
Greenplum+Hadoop學習筆記-Greenplum概述及架構
0.寫在前面:
0.1. 此筆記是參考《Greenplum企業應用實戰》、《PostgreSQL8.2.3 中文文件》和《Getting Started with Greenplum for Big Data Analytics》整理;
0.2. 《Greenplum企業應用實戰》購買地址:【京東商城】 【 噹噹網】
0.3.參考網頁(持續更新)
1. Greenplum概述及架構
1.1. 什麼是Greenplum
1) 為全球大型企業使用者提供新型企業級資料倉庫(EDW)、企業級資料雲(EDC)和商務智慧(BI)提供解決方案和諮詢服務,專注於OLAP系統資料引擎開發;
2) 海量並行處理(Massively Parallel Processing) DBMS:
Greenplum的架構採用了MPP(大規模並行處理),在 MPP 系統中,每個 SMP節點也可以執行自己的作業系統、資料庫等。換言之,每個節點內的 CPU 不能訪問另一個節點的記憶體。節點之間的資訊互動是通過節點網際網路絡實現的,這個過程一般稱為資料重分配(Data Redistribution) 。
SMP(SymmetricMulti-Processing),對稱多處理結構的簡稱,是指在一個計算機上彙集了一組處理器(多CPU),各CPU之間共享記憶體子系統以及匯流排結構。在這種技術的支援下,一個伺服器系統可以同時執行多個處理器,並共享記憶體和其他的主機資源。傳統的ORACLE和DB2均是此種類型,ORACLE RAC 是半共享狀態;
與傳統的SMP架構明顯不同,通常情況下,MPP系統因為要在不同處理單元之間傳送資訊,所以它的效率要比SMP要差一點,但是這也不是絕對的,因為 MPP系統不共享資源,因此對它而言,資源比SMP要多,當需要處理的事務達到一定規模時,MPP的效率要比SMP好。這就是看通訊時間佔用計算時間的比例而定,如果通訊時間比較多,那MPP系統就不佔優勢了,相反,如果通訊時間比較少,那MPP系統可以充分發揮資源的優勢,達到高效率。
3) 基於PostgreSQL 8.2開源版本,具有相同的客戶端功能,增加支援並行處理的技術,增加支援資料倉庫和BI的特性;
4) 外部表(external tables)/並行載入(parallel loading):外部表是指資料庫可以直接使用作業系統中的資料檔案,在Greenplum 4.2版本中支援對外部表的讀寫操作;
5) 資源管理:基於PostgreSQL增加了並行度的處理;
6) 查詢優化器增強(query optimizer enhancements):增加對分散式的支援,空間的回收和分析,不需要進行多方面的調優。
1.2. Greenplum 體系架構
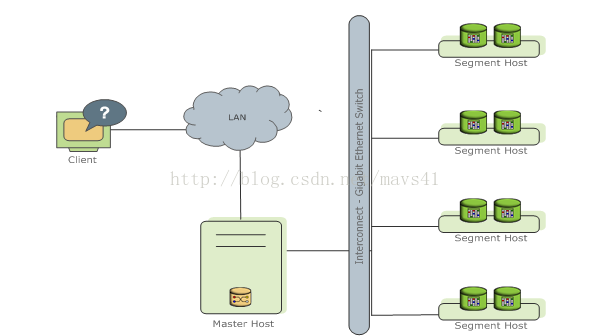
圖一
Greenplum是一種基於ProstgreSQL的分散式資料庫,其採用Shared-Nothing架構、主機、作業系統、記憶體、儲存都是自我控制的,不存在共享。
補充:SharedDisk與Shared Nothing介紹
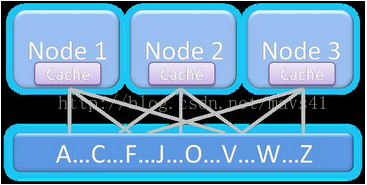
圖二

圖三
|
比較事項 |
概述 |
優點 |
缺點 |
使用場景 |
|
Shared Disk |
如圖二所示,所有節點共享一份資料 |
只要有一個節點就可以訪問所有資料 |
記憶體融合限制水平擴充套件能力 |
Oracle RAC,24*7的高可用性核心業務 |
|
Shared Nothing |
如圖三所示,資料和節點有一一對應關係 |
