
PyQt5與爬蟲(一)——爬取某站動畫每週列表
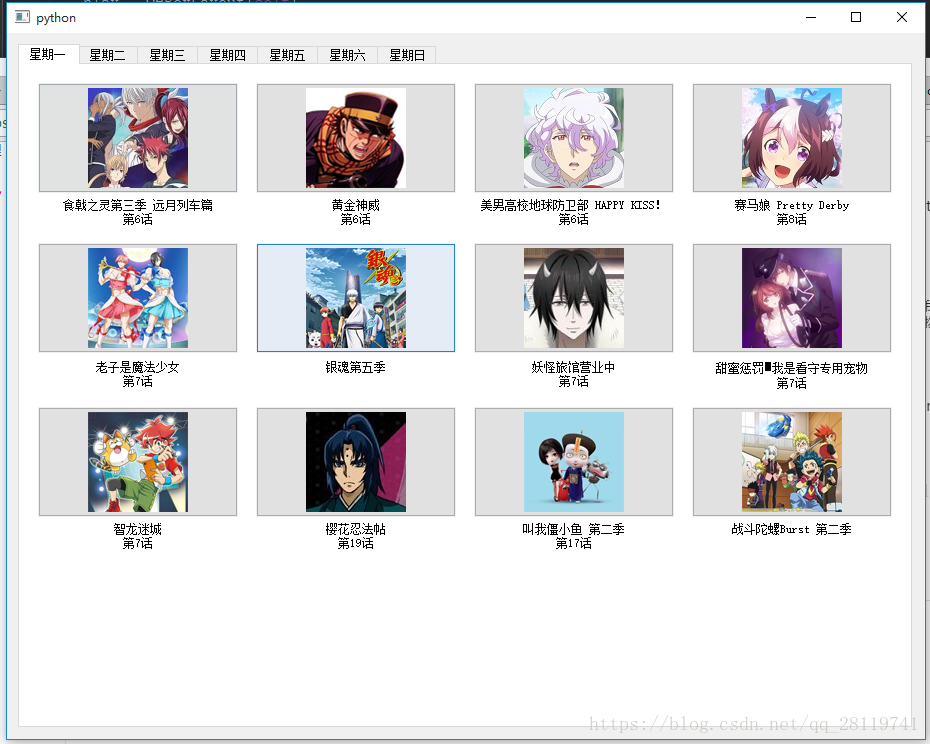
某站動畫列表

PyQt程式截圖,可以點選圖片按鈕,然後會開啟谷歌瀏覽器到你選擇的動漫介面。

貼程式碼:
main.py
from PyQt5.QtWidgets import QWidget,QApplication import sys from MyWidget import Widget if __name__ == '__main__': app = QApplication(sys.argv) w = Widget() w.show() sys.exit(app.exec_())
MyWidegt.py
from PyQt5.QtWidgets import QWidget,QTabWidget,QHBoxLayout from TabWidget import Tab from bs4 import BeautifulSoup import requests import pathlib from PyQt5.QtGui import * from PyQt5.QtCore import * class Widget(QWidget): def __init__(self): super().__init__() self.resize(800,450) self.tabWidget = QTabWidget(self) hlay = QHBoxLayout(self) hlay.addWidget(self.tabWidget) self.setLayout(hlay) L = ["星期一","星期二","星期三","星期四","星期五","星期六","星期日"] self.tab1 = Tab() self.tab2 = Tab() self.tab3 = Tab() self.tab4 = Tab() self.tab5 = Tab() self.tab6 = Tab() self.tab7 = Tab() self.tabWidget.addTab(self.tab1, L[0]) self.tabWidget.addTab(self.tab2, L[1]) self.tabWidget.addTab(self.tab3, L[2]) self.tabWidget.addTab(self.tab4, L[3]) self.tabWidget.addTab(self.tab5, L[4]) self.tabWidget.addTab(self.tab6, L[5]) self.tabWidget.addTab(self.tab7, L[6]) # self.tabWidget.currentChanged[int].connect(self.recvChanged) self.url = "http://www.dilidili.wang/" html = requests.get(self.url).content.decode('utf-8') soup = BeautifulSoup(html, 'lxml') self.rets = soup.select("ul.wrp.animate") for i in range(7): self.recvChanged(i) def parseHtml(self,html,index): tooltips = html.select('a.tooltip') for tooltip in tooltips: href = tooltip['href'] src = tooltip.select('img')[0]['src'] # name = tooltip.select('p')[0].get_text() # name = "" num = str("") span = str("") t = tooltip.select('span') if len(t) > 0: span = t[0].get_text() if len(tooltip.select('p')) > 1: name = tooltip.select('p')[0].get_text() num = tooltip.select('p')[1].get_text() else: name = tooltip.select('p')[0].get_text() # print(self.url +href, self.url + src, name, num, span) pixture = name+'.jpg' path = pathlib.Path(pixture) if not path.exists(): print(path) tupian = requests.get(self.url+src).content with open(pixture,'wb') as f: f.write(tupian) f.close() if index == 0: