoop 框架及雲端計算核心技術MapReduce 來實現資料的計算和儲存,並且將HDFS 分散式檔案系統和HBase 分散式資料庫很好的融入到雲端計算框架中,從而實現雲端計算的分散式、平行計算和儲存,並且得以實現很好的處理大規模資料的能力。
Hadoop的組成部分
我們已經知道,Hadoop是Google的MapReduce一個Java實現。MapReduce是一種簡化的分散式程式設計模式,讓程式自動分佈到一個由普通機器組成的超大叢集上併發執行。Hadoop主要由HDFS、MapReduce和HBase等組成。具體的hadoop的組成如下圖:
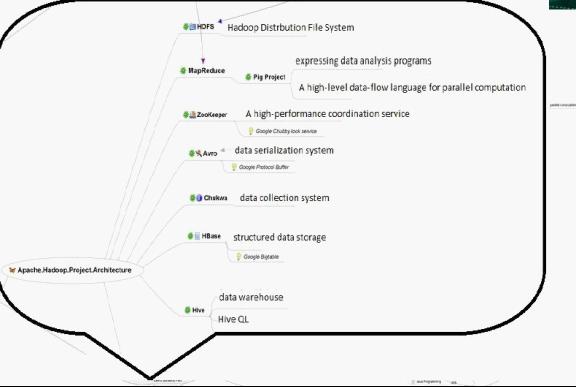
由上圖,我們可以看到:
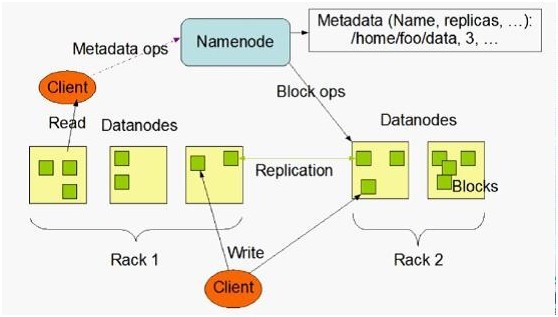
1、 Hadoop HDFS是Google GFS儲存系統的開源實現,主要應用場景是作為平行計算環境(MapReduce)的基礎元件,同時也是BigTable(如HBase、HyperTable)的底層分散式檔案系統。HDFS採用master/slave架構。一個HDFS叢集是有由一個Namenode和一定數目的Datanode組成。Namenode是一箇中心伺服器,負責管理檔案系統的namespace和客戶端對檔案的訪問。Datanode在叢集中一般是一個節點一個,負責管理節點上它們附帶的儲存。在內部,一個檔案其實分成一個或多個block,這些block儲存在Datanode集合裡。如下圖所示(HDFS體系結構圖):
2、 Hadoop MapReduce是一個使用簡易的軟體框架,基於它寫出來的應用程式能夠執行在由上千個商用機器組成的大型叢集上,並以一種可靠容錯的方式並行處理上TB級別的資料集。
一個MapReduce作業(job)通常會把輸入的資料集切分為若干獨立的資料塊,由 Map任務(task)以完全並行的方式處理它們。框架會對Map的輸出先進行排序,然後把結果輸入給Reduce任務。通常作業的輸入和輸出都會被儲存在檔案系統中。整個框架負責任務的排程和監控,以及重新執行已經失敗的任務。如下圖所示(Hadoop MapReduce處理流程圖):
3、 Hive是基於Hadoop的一個數據倉庫工具,處理能力強而且成本低廉。
主要特點:
儲存方式是將結構化的資料檔案對映為一張資料庫表。提供類SQL語言,實現完整的SQL查詢功能。可以將SQL語句轉換為MapReduce任務執行,十分適合資料倉庫的統計分析。
不足之處:
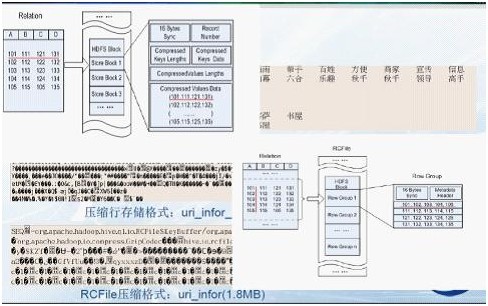
採用行儲存的方式(SequenceFile)來儲存和讀取資料。效率低:當要讀取資料表某一列資料時需要先取出所有資料然後再提取出某一列的資料,效率很低。同時,它還佔用較多的磁碟空間。
由於以上的不足,有人(查禮博士)介紹了一種將分散式資料處理系統中以記錄為單位的儲存結構變為以列為單位的儲存結構,進而減少磁碟訪問數量,提高查詢處理效能。這樣,由於相同屬性值具有相同資料型別和相近的資料特性,以屬性值為單位進行壓縮儲存的壓縮比更高,能節省更多的儲存空間。如下圖所示(行列儲存的比較圖):
4、 HBase
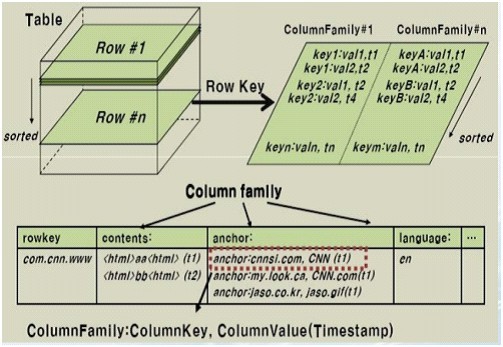