每個節點互動少,很容易擴充套件 |
如果需要訪問所有資料,需要所有節點都可用 |
SQL Server、DB2、Hadoop以及Greenplum |
1.2.1.Master Host
1) 建立與客戶端的會話連線和管理;
2) SQL的解析並形成分散式的執行計劃;
3) 將生成好的執行計劃分發到每個Segment上執行;
4) 收集Segment的執行結果;
5) 不儲存業務資料,只儲存資料字典;
6) 可以一主一備,分佈在兩臺機器上,為了提高效能,最好單獨佔用一臺機器。
1.2.2.Segment Host
1) 業務資料的儲存和存取;
2) 執行由Master分發的SQL語句;
3) 對於Master來說,每個Segment都是對等的,負責對應資料的儲存和計算;
4) 每一臺機器上可以配置一到多個Segment,因此建議採用相同的機器配置。
1.2.3.Interconnect
1) 是GP資料庫的網路層,在每個Segment中起到一個IPC作用;
2) 推薦使用千兆乙太網交換機做Interconnect;
3) 支援UDP和TCP兩種協議,推薦使用UDP協議,因為其高可靠性、高效能以及可擴充套件性;而TCP協議最高只能使用1000個Segment例項。
1.3.網路配置示例
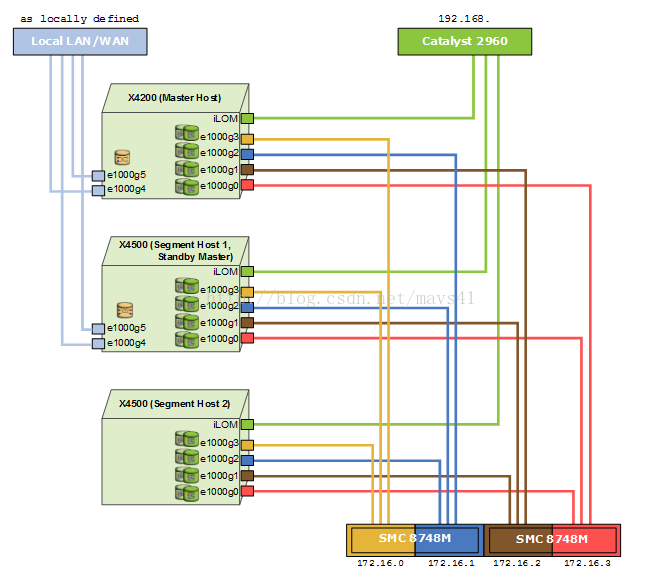
圖四
圖四顯示一個常見的網路配置示例,其中X4200是主節點,X4500(Segment host1)是主從節點,當主節點宕機後會主節點服務切換到此節點上,X4500(Segment host2)是從節點。
每個網路介面對應不同的網口,隔離到獨立網路,保證不會競爭其他埠的網路頻寬,提高網路的可靠性;串列埠連線到交換機是管理員管理的視窗。
1.4.Greenplum 高可用性體系架構
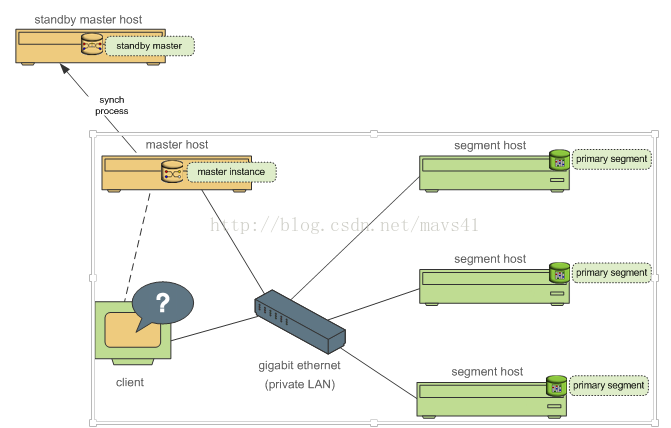
圖五
圖五中顯示高可用性體系的示例圖,其中按照從左到右且從上到下依次是主從節點,主節點,客戶端,私有區域網以及從節點叢集,實現功能和圖一基本一致。
1.5.Master/Standby 映象保護
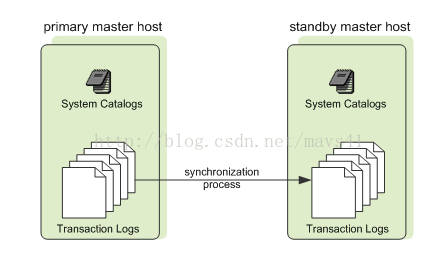
圖六
圖六說明:Standby 節點用於當 Master 節點損壞時提供 Master服務,Standby 實時與Master 節點的Catalog 和事務日誌保持同步,確保系統的變更資訊不會丟失,提升系統的健壯性。
1.6.資料冗餘-Segment 映象保護
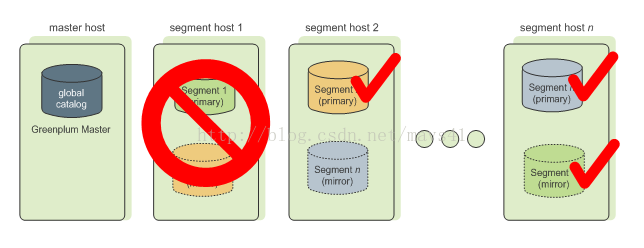
圖七
圖七說明:
1) 當GP配置了映象節點之後,主節點不可用時會自動切換到映象節點,叢集仍然保持可用狀態。當主節點恢復並啟動之後,主節點會自動恢復期間的變更;
2) 只要Master不能連線上Segment例項時,就會在系統表中將此例項標識為不可用,並用映象節點來代替,一般需要和主節點位於不同的伺服器上,當Primary Segment失敗時,Mirror Segment將自動提供服務,Primary Segment恢復正常後,使用gprecoverseg –F 同步資料
1.7.Segment 主機硬體配置示例
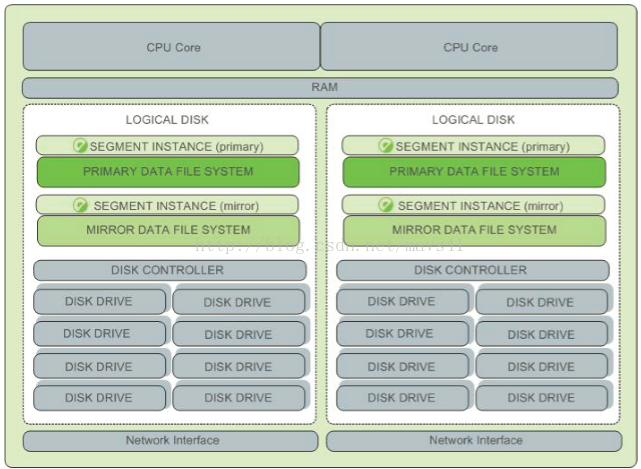
圖八
1.8.網路冗餘

圖九
圖九說明:
1) 資料之間存在冗餘,網路也存在冗餘;
2) 公共網路連線到主節點,主節點通過一臺或者多臺交換機連線到子節點。
相關推薦
Greenplum+Hadoop學習筆記-Greenplum概述及架構