self.tab1.setParams(self.url+href,pixture,name,num,span) elif index == 1: self.tab2.setParams(self.url + href, pixture, name, num, span) elif index == 2: self.tab3.setParams(self.url + href, pixture, name, num, span) elif index == 3: self.tab4.setParams(self.url + href, pixture, name, num, span) elif index == 4: self.tab5.setParams(self.url + href, pixture, name, num, span) elif index == 5: self.tab6.setParams(self.url + href, pixture, name, num, span) elif index == 6: self.tab7.setParams(self.url + href, pixture, name, num, span) pass def recvChanged(self,index): # tools = self.tabWidget.findChildren(QToolButton,'', Qt.FindChildrenRecursively) # print(index) if index == 0: for ret in self.rets: htmls = ret.select("li.elmnt-one > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 1: for ret in self.rets: htmls = ret.select("li.elmnt-two > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 2: for ret in self.rets: htmls = ret.select("li.elmnt-three > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 3: for ret in self.rets: htmls = ret.select("li.elmnt-four > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 4: for ret in self.rets: htmls = ret.select("li.elmnt-five > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 5: for ret in self.rets: htmls = ret.select("li.elmnt-six > div.book.small") for html in htmls: self.parseHtml(html,index) elif index == 6: for ret in self.rets: htmls = ret.select("li.elmnt-seven > div.book.small") for html in htmls: self.parseHtml(html,index)
TabWidget.py
from PyQt5.QtWidgets import QWidget,QTabWidget,QHBoxLayout,QVBoxLayout,QGridLayout,QPushButton,QToolButton from PyQt5.QtGui import QIcon,QPixmap from PyQt5.QtCore import * from MyBtn import MyButton from PyQt5.QtNetwork import QNetworkRequest class Tab(QWidget): def __init__(self): super().__init__() self.gridLay = QGridLayout() self.gridLay.setAlignment(Qt.AlignCenter) self.setLayout(self.gridLay) self.gridLay.setSpacing(0) self.gridLay.setAlignment(Qt.AlignTop) self.count = 0 def setParams(self,href,src,name,num,span): row = self.count / 4 col = self.count % 4 self.count += 1 btn = MyButton() # btn.setToolButtonStyle(Qt.ToolButtonTextUnderIcon) self.gridLay.addWidget(btn,row,col) # btn.setIconSize(QSize(50,50)) btn.setBtnIcon(QIcon(src)) btn.setLabelText(name + "\n" + num) btn.setHref(href) btn.setNewSpan(span) #傳遞額外引數,這個有點好用啊 # btn.clicked.connect(lambda : self.onClicked(href)) # def onClicked(self,href): # # wd = webdriver.Chrome() # wd.get(href) # pass
MyBtn.py
from PyQt5.QtWidgets import QWidget,QVBoxLayout,QLabel,QPushButton from selenium import webdriver from PyQt5.QtCore import * from PyQt5.QtGui import * class MyButton(QWidget): def __init__(self): super().__init__() vbox = QVBoxLayout(self) self.btn = QPushButton(self) self.label = QLabel(self) self.label.setAlignment(Qt.AlignCenter) self.btn.clicked.connect(self.onClicked) self.btn.setFixedSize(200,110) self.btn.setIconSize(QSize(200,110)) self.btn.setAutoFillBackground(True) # self.btn.setFlat(True) vbox.addWidget(self.btn) vbox.addWidget(self.label) self.href = str() self.setLayout(vbox) self.span = str() def setBtnIcon(self,pix): self.btn.setIcon(pix) def setLabelText(self,str): self.label.setText(str) def setHref(self,href): self.href = href def onClicked(self): wd = webdriver.Chrome() wd.get(self.href) def setNewSpan(self,sp): self.span = sp self.update() def paintEvent(self, QPaintEvent): painter = QPainter(self) painter.setPen(QPen(Qt.red)) painter.drawText(self.rect(),Qt.AlignRight,self.span) pass
相關推薦
PyQt5與爬蟲(一)——爬取某站動畫每週列表
某站動畫列表PyQt程式截圖,可以點選圖片按鈕,然後會開啟谷歌瀏覽器到你選擇的動漫介面。貼程式碼:main.pyfrom PyQt5.QtWidgets import QWidget,QApplication import sys from MyWidget import W
python爬蟲(一)爬取豆瓣電影Top250
提示:完整程式碼附在文末 一、需要的庫 requests:獲得網頁請求 BeautifulSoup:處理資料,獲得所需要的資料 二、爬取豆瓣電影Top250 爬取內容為:豆瓣評分前二百五位電影的名字、主演、
java爬蟲(Jsoup)爬取某站點評論
在上一篇中,我們抓取到了新聞的標題,超連結和摘要,這次我們通過新聞的超連結,進入新聞的評論頁,然後爬取評論! 先看下評論頁的標籤: 主要是尋找id為“art_content”的標籤下的 id為“text”下的“div”標籤。 程式碼: p
Python爬蟲實例(一)爬取百度貼吧帖子中的圖片
選擇 圖片查看 負責 targe mpat wid agent html headers 程序功能說明:爬取百度貼吧帖子中的圖片,用戶輸入貼吧名稱和要爬取的起始和終止頁數即可進行爬取。 思路分析: 一、指定貼吧url的獲取 例如我們進入秦時明月吧,提取並分析其有效url如下
Python爬蟲入門實戰系列(一)--爬取網路小說並存放至txt檔案
執行平臺: Windows Python版本: Python3.x 一、庫檔案
python爬蟲學習筆記(一)—— 爬取騰訊視訊影評
前段時間我忽然想起來,以前本科的時候總有一些公眾號,能夠為我們提供成績查詢、課表查詢等服務。我就一直好奇它是怎麼做到的,經過一番學習,原來是運用了爬蟲的原理,自動登陸教務系統爬取的成績等內容。我覺得挺好玩的,於是自己也琢磨了一段時間,今天呢,我為大家分享一個爬蟲
