
python爬蟲(一)爬取豆瓣電影Top250
提示:完整程式碼附在文末
一、需要的庫
requests:獲得網頁請求
BeautifulSoup:處理資料,獲得所需要的資料
二、爬取豆瓣電影Top250
爬取內容為:豆瓣評分前二百五位電影的名字、主演、以及該電影的簡介。
首先先進入豆瓣電影Top250,開啟審查元素,找到所要爬取的電影名、主演以及電影主頁的連結都在標籤<div class="info">中間,如下圖所示
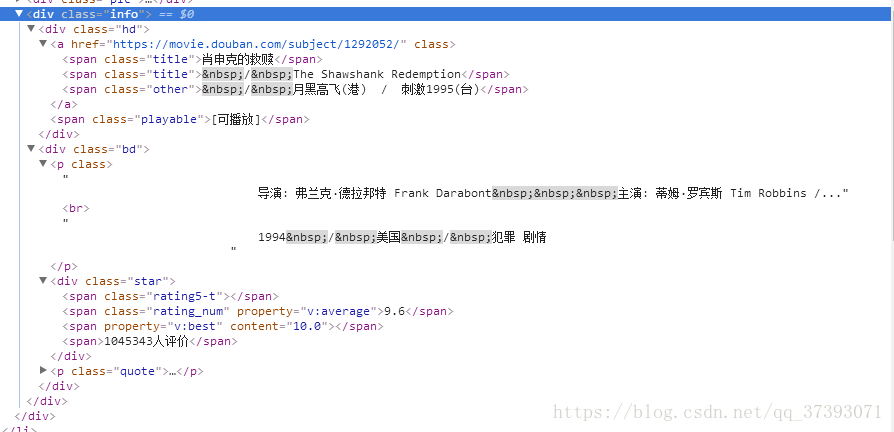
對於電影名和導演主演這些資訊是可以直接獲取的:

content_list中包含所有標籤為<div class="info">的內容。
對於電影簡介,則需要先進入該電影介面,再獲取。而進入電影主頁的連結就儲存在div下第一個a標籤的‘href’屬性中,獲取方法如下:
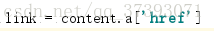
得到link之後,獲取link內容,因為Top250中存在連結打不開的現象,所以我加了一個if語句,過濾掉無效的link。手動開啟任意一個link,從審查元素中定位電影簡介的位置,得知資訊儲存在<span property="v:summary">中,獲取資訊。