HBase是一個分散式的、面向列的開源資料庫,它不同於一般的關係資料庫,是一個適合於非結構化資料儲存的資料庫。另一個不同的是HBase基於列的而不是基於行的模式。HBase使用和 BigTable非常相同的資料模型。使用者儲存資料行在一個表裡。一個數據行擁有一個可選擇的鍵和任意數量的列,一個或多個列組成一個ColumnFamily,一個Fmaily下的列位於一個HFile中,易於快取資料。表是疏鬆的儲存的,因此使用者可以給行定義各種不同的列。在HBase中資料按主鍵排序,同時表按主鍵劃分為多個HRegion,如下圖所示(HBase資料表結構圖):
Ok,行文至此,看似洋洋灑灑近千里,但若給讀者造成閱讀上的負擔,則不是我本意。接下來的內容,我不會再引用諸多繁雜的專業術語,以給讀者心裡上造成不良影響。
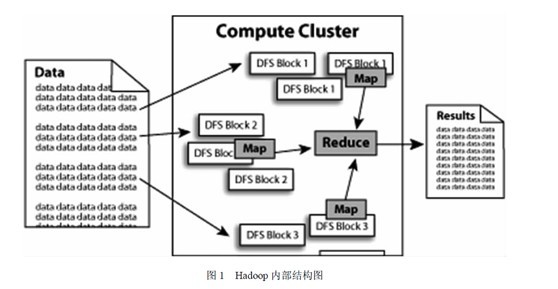
我再給出一副圖,算是對上文所說的hadoop框架及其組成部分做個總結,如下圖所示,便是hadoop的內部結構,我們可以看到,海量的資料交給hadoop處理後,在hadoop的內部中,正如上文所述:hadoop提供一個分散式檔案系統(HDFS)及分散式資料庫(Hbase)用來儲存或部署到各個計算點上,最終在內部採取mapreduce的模式對其資料進行處理,然後輸出處理結果:
第二部分、淘寶海量資料產品技術架構解讀—學習海量資料處理經驗
在上面的本文的第一部分中,我們已經對mapreduce模式及hadoop框架有了一個深入而全面的瞭解。不過,如果一個東西,或者一個概念不放到實際應用中去,那麼你對這個理念永遠只是停留在理論之內,無法向實踐邁進。
Ok,接下來,本文的第二部分,咱們以淘寶的資料魔方技術架構為依託,通過介紹淘寶的海量資料產品技術架構,來進一步學習和了解海量資料處理的經驗。
淘寶海量資料產品技術架構
如下圖2-1所示,即是淘寶的海量資料產品技術架構,咱們下面要針對這個架構來一一剖析與解讀。
相信,看過本部落格內其它文章的細心讀者,定會發現,圖2-1最初見於本部落格內的此篇文章:從幾幅架構圖中偷得半點海量資料處理經驗之上,同時,此圖2-1最初發表於《程式設計師》8月刊,作者:朋春。
在此之前,有一點必須說明的是:本文下面的內容大都是參考自朋春先生的這篇文章:淘寶資料魔方技術架構解析所寫,我個人所作的工作是對這篇文章的一種解讀與關鍵技術和內容的抽取,以為讀者更好的理解淘寶的海量資料產品技術架構。與此同時,還能展示我自己讀此篇的思路與感悟,順帶學習,何樂而不為呢?。
Ok,不過,與本部落格內之前的那篇文章(幾幅架構圖中偷得半點海量資料處理經驗)不同,本文接下來,要詳細闡述這個架構。我也做了不少準備工作(如把這圖2-1列印了下來,經常琢磨):
圖2-1 淘寶海量資料產品技術架構
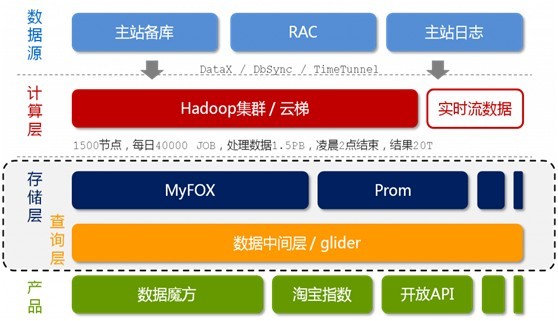
好的,如上圖所示,我們可以看到,淘寶的海量資料產品技術架構,分為以下五個層次,從上至下來看,它們分別是:資料來源,計算層,儲存層,查詢層和產品層。我們來一一瞭解這五層:
- 資料來源層。存放著淘寶各店的交易資料。在資料來源層產生的資料,通過DataX,DbSync和Timetunel準實時的傳輸到下面第2點所述的“雲梯”。