0.寫在前面: 0.1. 此筆記是參考《Greenplum企業應用實戰》、《PostgreSQL8.2.3 中文文件》和《Getting Started with Greenplum for Big Data Analytics》整理; 0.2. 《Greenplum企業應
十四、Hadoop學習筆記————Zookeeper概述
一致性 es2017 zookeepe 筆記 狀態 進入 keep 應用 嚴格 順序一致性:嚴格按照順序在zookeeper上執行 原子性:所有事物請求的結果,在整個集群的應用情況一致 單一視圖:無論從哪個服務器進入集群,看到的東西都是一致的 可靠性:服務端成功響應
hadoop學習筆記-hive安裝及操作
軟體下載: Mysql: Hive: 安裝環境: OS:Oracle redhad 5.6 x86 64bit Hadoop: hadoop-0.20.2 Mysql:mysql-5.5.24 Hive:hive-0.8.1 1. 安裝mysql -
hadoop學習筆記(一)——hadoop安裝及測試
這幾天乘著工作之餘,學習了一下hadoop技術,跌跌撞撞的幾天,終於完成了一個初步的hadoop的安裝及測試,具體如下: 動力:工作中遇到的資料量太大,伺服器已經很吃力,sql語句執行老半天,故想用大
資料庫之路——greenplum資料庫學習筆記
一、常用指令: 1.取埠號:select * from gp_segment_configuration 2.select * from pg_stat_activity 該表能檢視到當前資料庫連線的IP 地址,使用者名稱,提交的查詢等。 3.select pg_si
Hadoop學習筆記(一)----環境搭建之VMware虛擬機器安裝及建立CentOS
一、vmware安裝 準備好軟體包: 點選安裝vmware 下一步 下一步 下一步 下一步 下一步 點選安裝 安裝完畢: 點選桌面上的
hadoop學習筆記-HDFS的REST接口
字段 edi -o created hadoop ftw rar hdfs lang 在學習HDFS的過程中,重點關註了HDFS的REST訪問接口。以前對REST的認識非常籠統,這次通過對HDFS的REST接口進行實際操作,形成很直觀的認識。 1? 寫文件操作 寫文件
Hadoop 學習筆記 (2) -- 關於MapReduce
規模 pre 分析 bsp 學習筆記 reduce 數據中心 階段 圖例 1. MapReduce 定義: 是一種可用於數據處理的編程的模型 優勢: MapReduce 本質上是並行運行的,因此可以將大規模的數據分析任務,分發給任何一個擁有足夠多機器
MySql 基礎學習筆記 1——概述與基本數據類型: 整型: 1)TINYINT 2)SMALLINT 3) MEDIUMINT 4)INT 5)BIGINT 主要是大小的差別 圖 浮點型:命令
where float 函數名 src ron 編碼方式 永遠 -m mas 一、CMD中經常使用mysql相關命令 mysql -D, --database=name //打開數據庫 --delimiter=name //指定分隔符 -h, --host=na
hadoop學習筆記(1)
ppi datanode ati fonts 管理系 ive 監控 system 分配 1.HDFS架構: NameNode保存元數據信息,包含文件的owner,permission。block存儲信息等。存儲在內存。 2.HDFS設計思想
AngularJs學習筆記3-服務及過濾器