三、資料儲存
我這裡建立裡一個資料夾,以每個電影名命名建立各自的TXT檔案寫入title、star、summary。

四、總結
這個實踐時比較基礎的,但在其中也發現了BeautifulSoup庫定位時還是比較麻煩的,新手理解很快,但在實踐中還是需要眼力的。
完整程式碼:
#encoding=utf-8 import bs4 from bs4 import BeautifulSoup import requests import os def get_html(url): try: header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"} r = requests.get(url,timeout = 30,headers=header) r.raise_for_status() print(r.text) return r.text except : return "error" def print_content(html): soup = BeautifulSoup(html,'html.parser') content_list = soup.find_all('div',attrs={'class':'info'}) #os.mkdir(path) print(type(content_list)) print(len(content_list)) for content in content_list: title = content.find('span').text star = content.find('p').text.replace(' ','').replace(' ','') link = content.a['href'] title = content.find('span').text print(link) print(title) html = get_html(link) if(html != "error"): soup = BeautifulSoup(html,'lxml') summary = soup.find('span',{'property':'v:summary'}).text.replace(' ','') #print(summary) else: print("None") fpath = path + "\\" + title+".txt" with open(fpath,'w',encoding="utf-8") as f: f.write(title) f.write(star) f.write(summary) f.close() i =0 while i<250: path = "E:\\Compile Tools\\python\\寫的程式放在這裡\\moive" url = "https://movie.douban.com/top250?start="+str(i) html = get_html(url) print_content(html) i = i+25
相關推薦
python爬蟲(一)爬取豆瓣電影Top250
提示:完整程式碼附在文末 一、需要的庫 requests:獲得網頁請求 BeautifulSoup:處理資料,獲得所需要的資料 二、爬取豆瓣電影Top250 爬取內容為:豆瓣評分前二百五位電影的名字、主演、
scrapy入門實戰練習(一)----爬取豆瓣電影top250
轉自知乎網工具和環境語言:python 2.7IDE: Pycharm瀏覽器:Chrome爬蟲框架:Scrapy 1.2.1教程正文觀察頁面結構通過觀察頁面決定讓我們的爬蟲獲取每一部電影的排名、電影名稱、評分和評分的人數。宣告ItemItems爬取的主要目標就是從非結構性的資
Scrapy爬蟲(4)爬取豆瓣電影Top250圖片
在用Python的urllib和BeautifulSoup寫過了很多爬蟲之後,本人決定嘗試著名的Python爬蟲框架——Scrapy. 本次分享將詳細講述如何利用Scrapy來下載豆瓣電影Top250, 主要解決的問題有: 如何利用ImagesPi
python 爬蟲實戰(一)爬取豆瓣圖書top250
import requests from lxml import etree with open('booktop250.txt','w',encoding='utf-8') as f: f
python爬蟲實踐——零基礎快速入門(二)爬取豆瓣電影
爬蟲又稱為網頁蜘蛛,是一種程式或指令碼。 但重點在於,它能夠按照一定的規則,自動獲取網頁資訊。 爬蟲的基本原理——通用框架 1.挑選種子URL; 2.講這些URL放入帶抓取的URL列隊; 3.取出帶抓取的URL,下載並存儲進已下載網頁庫中。此外,講這些URL放入帶抓取UR
python爬蟲【例項】爬取豆瓣電影評分連結並圖示()-問題如何爬取電影圖片(解決有程式碼)
這裡只有尾巴,來分析一下確定範圍:如何爬取圖片並下載?參考:http://blog.csdn.net/chaoren666/article/details/53488083----------------------------------------------------
python 爬蟲(五)爬取多頁內容
import urllib.request import ssl import re def ajaxCrawler(url): headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/5
PyQt5與爬蟲(一)——爬取某站動畫每週列表
某站動畫列表PyQt程式截圖,可以點選圖片按鈕,然後會開啟谷歌瀏覽器到你選擇的動漫介面。貼程式碼:main.pyfrom PyQt5.QtWidgets import QWidget,QApplication import sys from MyWidget import W
Python3 爬蟲(三) -- 爬取豆瓣首頁圖片
序 前面已經完成了簡單網頁以及偽裝瀏覽器的學習。下面,實現對豆瓣首頁所有圖片爬取程式,把圖片儲存到本地一個路徑下。 首先,豆瓣首頁部分圖片展示 這只是擷取的一部分。下面給出,整個爬蟲程式。 爬蟲程式
python爬蟲(三)爬取網易雲音樂歌曲列表
1.開啟網易雲音樂列表,按F12,選擇Doc模式,方便檢視。2.檢視網頁的請求方式--get請求3.檢視header4. 在Preview中搜索任意一首歌曲,比如:無由可以看到,歌曲列表在‘ul’標籤中,那麼我們可以通過Be阿UtigulSoup去搜索明晰了結構,就可以寫程式
Python爬蟲練習三:爬取豆瓣電影分類排行榜
目標網址url: https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action= 使用谷歌瀏覽器的檢查
Python爬蟲入門 | 7 分類爬取豆瓣電影,解決動態載入問題
比如我們今天的案例,豆瓣電影分類頁面。根本沒有什麼翻頁,需要點選“載入更多”新的電影資訊,前面的黑科技瞬間被秒…… 又比如知乎關注的人列表頁面: 我複製了其中兩個人暱稱的 xpath: //*[@id="Popov
小白學 Python 爬蟲(24):2019 豆瓣電影排行
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
【go語言爬蟲】go語言爬取豆瓣電影top250
抓取欄位:電影名稱、評分、評價人數 二、執行: 正在抓取第0頁…… 肖申克的救贖 9.6 824764人 這個殺手不太冷 9.4 791399人 霸王別姬 9.5 589028人 阿甘正傳 9.4 678850人 美麗人生 9.5 3940
爬蟲專案:requests爬取豆瓣電影TOP250存入excel中
這次爬取是爬取250部電影的相關內容,分別用了requests請求url,正則表示式re與BeautifulSoup作為內容過濾openpyxl作為excel的操作模組,本人為才學不久的新手,程式碼編寫有點無腦和囉嗦,希望有大神能多提建議 首先,程式碼清單如下:
Python爬蟲之利用BeautifulSoup爬取豆瓣小說(三)——將小說信息寫入文件
設置 one 行為 blog 應該 += html uil rate 1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 5 class dbxs: 6 7
Python爬蟲實例(一)爬取百度貼吧帖子中的圖片
選擇 圖片查看 負責 targe mpat wid agent html headers 程序功能說明:爬取百度貼吧帖子中的圖片,用戶輸入貼吧名稱和要爬取的起始和終止頁數即可進行爬取。 思路分析: 一、指定貼吧url的獲取 例如我們進入秦時明月吧,提取並分析其有效url如下
python 爬蟲(一) requests+BeautifulSoup 爬取簡單網頁代碼示例
utf-8 bs4 rom 文章 都是 Coding man header 文本 以前搞偷偷摸摸的事,不對,是搞爬蟲都是用urllib,不過真的是很麻煩,下面就使用requests + BeautifulSoup 爬爬簡單的網頁。 詳細介紹都在代碼中註釋了,大家可以參閱。
Python爬蟲入門實戰系列(一)--爬取網路小說並存放至txt檔案
執行平臺: Windows Python版本: Python3.x 一、庫檔案
(7)Python爬蟲——爬取豆瓣電影Top250
利用python爬取豆瓣電影Top250的相關資訊,包括電影詳情連結,圖片連結,影片中文名,影片外國名,評分,評價數,概況,導演,主演,年份,地區,類別這12項內容,然後將爬取的資訊寫入Excel表中。基本上爬取結果還是挺好的。具體程式碼如下: #!/us