
Tensorflow實現簡單的一元線性迴歸並儲存和載入模型
簡介:本文章以tensorflow為平臺建立了一個簡單的線性迴歸模型,並得到了不錯的效果。同時實現了模型的儲存與載入,當一個模型的訓練時間非常長的時候,利用模型的載入可以實現開啟程式時接著上次訓練。
- 平臺:Python 3.6
- IDE:Pycharm
一、線性迴歸模型介紹
簡單來說:線性迴歸就是利用一曲線段對一些連續的資料進行擬合,進而可以用這條曲線預測新的輸出值。數學模型如下:
其中:w稱為權重,b稱為偏置,利用現有的資料訓練出理想的w和b的值,然後建立模型,進行下一個值的預測。
二、資料介紹
import numpy as np
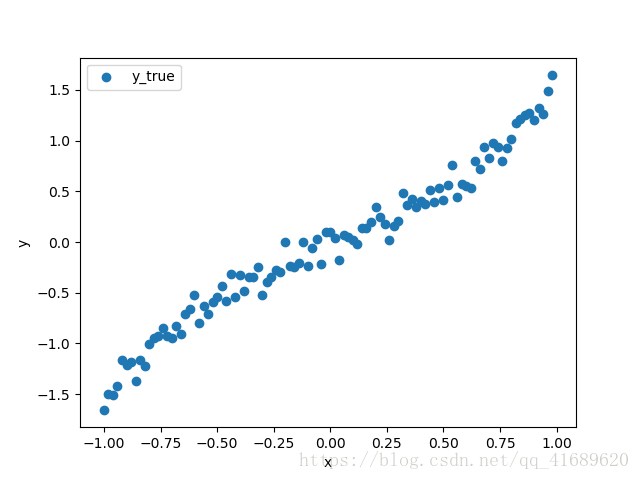
x_data = np.arange(-1, 1, 利用numpy模組產生100個數據,如下圖展示的散點圖,目的就是根據這些資料,擬合出一條最佳的曲線。
三、思路
1、載入資料
由於上圖的資料是隨機產生的,需要將資料儲存在本地,然後從本地讀取。不然每次執行程式的資料不一致。
with tf.variable_scope("data"):
# 獲取資料
x_data = np. 2、建立模型
隨機初始化權重weight和偏置bias的值,並建立迴歸模型。
with tf.variable_scope("model"):
# 初始化權重和偏置
weight = tf.Variable(tf.random_normal([1,1], mean=3.4, stddev=5.2), trainable= 3、建立損失函式
根據真實值和預測值的均方誤差值,建立損失函式。
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.square(y_true - y_predict))
4、利用梯度下降優化損失
利用tensorflow自帶的梯度下降法減小損失函式。
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
5、建立會話執行程式
with tf.Session() as sess:
sess.run(init_op)
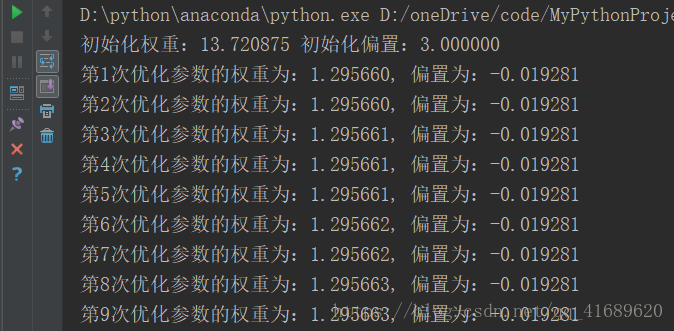
print("初始化權重:%f 初始化偏置:%f" %(weight.eval(), bias.eval()))
# 建立事件檔案
file_writer = tf.summary.FileWriter("./temp/summary/linear", graph=sess.graph)
# 判斷本地是否有儲存有模型
if os.path.exists("./temp/ckpt/checkpoint"):
saver.restore(sess, "./temp/ckpt/model")
for i in range(self.FLAGS.train_step):
sess.run(train_op)
# 執行合併的tensor
summary = sess.run(merged)
file_writer.add_summary(summary, i)
print("第%d次優化引數的權重為:%f, 偏置為:%f" % ((i + 1), weight.eval(), bias.eval()))
四、模型的儲存與載入
# 儲存模型 var_list:指定要儲存和還原的變數, max_to_keep:指定要儲存最近檢查點檔案的個數,預設為5
tf.train.Saver(var_list=None, max_to_keep=5)
# 載入模型
saver.save(var_list, file_path)
模型儲存後,會出現四個檔案
.meta:儲存了TensorFlow的graph。包括all variables,operations,collections等等。
.index和.data:儲存了所有weights,biases,gradient and all the other variables的值。
checkpoint檔案:只儲存最新檢查點檔案的記錄,即最新的儲存路徑。

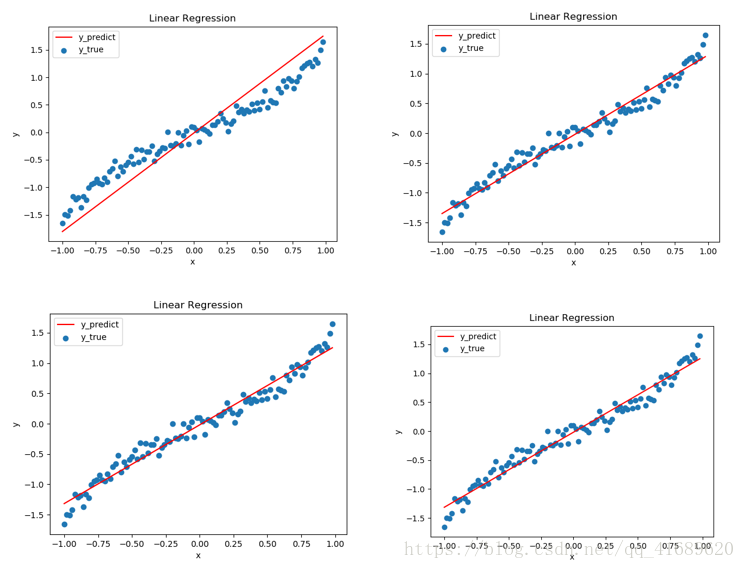
五、結果分析
每訓練400次便擬合一下曲線,圖一是訓練400次得到的曲線,圖二是訓練800次得到的曲線,圖三是1200次,圖四是1600次。從圖中可以看出,擬合的曲線效果越來越好。