聲明 運行時 維護 style 函數調用 factor blog 使用場景 需要 距離上次別博客有有一段時間了,因為最近公司和個人事情比較多,也因為學習新的知識所以耽擱了,也有人說Angularjs1.5沒有人用了,沒必要分享,我個人感覺既然開頭了我就堅持把他寫完,
Hadoop學習筆記:MapReduce框架詳解
object 好的 單點故障 提高 apr copy 普通 exce 代表性 開始聊mapreduce,mapreduce是hadoop的計算框架,我學hadoop是從hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
Linux學習筆記——bash命令及shell變量簡介
linux bash 簡介、bash 、shellbash 及其特性 shell 外殼 GUI :Gnome KDE xface CLI :shell csh ksh bash 程序,進程進程:每個進程看來,當前主機上只存在內核和當前進程 進程是程序的副本,進程是程序執行實例 用戶的工作
七、Hadoop學習筆記————調優之Hadoop參數調優
node 參數 受限 .com 資源 mage 預留空間 嘗試 nod dfs.datanode.handler.count默認為3,大集群可以調整為10 傳統MapReduce和yarn對比 如果服務器物理內存128G,則容器內存建議為100比較合理 配置總
八、Hadoop學習筆記————調優之Hive調優
需要 cnblogs log logs nbsp .cn 集中 bsp 9.png 表1表2的join和表3表4的join同時運行 此法需要關註是否有數據傾斜(大量數據集中在某一區間段) 八、Hadoop學習筆記————調優之Hive調優
Hadoop學習筆記—5.自定義類型處理手機上網日誌
clas stat 基本 手機上網 oop interrupt pil 依然 手機號碼 一、測試數據:手機上網日誌 1.1 關於這個日誌 假設我們如下一個日誌文件,這個文件的內容是來自某個電信運營商的手機上網日誌,文件的內容已經經過了優化,格式比較規整,便於學習研究。
Hadoop學習筆記—18.Sqoop框架學習
max lec sql數據庫 creat rec apt 成功 不同的 mysql數據庫 一、Sqoop基礎:連接關系型數據庫與Hadoop的橋梁 1.1 Sqoop的基本概念 Hadoop正成為企業用於大數據分析的最熱門選擇,但想將你的數據移植過去並不容易。Apa
Hadoop學習筆記系列文章導航
集群 影子 1.5 .com 日誌分析 尋找 思想 硬件 力量 一、為何要學習Hadoop? 這是一個信息爆炸的時代。經過數十年的積累,很多企業都聚集了大量的數據。這些數據也是企業的核心財富之一,怎樣從累積的數據裏尋找價值,變廢為寶煉數成金成為當務之急。但數據增長的速
Hadoop學習筆記—16.Pig框架學習
rar 開發人員 ava 大型 arr 壓縮包 上網 結構化數據 模式 一、關於Pig:別以為豬不能幹活 1.1 Pig的簡介 Pig是一個基於Hadoop的大規模數據分析平臺,它提供的SQL-LIKE語言叫Pig Latin,該語言的編譯器會把類SQL的數據分析請求
Hadoop學習筆記—15.HBase框架學習(基礎知識篇)
dfs hdfs keep 負載均衡 包含 兩個 列族 文件存儲 version HBase是Apache Hadoop的數據庫,能夠對大型數據提供隨機、實時的讀寫訪問。HBase的目標是存儲並處理大型的數據。HBase是一個開源的,分布式的,多版本的,面向列的存儲模型,它