
目標檢測演算法綜述:R-CNN,faster R-CNN,yolo,SSD,yoloV2
1 引言
深度學習目前已經應用到了各個領域,應用場景大體分為三類:物體識別,目標檢測,自然語言處理。上文我們對物體識別領域的技術方案,也就是CNN進行了詳細的分析,對LeNet-5 AlexNet VGG Inception ResNet MobileNet等各種優秀的模型框架有了深入理解。本文著重與分析目標檢測領域的深度學習方法,對其中的經典模型框架進行深入分析。
目標檢測可以理解為是物體識別和物體定位的綜合,不僅僅要識別出物體屬於哪個分類,更重要的是得到物體在圖片中的具體位置。
為了完成這兩個任務,目標檢測模型分為兩類。一類是two-stage,將物體識別和物體定位分為兩個步驟,分別完成,這一類的典型代表是R-CNN, fast R-CNN, faster-RCNN家族。他們識別錯誤率低,漏識別率也較低,但速度較慢,不能滿足實時檢測場景。為了解決這一問題,另一類方式出現了,稱為one-stage, 典型代表是Yolo, SSD, YoloV2等。他們識別速度很快,可以達到實時性要求,而且準確率也基本能達到faster R-CNN的水平。下面針對這幾種模型進行詳細的分析。
2 R-CNN
2014年R-CNN演算法被提出,基本奠定了two-stage方式在目標檢測領域的應用。它的演算法結構如下圖

演算法步驟如下
- 獲取輸入的原始圖片
- 使用選擇性搜尋演算法(selective search)評估相鄰影象之間的相似度,把相似度高的進行合併,並對合並後的區塊打分,選出感興趣區域的候選框,也就是子圖。這一步大約需要選出2000個子圖。
- 分別對子圖使用卷積神經網路,進行卷積-relu-池化以及全連線等步驟,提取特徵。這一步基本就是物體識別的範疇了
- 對提取的特徵進行物體分類,保留分類準確率高的區塊,以作為最終的物體定位區塊。
R-CNN較傳統的目標檢測演算法獲得了50%的效能提升,在使用VGG-16模型作為物體識別模型情況下,在voc2007資料集上可以取得66%的準確率,已經算還不錯的一個成績了。其最大的問題是速度很慢,記憶體佔用量很大,主要原因有兩個
- 候選框由傳統的selective search演算法完成,速度比較慢
- 對2000個候選框,均需要做物體識別,也就是需要做2000次卷積網路計算。這個運算量是十分巨大的。
3 Fast R-CNN
針對R-CNN的部分問題,2015年微軟提出了fast R-CNN演算法,它主要優化了兩個問題
- 提出ROI pooling池化層結構,解決了候選框子圖必須將影象裁剪縮放到相同尺寸大小的問題。由於CNN網路的輸入影象尺寸必須是固定的某一個大小(否則全連線時沒法計算),故R-CNN中對大小形狀不同的候選框,進行了裁剪和縮放,使得他們達到相同的尺寸。這個操作既浪費時間,又容易導致影象資訊丟失和形變。fast R-CNN在全連線層之前插入了ROI pooling層,從而不需要對影象進行裁剪,很好的解決了這個問題。
如下圖,剪下會導致資訊丟失,縮放會導致影象形變。