- 計算層。在這個計算層內,淘寶採用的是hadoop叢集,這個叢集,我們暫且稱之為雲梯,是計算層的主要組成部分。在雲梯上,系統每天會對資料產品進行不同的mapreduce計算。
- 儲存層。在這一層,淘寶採用了兩個東西,一個使MyFox,一個是Prom。MyFox是基於MySQL的分散式關係型資料庫的叢集,Prom是基於hadoop Hbase技術 的(讀者可別忘了,在上文第一部分中,咱們介紹到了這個hadoop的組成部分之一,Hbase—在hadoop之內的一個分散式的開源資料庫)的一個NoSQL的儲存叢集。
- 查詢層。在這一層中,有一個叫做glider的東西,這個glider是以HTTP協議對外提供restful方式的介面。資料產品通過一個唯一的URL來獲取到它想要的資料。同時,資料查詢即是通過MyFox來查詢的。下文將具體介紹MyFox的資料查詢過程。
- 產品層。簡單理解,不作過多介紹。
接下來,咱們重點來了解第三層-儲存層中的MyFox與Prom,然後會稍帶分析下glide的技術架構,最後,再瞭解下快取。文章即宣告結束。
我們知道,關係型資料庫在我們現在的工業生產中有著廣泛的引用,它包括Oracle,MySQL、DB2、Sybase和SQL Server等等。
MyFOX
淘寶選擇了MySQL的MyISAM引擎作為底層的資料儲存引擎。且為了應對海量資料,他們設計了分散式MySQL叢集的查詢代理層-MyFOX。
如下圖所示,是MySQL的資料查詢過程:

圖2-2 MyFOX的資料查詢過程
在MyFOX的每一個節點中,存放著熱節點和冷節點兩種節點資料。顧名思義,熱節點存放著最新的,被訪問頻率較高的資料;冷節點,存放著相對而來比較舊的,訪問頻率比較低的資料。而為了儲存這兩種節點資料,出於硬體條件和儲存成本的考慮,你當然會考慮選擇兩種不同的硬碟,來儲存這兩種訪問頻率不同的節點資料。如下圖所示:
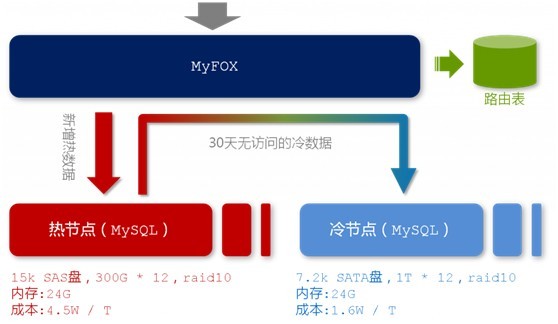
圖2-3 MyFOX節點結構
“熱節點”,選擇每分鐘15000轉的SAS硬碟,按照一個節點兩臺機器來計算,單位資料的儲存成本約為4.5W/TB。相對應地,“冷資料”我們選擇了每分鐘7500轉的SATA硬碟,單碟上能夠存放更多的資料,儲存成本約為1.6W/TB。
Prom
出於文章篇幅的考慮,本文接下來不再過多闡述這個Prom了。如下面兩幅圖所示,他們分別表示的是Prom的儲存結構以及Prom查詢過程:
圖2-4 Prom的儲存結構
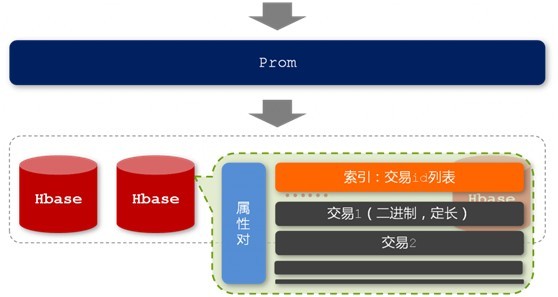
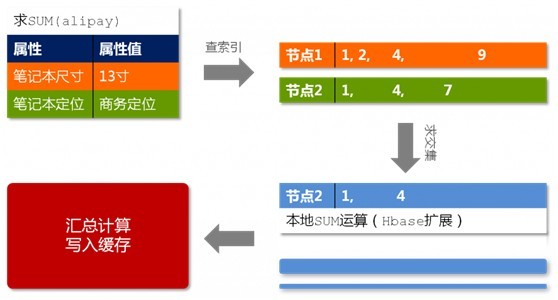
圖2-5 Prom查詢過程
glide的技術架構
圖2-6 glider的技術架構
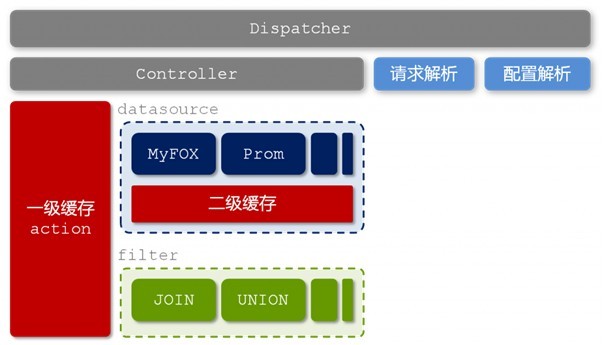
在這一層-查詢層中,淘寶主要是基於用中間層隔離前後端的理念而考慮。Glider這個中間層負責各個異構表之間的資料JOIN和UNION等計算,並且負責隔離前端產品和後端儲存,提供統一的資料查詢服務。
快取
除了起到隔離前後端以及異構“表”之間的資料整合的作用之外,glider的另外一個不容忽視的作用便是快取管理。我們有一點須瞭解,在特定的時間段內,我們認為資料產品中的資料是隻讀的,這是利用快取來提高效能的理論基礎。
