
Tensorflow 實現簡單線性迴歸模型
阿新 • • 發佈:2018-11-25
Tensorflow是深度學習常用的一個框架,從目前官方文件看,Tensorflow支援CNN、RNN和LSTM演算法,這都是目前在Image,Speech和NLP領域最流行的深度神經網路模型。
為了熟悉和理解tensorflow,先從簡單的例子開始,本文介紹用tensorflow搭建一個結構為[1,10,1]的神經網路實現簡單線性迴歸。
過程如下:
- 生成隨機樣本點
- 定義變數和模型
- 通過梯度下降法減小損失函式,優化模型
- 作圖
程式碼如下:
# coding=utf-8 import numpy as np import matplotlib.pyplot as plt import tensorflow as tf #用numpy生成200個樣本 x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis] #把(1,200)轉化為(200,1)方便後面的矩陣相乘運算 noise = np.random.normal(0,0.02,x_data.shape) #加入噪聲資料,資料形狀與x_data一樣 y_data = np.square(x_data) + noise #定義模型輸入輸出的佔位符 x = tf.placeholder(tf.float32,[None,1]) y = tf.placeholder(tf.float32,[None,1]) #定義神經網路隱含層 Weights_L1 = tf.Variable(tf.random_normal([1,10])) biases_L1 = tf.Variable(tf.zeros([1,10])) L1 = tf.nn.tanh(tf.matmul(x,Weights_L1) + biases_L1) #定義神經網路輸出層 Weights_L2 = tf.Variable(tf.random_normal([10,1])) biases_L2 = tf.Variable(tf.zeros([1,1])) prediction = tf.nn.tanh(tf.matmul(L1,Weights_L2) + biases_L2) #定義均方誤差作為損失函式,使用梯度下降優化器減小損失函式 loss =tf.reduce_mean(tf.square(prediction-y)) train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #訓練2000次 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #初始化變數 for _ in range(2000): sess.run(train_step,feed_dict={x:x_data,y:y_data}) #訓練完之後,作預測 prediction_value = sess.run(prediction,feed_dict={x:x_data}) #作圖 plt.figure() plt.scatter(x_data,y_data) plt.plot(x_data,prediction_value,'r-',lw=5) plt.show()
結果如下:
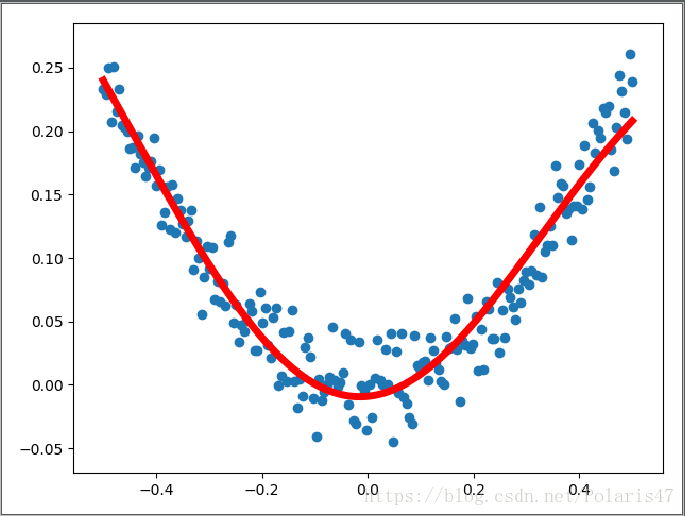
這樣,整個過程就結束了。
在後續的文章中,會介紹用tensorflow實現更復雜的模型。