ROI pooling的思路是,如果最終我們要生成MxN的圖片,那麼先將特徵圖水平和豎直分為M和N份,然後每一份取最大值,輸出MxN的特徵圖。這樣就實現了固定尺寸的圖片輸出了。ROI pooling層位於卷積後,全連線前。
- 提出多工損失函式思想,將分類損失和邊框定位迴歸損失結合在一起統一訓練,最終輸出對應分類和邊框座標。
Fast R-CNN的結構如如下
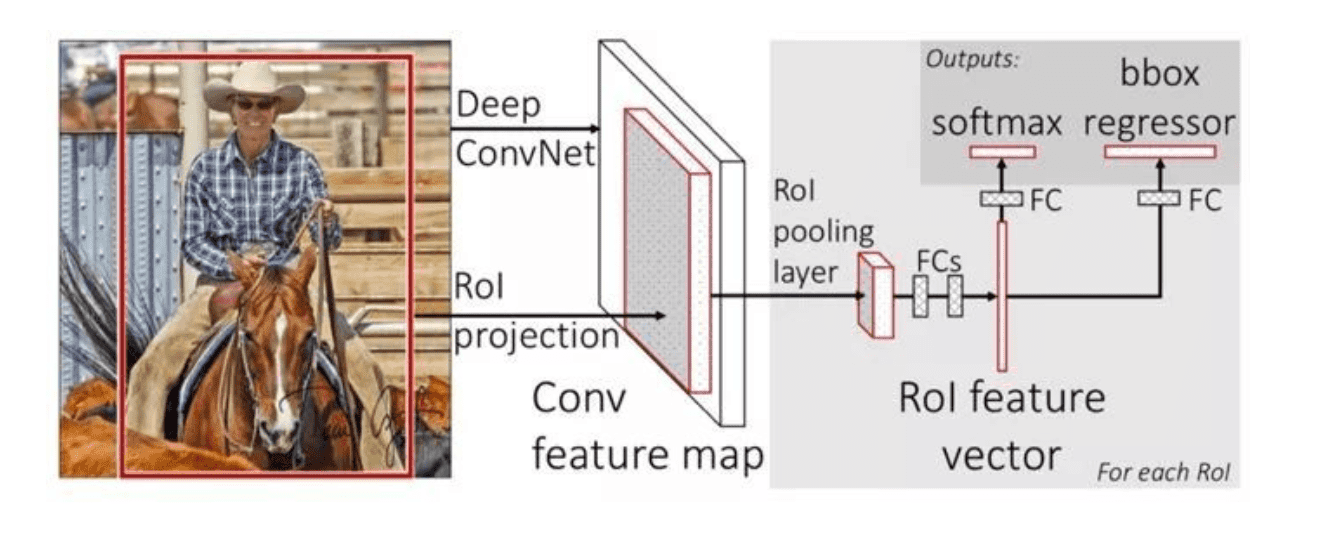
4 Faster R-CNN
R-CNN和fast R-CNN均存在一個問題,那就是由選擇性搜尋來生成候選框,這個演算法很慢。而且R-CNN中生成的2000個左右的候選框全部需要經過一次卷積神經網路,也就是需要經過2000次左右的CNN網路,這個是十分耗時的(fast R-CNN已經做了改進,只需要對整圖經過一次CNN網路)。這也是導致這兩個演算法檢測速度較慢的最主要原因。faster R-CNN 針對這個問題,提出了RPN網路來進行候選框的獲取,從而擺脫了選擇性搜尋演算法,也只需要一次卷積層操作,從而大大提高了識別速度。這個演算法十分複雜,我們會詳細分析。它的基本結構如下圖

主要分為四個步驟
- 卷積層。原始圖片先經過conv-relu-pooling的多層卷積神經網路,提取出特徵圖。供後續的RPN網路和全連線層使用。faster R-CNN不像R-CNN需要對每個子圖進行卷積層特徵提取,它只需要對全圖進行一次提取就可以了,從而大大減小了計算時間。
- RPN層,region proposal networks。RPN層用於生成候選框,並利用softmax判斷候選框是前景還是背景,從中選取前景候選框(因為物體一般在前景中),並利用bounding box regression調整候選框的位置,從而得到特徵子圖,稱為proposals。
- ROI層,fast R-CNN中已經講過了ROI層了,它將大小尺寸不同的proposal池化成相同的大小,然後送入後續的全連線層進行物體分類和位置調整迴歸
- 分類層。利用ROI層輸出的特徵圖proposal,判斷proposal的類別,同時再次對bounding box進行regression從而得到精確的形狀和位置。
使用VGG-16卷積模型的網路結構如下圖