六、執行程式
命令列輸入以下命令,train_step表示要訓練的步數。
得到如下結果:
七、整體程式
# -*- coding: utf-8 -*-
"""
--------------------------------------------------------
# @Version : python3.6
# @Author : [email protected]
# @Software: PyCharm
# @Time : 2018/9/21 13.14
--------------------------------------------------------
"""
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
class LinearRegression(object):
def __init__(self):
self.FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer("train_step", 100, "訓練步數")
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # 關閉警告
def run(self):
with tf.variable_scope("data"):
# 獲取資料
x_data = np.arange(-1, 1, 0.02, dtype=np.float32).reshape((100,1))
y_true = np.loadtxt("./data.csv").reshape((100,1))
with tf.variable_scope("model"):
# 初始化權重和偏置
weight = tf.Variable(tf.random_normal([1,1], mean=3.4, stddev=5.2), trainable=True, name="weight")
bias = tf.Variable(3.0, name="bias")
# 建立模型
y_predict = tf.matmul(x_data, weight) + bias
with tf.variable_scope("loss"):
# 建立損失函式
loss = tf.reduce_mean(tf.square(y_true - y_predict))
with tf.variable_scope("optimizer"):
# 利用梯度下降優化損失
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 合併tensor
merged = tf.summary.merge_all()
# 定義一個初始化變數的op
init_op = tf.global_variables_initializer()
# 定義一個儲存變數的例項
saver = tf.train.Saver()
# 建立會話執行程式
with tf.Session() as sess:
sess.run(init_op)
print("初始化權重:%f 初始化偏置:%f" %(weight.eval(), bias.eval()))
# 建立事件檔案
file_writer = tf.summary.FileWriter("./temp/summary/linear", graph=sess.graph)
# 判斷本地是否有儲存有模型
if os.path.exists("./temp/ckpt/checkpoint"):
saver.restore(sess, "./temp/ckpt/model")
for i in range(self.FLAGS.train_step):
sess.run(train_op)
# 執行合併的tensor
summary = sess.run(merged)
file_writer.add_summary(summary, i)
print("第%d次優化引數的權重為:%f, 偏置為:%f" % ((i + 1), weight.eval(), bias.eval()))
# 資料視覺化
if (i+1) % 400 == 0:
self.plot_data(y_true, weight.eval(), bias.eval(), i)
# 儲存模型
saver.save(sess, "./temp/ckpt/model")