在上文圖2-6中我們看到,glider中存在兩層快取,分別是基於各個異構“表”(datasource)的二級快取和整合之後基於獨立請求的一級快取。除此之外,各個異構“表”內部可能還存在自己的快取機制。
圖2-7 快取控制體系

圖2-7向我們展示了資料魔方在快取控制方面的設計思路。使用者的請求中一定是帶了快取控制的“命令”的,這包括URL中的query string,和HTTP頭中的“If-None-Match”資訊。並且,這個快取控制“命令”一定會經過層層傳遞,最終傳遞到底層儲存的異構“表”模組。
快取系統往往有兩個問題需要面對和考慮:快取穿透與失效時的雪崩效應。
- 快取穿透是指查詢一個一定不存在的資料,由於快取是不命中時被動寫的,並且出於容錯考慮,如果從儲存層查不到資料則不寫入快取,這將導致這個不存在的資料每次請求都要到儲存層去查詢,失去了快取的意義。至於如何有效地解決快取穿透問題,最常見的則是採用布隆過濾器(這個東西,在我的此篇文章中有介紹:),將所有可能存在的資料雜湊到一個足夠大的bitmap中,一個一定不存在的資料會被這個bitmap攔截掉,從而避免了對底層儲存系統的查詢壓力。
而在資料魔方里,淘寶採用了一個更為簡單粗暴的方法,如果一個查詢返回的資料為空(不管是資料不存在,還是系統故障),我們仍然把這個空結果進行快取,但它的過期時間會很短,最長不超過五分鐘。
2、快取失效時的雪崩效應儘管對底層系統的衝擊非常可怕。但遺憾的是,這個問題目前並沒有很完美的解決方案。大多數系統設計者考慮用加鎖或者佇列的方式保證快取的單執行緒(程序)寫,從而避免失效時大量的併發請求落到底層儲存系統上。
在資料魔方中,淘寶設計的快取過期機制理論上能夠將各個客戶端的資料失效時間均勻地分佈在時間軸上,一定程度上能夠避免快取同時失效帶來的雪崩效應。
本文參考:
- 基於雲端計算的海量資料儲存模型,侯建等。
- 基於hadoop的海量日誌資料處理,王小森
- 基於hadoop的大規模資料處理系統,王麗兵。
- 淘寶資料魔方技術架構解析,朋春。
- Hadoop作業調優引數整理及原理,guili。
讀者點評@xdylxdyl:
- We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That's map. The more people we get, the faster it goes. Now we get together and add our individual counts. That's reduce。
- 資料魔方里的快取穿透,架構,空資料快取這些和Hadoop一點關係都麼有,如果是想講一個Hadoop的具體應用的話,資料魔方這部分其實沒講清楚的。
- 感覺你是把兩個東西混在一起了。不過這兩個都是挺有價值的東西,或者說資料魔方的架構比Hadoop可能更重要一些,基本上大的網際網路公司都會選擇這麼做。Null物件的快取保留五分鐘未必會有好的結果吧,如果Null物件不是特別大,資料的更新和插入不多也可以考慮實時維護。
- Hadoop本身很笨重,不知道在資料魔方里是否是在扮演著實時資料處理的角色?還是隻是在做線下的資料分析的?