4.1 卷積層
卷積層採用的VGG-16模型,先將PxQ的原始圖片,縮放裁剪為MxN的圖片,然後經過13個conv-relu層,其中會穿插4個max-pooling層。所有的卷積的kernel都是3x3的,padding為1,stride為1。pooling層kernel為2x2, padding為0,stride為2。
MxN的圖片,經過卷積層後,變為了(M/16) x (N/16)的feature map了。
4.2 RPN層
faster R-CNN拋棄了R-CNN中的選擇性搜尋(selective search)方法,使用RPN層來生成候選框,能極大的提升候選框的生成速度。RPN層先經過3x3的卷積運算,然後分為兩路。一路用來判斷候選框是前景還是背景,它先reshape成一維向量,然後softmax來判斷是前景還是背景,然後reshape恢復為二維feature map。另一路用來確定候選框的位置,通過bounding box regression實現,後面再詳細講。兩路計算結束後,挑選出前景候選框(因為物體在前景中),並利用計算得到的候選框位置,得到我們感興趣的特徵子圖proposal。
4.2.1 候選框的生成 anchors
卷積層提取原始影象資訊,得到了256個feature map,經過RPN層的3x3卷積後,仍然為256個feature map。但是每個點融合了周圍3x3的空間資訊。對每個feature map上的一個點,生成k個anchor(k預設為9)。anchor分為前景和背景兩類(我們先不去管它具體是飛機還是汽車,只用區分它是前景還是背景即可)。anchor有[x,y,w,h]四個座標偏移量,x,y表示中心點座標,w和h表示寬度和高度。這樣,對於feature map上的每個點,就得到了k個大小形狀各不相同的選區region。
4.2.2 softmax判斷選區是前景還是背景
對於生成的anchors,我們首先要判斷它是前景還是背景。由於感興趣的物體位於前景中,故經過這一步之後,我們就可以捨棄背景anchors了。大部分的anchors都是屬於背景,故這一步可以篩選掉很多無用的anchor,從而減少全連線層的計算量。
對於經過了3x3的卷積後得到的256個feature map,先經過1x1的卷積,變換為18個feature map。然後reshape為一維向量,經過softmax判斷是前景還是背景。此處reshape的唯一作用就是讓資料可以進行softmax計算。然後輸出識別得到的前景anchors。
4.2.3 確定候選框位置
另一路用來確定候選框的位置,也就是anchors的[x,y,w,h]座標值。如下圖所示,紅色代表我們當前的選區,綠色代表真實的選區。雖然我們當前的選取能夠大概框選出飛機,但離綠色的真實位置和形狀還是有很大差別,故需要對生成的anchors進行調整。這個過程我們稱為bounding box regression。

假設紅色框的座標為[x,y,w,h], 綠色框,也就是目標框的座標為[Gx, Gy,Gw,Gh], 我們要建立一個變換,使得[x,y,w,h]能夠變為[Gx, Gy,Gw,Gh]。最簡單的思路是,先做平移,使得中心點接近,然後進行縮放,使得w和h接近。如下

我們要學習的就是dx dy dw dh這四個變換。由於是線性變換,我們可以用線性迴歸來建模。設定loss和優化方法後,就可以利用深度學習進行訓練,並得到模型了。對於空間位置loss,我們一般採用均方差演算法,而不是交叉熵(交叉熵使用在分類預測中)。優化方法可以採用自適應梯度下降演算法Adam。
4.2.4 輸出特徵子圖proposal
得到了前景anchors,並確定了他們的位置和形狀後,我們就可以輸出前景的特徵子圖proposal了。步驟如下
- 得到前景anchors和他們的[x y w h]座標
- 按照anchors為前景的不同概率,從大到小排序,選取前pre_nms_topN個anchors,比如前6000個
- 剔除非常小的anchors
- 通過NMS非極大值抑制,從anchors中找出置信度較高的。這個主要是為了解決選取交疊問題。首先計算每一個選區面積,然後根據他們在softmax中的score(也就是是否為前景的概率)進行排序,將score最大的選區放入佇列中。接下來,計算其餘選區與當前最大score選區的IOU(IOU為兩box交集面積除以兩box並集面積,它衡量了兩個box之間重疊程度)。去除IOU大於設定閾值的選區。這樣就解決了選區重疊問題
- 選取前post_nms_topN個結果作為最終選區proposal進行輸出,比如300個。
經過這一步之後,物體定位應該就基本結束了,剩下的就是物體識別了
4.3 ROI Pooling層
和fast R-CNN中類似,這一層主要解決之前得到的proposal大小形狀各不相同,導致沒法做全連線。全連線計算只能對確定的shape進行運算,故必須使proposal大小形狀變為相同。通過裁剪和縮放的手段,可以解決這個問題,但會帶來資訊丟失和圖片形變問題。我們使用ROI pooling可以有效的解決這個問題。
ROI pooling中,如果目標輸出為MxN,則在水平和豎直方向上,將輸入proposal劃分為MxN份,每一份取最大值,從而得到MxN的輸出特徵圖。
4.4 分類層
ROI Pooling層後的特徵圖,通過全連線層與softmax,就可以計算屬於哪個具體類別,比如人,狗,飛機,並可以得到cls_prob概率向量。同時再次利用bounding box regression精細調整proposal位置,得到bbox_pred,用於迴歸更加精確的目標檢測框。
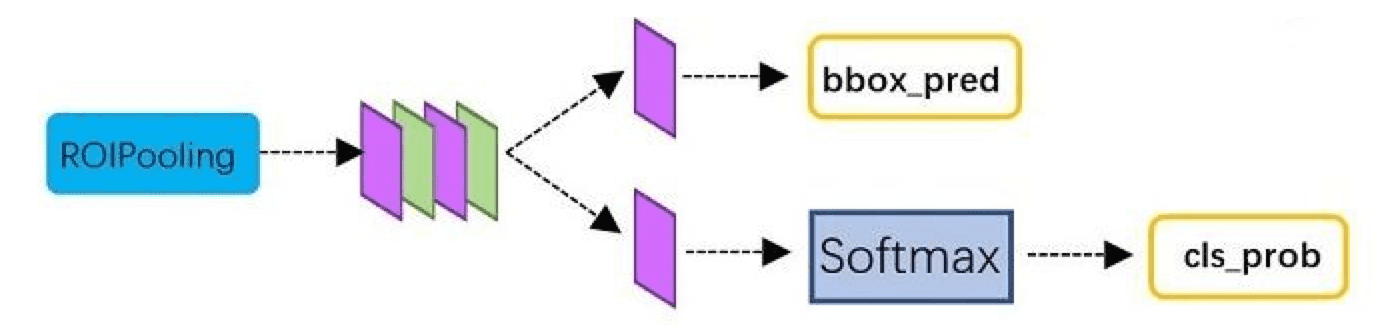
這樣就完成了faster R-CNN的整個過程了。演算法還是相當複雜的,對於每個細節需要反覆理解。faster R-CNN使用resNet101模型作為卷積層,在voc2012資料集上可以達到83.8%的準確率,超過yolo ssd和yoloV2。其最大的問題是速度偏慢,每秒只能處理5幀,達不到實時性要求。
5 Yolo:you only look once
針對於two-stage目標檢測演算法普遍存在的運算速度慢的缺點,yolo創造性的提出了one-stage。也就是將物體分類和物體定位在一個步驟中完成。yolo直接在輸出層迴歸bounding box的位置和bounding box所屬類別,從而實現one-stage。通過這種方式,yolo可實現45幀每秒的運算速度,完全能滿足實時性要求(達到24幀每秒,人眼就認為是連續的)。它的網路結構如下圖