# 資料視覺化
def plot_data(self, y_true, weight, bias, i):
x_data = np.arange(-1, 1, 0.02)
plt.scatter(x_data, y_true, label="y_true")
y_predict = x_data * weight[0][0] + bias
plt.plot(x_data, y_predict, color="red", label="y_predict")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Linear Regression")
plt.legend()
plt.savefig("./img/"+str(i+1)+".png")
plt.show()
if __name__ == '__main__':
linear_regression = LinearRegression()
linear_regression.run()
八、Tensorboard視覺化
Tensorflow一個非常受歡迎的地方就是Tensorboard的視覺化部分,該功能可以讓我們看到整個模型的執行過程。
開啟Tensorboard,命令列輸入:
tensorboard --logdir="file_path"
通過梯度下降法得到的損失函式如下,可以看出,損失函式loss逐漸減小並最終收斂在0附近。
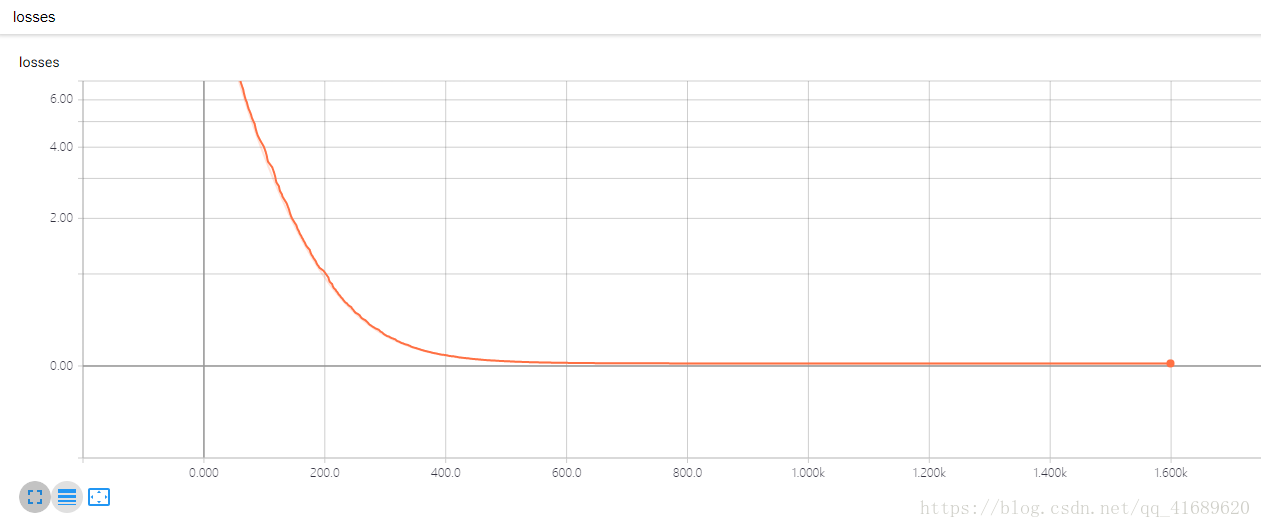
該模型可表示為:
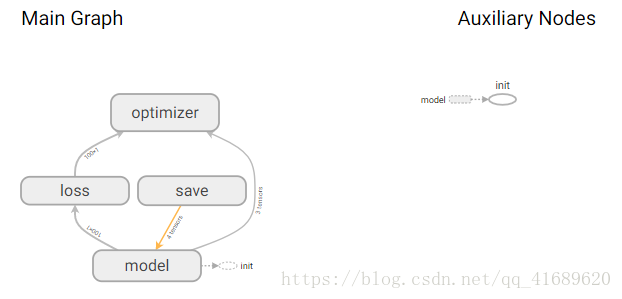
九、總結
本文通過一個簡單的一元線性迴歸模型介紹了Tensorflow的使用流程,並介紹瞭如何儲存和載入模型,同時介紹了關於Tenforboardde的簡單使用,為後續神經網路的使用奠定了基礎。
相關推薦
Tensorflow實現簡單的一元線性迴歸並儲存和載入模型
簡介:本文章以tensorflow為平臺建立了一個簡單的線性迴歸模型,並得到了不錯的效果。同時實現了模型的儲存與載入,當一個模型的訓練時間非常長的時候,利用模型的載入可以實現開啟程式時接著上次訓練。 平臺:Python 3.6 IDE:Pycharm 一、
TensorFlow——實現簡單的線性迴歸
一、線性迴歸原理 根據資料建立迴歸模型,w1x1+w2x2+…..+b = y,通過真實值與預測值之間建立誤差,使用梯度下降優化得到損失最小對應的權重和偏置。最終確定模型的權重和偏置引數。最後可以用這些引數進行預測。 二、案例:實現線性迴歸的訓練 1 .案
keras訓練淺層卷積網路並儲存和載入模型
這裡我們使用keras定義簡單的神經網路全連線層訓練MNIST資料集和cifar10資料集: keras_mnist.py from sklearn.preprocessing import LabelBinarizer from sklearn.model_select
Tensorflow學習筆記:實現簡單的線性迴歸
#線性迴歸是什麼 y = w1x1 + w2x2 + w3x3 + w4x4 + ... + w_nx_n + bias 演算法:線性迴歸 策略:均方誤差
TensorFlow構造簡單的線性迴歸模型
例項:構造線性迴歸模型 x = np.float32(np.random.normal(8, 10, [1,100]))//生成1行100列的隨機資料矩陣 y = 0.5*x + 1.2 + np.random.normal(0, 0.01)//計算對應的y值 w
Python 實現簡單的爬蟲功能並儲存到本地
昨天下班後忽然興起想寫一個爬蟲抓抓網頁上的東西。花了一個鐘簡單學習了python的基礎語法,然後參照網上的例子自己寫了個爬蟲。 #coding=utf-8 import urllib.request import re import os ''' Urllib 模組提供
基於Tensorflow實現基本的線性迴歸(Linear regression)
線性迴歸(Linear_regression) 本文基於Tensorflow實現基本的線性迴歸 1.numpy匯入資料 train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779
利用梯度下降法實現簡單的線性迴歸