python 爬蟲實戰(一)爬取豆瓣圖書top250
import requests from lxml import etree with open('booktop250.txt','w',encoding='utf-8') as f: f
Python爬蟲學習6:scrapy入門(一)爬取汽車評論並儲存到csv檔案
一、scrapy 安裝:可直接使用Anaconda Navigator安裝, 也可使用pip install scrapy安裝二、建立scrapy 爬蟲專案:語句格式為 scrapy startproject project_name生成的爬蟲專案目錄如下,其中spiders
Python開發簡單爬蟲(二)---爬取百度百科頁面數據
class 實例 實例代碼 編碼 mat 分享 aik logs title 一、開發爬蟲的步驟 1.確定目標抓取策略: 打開目標頁面,通過右鍵審查元素確定網頁的url格式、數據格式、和網頁編碼形式。 ①先看url的格式, F12觀察一下鏈接的形式;② 再看目標文本信息的
爬蟲(GET)——爬取多頁的html
調度 不同 odin 新建 文件內容 存儲 rom 寫入 adp 工具:python3 目標:將編寫的代碼封裝,不同函數完成不同功能,爬取任意頁數的html 新學語法:with open as 除了有更優雅的語法,with還可以很好的處理上下文環境產生的
Scrapy爬蟲(5)爬取當當網圖書暢銷榜
The log sdn detail iss 就是 pan 微信公眾號 打開 ??本次將會使用Scrapy來爬取當當網的圖書暢銷榜,其網頁截圖如下: ??我們的爬蟲將會把每本書的排名,書名,作者,出版社,價格以及評論數爬取出來,並保存為csv格式的文件。項目的具體創建就不
網易雲音樂評論爬蟲(三):爬取歌曲的全部評論
用過網易雲音樂聽歌的朋友都知道,網易雲音樂每首歌曲後面都有很多評論,熱門歌曲的評論更是接近百萬或者是超過百萬條.現在我就來分享一下如何爬取網易雲音樂歌曲的全部評論,由於網易雲音樂的評論都做了混淆加密處理,因此我們需要深入瞭解它的加密過程之後才能爬取到網易雲音樂歌曲的全部評論. 一,首
python 爬蟲(五)爬取多頁內容
import urllib.request import ssl import re def ajaxCrawler(url): headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/5
Python3爬蟲(一)抓取網頁的html
因為程式碼只有幾行,所以可以先貼程式碼: import urllib.request url = r'http://douban.com' res = urllib.request.urlopen(url) html = res.read().decode('utf-
scrapy入門實戰練習(一)----爬取豆瓣電影top250
轉自知乎網工具和環境語言:python 2.7IDE: Pycharm瀏覽器:Chrome爬蟲框架:Scrapy 1.2.1教程正文觀察頁面結構通過觀察頁面決定讓我們的爬蟲獲取每一部電影的排名、電影名稱、評分和評分的人數。宣告ItemItems爬取的主要目標就是從非結構性的資
Scrapy爬蟲(4)爬取豆瓣電影Top250圖片
在用Python的urllib和BeautifulSoup寫過了很多爬蟲之後,本人決定嘗試著名的Python爬蟲框架——Scrapy. 本次分享將詳細講述如何利用Scrapy來下載豆瓣電影Top250, 主要解決的問題有: 如何利用ImagesPi
網易雲音樂(一)爬取全部歌手及歌手id
動聽的音樂,走心的評論。 總會使人不斷的遐想... 本系列將爬取分析網易雲音樂最動聽的音樂,最走心的評論。 本次爬取網易雲音樂的所以歌手及歌手id。 一、網頁分析 1.標籤 通過點選左邊已經分好類的標籤及頂部的ABC等分類標籤,得到網址地址引數。
Python3 爬蟲(三) -- 爬取豆瓣首頁圖片
序 前面已經完成了簡單網頁以及偽裝瀏覽器的學習。下面,實現對豆瓣首頁所有圖片爬取程式,把圖片儲存到本地一個路徑下。 首先,豆瓣首頁部分圖片展示 這只是擷取的一部分。下面給出,整個爬蟲程式。 爬蟲程式
Scrapy爬蟲(5)爬取噹噹網圖書暢銷榜
本次將會使用Scrapy來爬取噹噹網的圖書暢銷榜,其網頁截圖如下: 我們的爬蟲將會把每本書的排名,書名,作者,出版社,價格以及評論數爬取出來,並儲存為csv格式的檔案。專案的具體建立就不再多講,可以參考上一篇部落格,我們只需要修改items.py檔
python爬蟲(三)爬取網易雲音樂歌曲列表
1.開啟網易雲音樂列表,按F12,選擇Doc模式,方便檢視。2.檢視網頁的請求方式--get請求3.檢視header4. 在Preview中搜索任意一首歌曲,比如:無由可以看到,歌曲列表在‘ul’標籤中,那麼我們可以通過Be阿UtigulSoup去搜索明晰了結構,就可以寫程式