主要分為三個部分:卷積層,目標檢測層,NMS篩選層
5.1 卷積層
採用Google inceptionV1網路,對應到上圖中的第一個階段,共20層。這一層主要是進行特徵提取,從而提高模型泛化能力。但作者對inceptionV1進行了改造,他沒有使用inception module結構,而是用一個1x1的卷積,並聯一個3x3的卷積來替代。(可以認為只使用了inception module中的一個分支,應該是為了簡化網路結構)
5.2 目標檢測層
先經過4個卷積層和2個全連線層,最後生成7x7x30的輸出。先經過4個卷積層的目的是為了提高模型泛化能力。yolo將一副448x448的原圖分割成了7x7個網格,每個網格要預測兩個bounding box的座標(x,y,w,h)和box內包含物體的置信度confidence,以及物體屬於20類別中每一類的概率(yolo的訓練資料為voc2012,它是一個20分類的資料集)。所以一個網格對應的引數為(4x2+2+20) = 30。如下圖

- bounding box座標: 如上圖,7x7網格內的每個grid(紅色框),對應兩個大小形狀不同的bounding box(黃色框)。每個box的位置座標為(x,y,w,h), x和y表示box中心點座標,w和h表示box寬度和高度。通過與訓練資料集上標定的物體真實座標(Gx,Gy,Gw,Gh)進行對比訓練,可以計算出初始bounding box平移和伸縮得到最終位置的模型。
- bounding box置信度confidence:這個置信度只是為了表達box內有無物體的概率,並不表達box內物體是什麼。
confidence=
其中前一項表示有無人工標記的物體落入了網格內,如果有則為1,否則為0。第二項代表bounding box和真實標記的box之間的重合度。它等於兩個box面積交集,除以面積並集。值越大則box越接近真實位置。
- 分類資訊:yolo的目標訓練集為voc2012,它是一個20分類的目標檢測資料集。常用目標檢測資料集如下表
| Name | # Images (trainval) | # Classes | Last updated |
| --------------- | ------------------- | --------- | ------------ |
| ImageNet | 450k | 200 | 2015 |
| COCO | 120K | 90 | 2014 |
| Pascal VOC | 12k | 20 | 2012 |
| Oxford-IIIT Pet | 7K | 37 | 2012 |
| KITTI Vision | 7K | 3 | |
每個網格還需要預測它屬於20分類中每一個類別的概率。分類資訊是針對每個網格的,而不是bounding box。故只需要20個,而不是40個。而confidence則是針對bounding box的,它只表示box內是否有物體,而不需要預測物體是20分類中的哪一個,故只需要2個引數。雖然分類資訊和confidence都是概率,但表達含義完全不同。
5.3 NMS篩選層
篩選層是為了在多個結果中(多個bounding box)篩選出最合適的幾個,這個方法和faster R-CNN 中基本相同。都是先過濾掉score低於閾值的box,對剩下的box進行NMS非極大值抑制,去除掉重疊度比較高的box(NMS具體演算法可以回顧上面faster R-CNN小節)。這樣就得到了最終的最合適的幾個box和他們的類別。
5.4 yolo損失函式
yolo的損失函式包含三部分,位置誤差,confidence誤差,分類誤差。具體公式如下