最近做了好多個資料探勘的小專案,使用並比較了N多演算法,瞭解了很多機器學習的工具,如R語言、Spark機器學習庫、Python、Tensorflow和RapidMiner等等。但是我感覺到自己沒能深入下去,充其量也只是把別人的工具拿來玩玩而已。對演算法本身的優劣
tensorflow儲存和載入模型
× TF 儲存和載入模型 <!-- 作者區域 --> <div class="author"> <a class="avatar" href="/u/ff5c
深度學習框架Tensorflow學習與應用(八 儲存和載入模型,使用Google的影象識別網路inception-v3進行影象識別)
一 模型的儲存 [email protected]:~/tensorflow$ cat 8-1saver_save.py # coding: utf-8 # In[1]: import tensorflow as tf from tensorflow.examples.tutorials
tensorflow 儲存和載入模型 -2
1、 我們經常在訓練完一個模型之後希望儲存訓練的結果,這些結果指的是模型的引數,以便下次迭代的訓練或者用作測試。Tensorflow針對這一需求提供了Saver類。 Saver類提供了向checkpoints檔案儲存和從checkpoints檔案中恢復變數的相關方法。C
LISP 簡單的資料庫 3.5 儲存和載入資料庫
將*DB*中的資料資訊儲存到檔案中,以及可以從檔案中讀取資料資訊放置到*DB*全域性變數中 新增兩個函式 save-db 及 load-db ;使用全域性變數記錄資料 (defvar *db* nil) ;資料記錄格式 (defun make-cd (title arti
TensorFlow SavedModel儲存和載入模型
宣告: SavedModel 如果你想儲存或恢復模型,我們推薦使用SaveModel. SaveModel是一種與語言無關,可恢復的密封式序列化格式。TensorFlow提供了多種與SavedModel互動的機制,如tf.saved_model API、
Pytorch 儲存和載入模型 part2
搭建網路: torch.manual_seed(1) # reproducible # 假資料 x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1) y = x.p
基於pytorch的 儲存和載入模型引數
當我們花費大量的精力訓練完網路,下次預測資料時不想再(有時也不必再)訓練一次時,這時候torch.save(),torch.load()就要登場了。 儲存和載入模型引數有兩種方式: 方式一: torch.save(net.state_dict(),path): 功能
儲存和載入模型
在訓練模型過程中,由於資料集較大,模型訓練迭代次數較多等原因,使得模型訓練較耗時,因此將訓練好的模型進行儲存以便下次直接使用是很有必要,下面介紹兩種模型的儲存和載入方法 1.使用pickle模組 (1)儲存模型 with open(“模型儲存的位置
pytorch學習筆記(五):儲存和載入模型
# 儲存和載入整個模型 torch.save(model_object, 'model.pkl') model = torch.load('model.pkl') # 僅儲存和載入模型引數(推薦使
Tensorflow 實現簡單線性迴歸模型
Tensorflow是深度學習常用的一個框架,從目前官方文件看,Tensorflow支援CNN、RNN和LSTM演算法,這都是目前在Image,Speech和NLP領域最流行的深度神經網路模型。 為了熟悉和理解tensor
機器學習與Tensorflow(1)——機器學習基本概念、tensorflow實現簡單線性迴歸
一、機器學習基本概念 1.訓練集和測試集 訓練集(training set/data)/訓練樣例(training examples): 用來進行訓練,也就是產生模型或者演算法的資料集 測試集(testing set/data)/測試樣例 (testing examples):用來專門進行測試已經學習好
tensorflow實戰一---基於線性迴歸簡單實現mnist手寫體識別
Mnist手寫體識別是tensorflow的入門經典教程,此處的mnist的手寫體識別率達到了91%,優化演算法為梯度下降演算法,啟用函式為softmax迴歸,沒有中間層,基本步驟可以分為七步。 1、設定變數 2、設定資料與結果的計算關係(設定圖) 3、設定優化演算法(梯度