結語:寫文章是一種學習的過程。尊重他人勞動成果,轉載請註明出處。謝謝。July、2011/8/20。完。
相關推薦
從Hadoop框架與MapReduce模式中談海量資料處理(含淘寶技術架構)
從hadoop框架與MapReduce模式中談海量資料處理前言 幾周前,當我最初聽到,以致後來初次接觸Hadoop與MapReduce這兩個東西,我便稍顯興奮,覺得它們很是神祕,而神祕的東西常能勾起我的興趣,在看過介紹它們的文章或論文之後,覺得H
從Hadoop框架與MapReduce模式中談海量資料處理 含淘寶技術架構
從hadoop框架與MapReduce模式中談海量資料處理前言 幾周前,當我最初聽到,以致後來初次接觸Hadoop與MapReduce這兩個東西,我便稍顯興奮,覺得它們很是神祕,而神祕的東西常能勾起我的興趣,在看過介紹它們的文章或論文之後,覺得Ha
由散列表到BitMap的概念與應用(三):面試中的海量資料處理
一道面試題 在面試軟體開發工程師時,經常會遇到海量資料排序和去重的面試題,特別是大資料崗位。 例1:給定a、b兩個檔案,各存放50億個url,每個url各佔64位元組,記憶體限制是4G,找出a、b檔案共同的url? 首先我們最常想到的方法是讀取檔案a,建立雜湊表,然後再讀取檔案b,遍歷檔
g++ 記憶體分配 與 c 語言中的 陣列越界問題 (一道有趣的面試題)
首先是一段程式: # include <stdio.h> int main(int argc, char* argv[]){ int i = 0; int arr[3] = {0}; for(; i<=3; i++){ arr[i]
深度學習中張量flatten處理(flatten,reshape,reduce)
先看一下flatten的具體用法 1-對於一般數值,可以直接flatten >>> a=array([[1,2],[3,4],[5,6]]) >>> a array([[1, 2], [3, 4], [5, 6]]) &
從零開始,編寫簡單的課程資訊管理系統(使用jsp+servlet+javabean架構)
一、相關的軟體下載和環境配置 1、下載並配置JDK。 2、下載eclipse。 3、下載並配置apache-tomcat(伺服器)。 4、下載MySQL(資料庫)。 5、下載Navicat for MySQL(資料庫視覺化工具),方便對資料庫的操作。 6、下載jdbc用來實現eclipse中的專案
阿里架構師漫談:淘寶技術架構從1.0到4.0的架構變遷!附架構資料
MySQL優化概述MySQL資料庫常見的兩個瓶頸是:CPU和I/O的瓶頸。 CPU在飽和的時候一般發生在資料裝入記憶體或從磁碟上讀取資料時候。 磁碟I/O瓶頸發生在裝入資料遠大於記憶體容量的時候,如果應用分佈在網路上,那麼查詢量相當大的時候那麼平瓶頸就會出現在網路上
Vue2中的省市區三級聯動(仿淘寶)
三級聯動,隨著越來越多的審美,出現了很多種,好多公司都仿著淘寶的三級聯動 ,好看時尚,so我們公司也一樣……為了貼程式碼方便,我把寫在data裡面省市區的json獨立了出來,下載貼進去即可用,連結如下:http://download.csdn.net/detail/zhao
大資料07-Hadoop框架下MapReduce中的map個數如何控制
一個job的map階段並行度由客戶端在提交job時決定 客戶端對map階段並行度的規劃基本邏輯為: 一、將待處理的檔案進行邏輯切片(根據處理資料檔案的大小,劃分多個split),然後每一個split分配一個maptask並行處理例項 二、具體切片規劃是由FileInputFormat實現類的ge
【Java-POJO-設計模式】JavaEE中的POJO與設計模式中多型繼承的衝突
最近看《重構》談到利用OO的多型來優化 if else 和 switch 分支語句,但是我發現OO語法中的多型在使用框架的JavaEE中是無法實踐的。對此,我感到十分的疑惑,加之之前專案中有個“狀態模式”類的模組被頻繁改動的需求折磨要死,又去看了《設計模式》。《設計模式》中也是強調,使