誤差均採用了均方差演算法,其實我認為,位置誤差應該採用均方差演算法,而分類誤差應該採用交叉熵。由於物體位置只有4個引數,而類別有20個引數,他們的累加和不同。如果賦予相同的權重,顯然不合理。故yolo中位置誤差權重為5,類別誤差權重為1。由於我們不是特別關心不包含物體的bounding box,故賦予不包含物體的box的置信度confidence誤差的權重為0.5,包含物體的權重則為1。
yolo演算法開創了one-stage檢測的先河,它將物體分類和物體檢測網絡合二為一,都在全連線層完成。故它大大降低了目標檢測的耗時,提高了實時性。但它的缺點也十分明顯
- 每個網格只對應兩個bounding box,當物體的長寬比不常見(也就是訓練資料集覆蓋不到時),效果很差。
- 原始圖片只劃分為7x7的網格,當兩個物體靠的很近時,效果很差
- 最終每個網格只對應一個類別,容易出現漏檢(物體沒有被識別到)。
- 對於圖片中比較小的物體,效果很差。這其實是所有目標檢測演算法的通病,SSD對它有些優化,我們後面再看。
6 SSD: Single Shot MultiBox Detector
Faster R-CNN準確率mAP較高,漏檢率recall較低,但速度較慢。而yolo則相反,速度快,但準確率和漏檢率不盡人意。SSD綜合了他們的優缺點,對輸入300x300的影象,在voc2007資料集上test,能夠達到58 幀每秒( Titan X 的 GPU ),72.1%的mAP。
SSD網路結構如下圖