Java IO框架與介面卡模式、裝飾器模式
IO框架: 介面卡模式: 介面卡模式(Adapter Pattern)是作為兩個不相容的介面之間的橋樑。這種型別的設計模式屬於結構型模式,它結合了兩個獨立介面的功能。 這種模式涉及到一個單一的類,該類負責加入獨立的或不相容的介面功能。舉個真實的例子,讀卡器是作為記憶體卡和筆
Hadoop框架:叢集模式下分散式環境搭建
本文原始碼:[GitHub·點這裡](https://github.com/cicadasmile/big-data-parent) || [GitEE·點這裡](https://gitee.com/cicadasmile/big-data-parent) # 一、基礎環境配置 ## 1、三臺服務 準
Hadoop框架:MapReduce基本原理和入門案例
本文原始碼:[GitHub·點這裡](https://github.com/cicadasmile/big-data-parent) || [GitEE·點這裡](https://gitee.com/cicadasmile/big-data-parent) # 一、MapReduce概述 ## 1、基本
(轉載)利用SIFT和RANSAC算法(openCV框架)實現物體的檢測與定位,並求出變換矩陣(findFundamentalMat和findHomography的比較) 置頂
bsp 解釋 邊界 返回值 class 不同的 rip 很多 per 原文鏈接:https://blog.csdn.net/qq_25352981/article/details/46914837#commentsedit 本文目標是通過使用SIFT和RANSAC算
基於vue框架專案開發過程中遇到的問題總結(一)
(一)關於computed修改data裡變數的值 問題:computed裡是不能直接修改data裡變數的值,否則在git commit 時會報錯 解決:在computed裡使用get和set來進行獲取和修改data變數,(參考下圖) (二)computed裡監聽陣列
從Jackrabbit庫中下載檔案到web(涉及到inputStream轉byte[])
專案中用到了Jackrabbit庫的使用,我這塊主要負責的是查詢,前後臺展示的資料大部分是從Jackrabbit庫中查詢得來的,庫的檔案以二進位制的形式進行的儲存,當寫到元檔案的下載的時候卡殼了,特此記
[PC技術]硬碟從IDE修改為AHCI模式後藍屏如何處理?
這幾天將win7換到了64位下,本來想虛擬機器裝Mac,結果CPU因為不支援VT,所以就作罷了,不想折騰VMware了,太麻煩了。當時磁碟換到IDE模式下之後,忘了換回來了,直接裝了Win7 x64,完了之後換回來卻藍屏了,連錯誤都不給我看。查了查原來是有方法可以修改的。1.開啟登錄檔,Win + R 輸入r
北京市律典通總裁麥天驥:從法律人對人工智慧的期待談大資料——人工智慧在智慧法院的應用
當前階段,法院的基本矛盾已經發生轉化,已經由重視審判管理和增強審判過程的規範化變為案多人少和司法資源分配不均。因此無論是智慧法院建設還是法院資訊化建設都應以審判業務為中心 作者 | 麥天驥 官網 | www.datayuan.cn 微信公眾號ID | datayuancn 2017年11月10日,由上海大
負載均衡時,在State_Server模式中的Session共享問題(不討論負載均衡的問題)
) {//筆者注:這是一個很重要的out引數 int hr; string uri; OutOfProcConnection c
[面試題]海量資料處理-從10億個數中找頻率最高的1000個數
方法一:分治思想 通常比較好的方案是分治+Trie樹/hash+小頂堆(就是上面提到的最小堆),即先將資料集按照Hash方法分解成多個小資料集,然後使用Trie樹或者Hash統計每個小資料集中的que