和yolo一樣,也分為三部分:卷積層,目標檢測層和NMS篩選層
6.1 卷積層
SSD論文采用了VGG16的基礎網路,其實這也是幾乎所有目標檢測神經網路的慣用方法。先用一個CNN網路來提取特徵,然後再進行後續的目標定位和目標分類識別。
6.2 目標檢測層
這一層由5個卷積層和一個平均池化層組成。去掉了最後的全連線層。SSD認為目標檢測中的物體,只與周圍資訊相關,它的感受野不是全域性的,故沒必要也不應該做全連線。SSD的特點如下
6.2.1 多尺寸feature map上進行目標檢測
每一個卷積層,都會輸出不同大小感受野的feature map。在這些不同尺度的feature map上,進行目標位置和類別的訓練和預測,從而達到多尺度檢測的目的,可以克服yolo對於寬高比不常見的物體,識別準確率較低的問題。而yolo中,只在最後一個卷積層上做目標位置和類別的訓練和預測。這是SSD相對於yolo能提高準確率的一個關鍵所在。
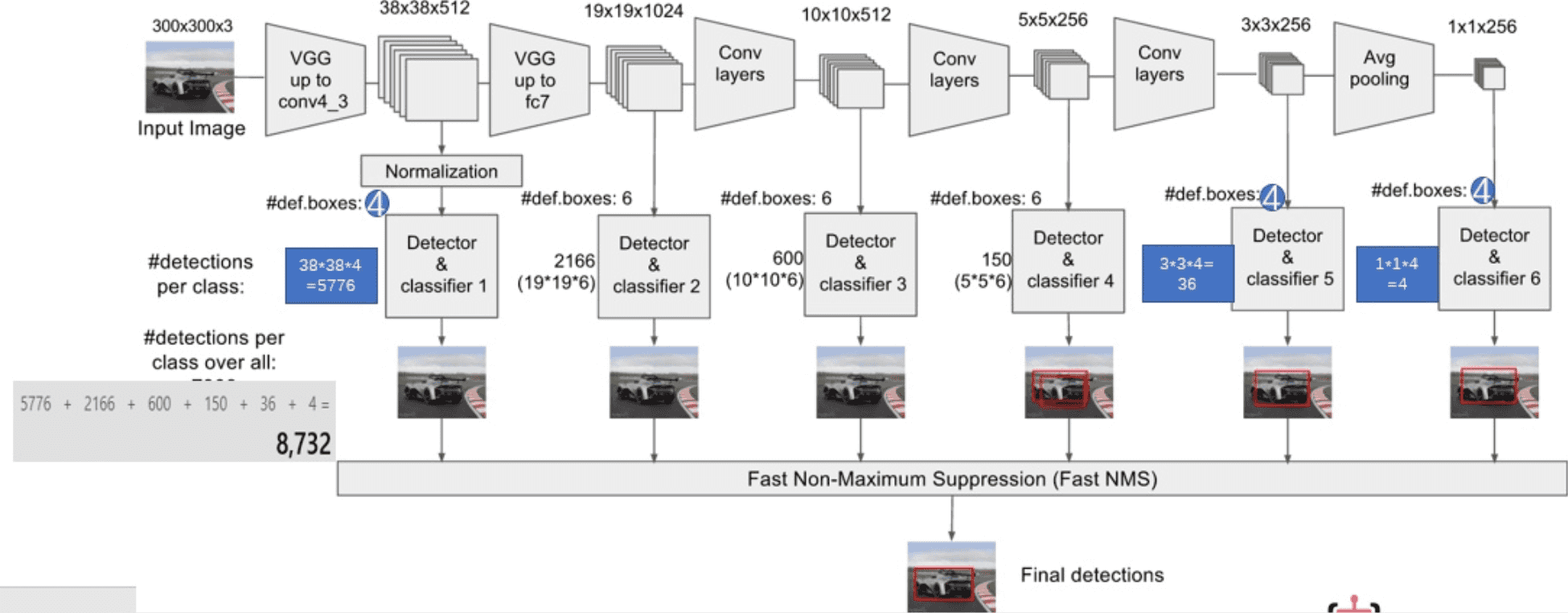
如上所示,在每個卷積層上都會進行目標檢測和分類,最後由NMS進行篩選,輸出最終的結果。多尺度feature map上做目標檢測,就相當於多了很多寬高比例的bounding box,可以大大提高泛化能力。
6.2.2 多個anchors,每個anchor對應4個位置引數和21個類別引數
和faster R-CNN相似,SSD也提出了anchor的概念。卷積輸出的feature map,每個點對應為原圖的一個區域的中心點。以這個點為中心,構造出6個寬高比例不同,大小不同的anchor(SSD中稱為default box)。每個anchor對應4個位置引數(x,y,w,h)和21個類別概率(voc訓練集為20分類問題,在加上anchor是否為背景,共21分類)。如下圖所示

另外,在訓練階段,SSD將正負樣本比例定位1:3。訓練集給定了輸入影象以及每個物體的真實區域(ground true box),將default box和真實box最接近的選為正樣本。然後在剩下的default box中選擇任意一個與真實box IOU大於0.5的,作為正樣本。而其他的則作為負樣本。由於絕大部分的box為負樣本,會導致正負失衡,故根據每個box類別概率排序,使正負比例保持在1:3。SSD認為這個策略提高了4%的準確率
另外,SSD採用了資料增強。生成與目標物體真實box間IOU為0.1 0.3 0.5 0.7 0.9的patch,隨機選取這些patch參與訓練,並對他們進行隨機水平翻轉等操作。SSD認為這個策略提高了8.8%的準確率。
6.3 篩選層
和yolo的篩選層基本一致,同樣先過濾掉類別概率低於閾值的default box,再採用NMS非極大值抑制,篩掉重疊度較高的。只不過SSD綜合了各個不同feature map上的目標檢測輸出的default box。
SSD基本已經可以滿足我們手機端上實時物體檢測需求了,TensorFlow在Android上的目標檢測官方模型ssd_mobilenet_v1_android_export.pb,就是通過SSD演算法實現的。它的基礎卷積網路採用的是mobileNet,適合在終端上部署和執行。
7 YoloV2, Yolo9000和其他模型
針對yolo準確率不高,容易漏檢,對長寬比不常見物體效果差等問題,結合SSD的特點,提出了yoloV2。它主要還是採用了yolo的網路結構,在其基礎上做了一些優化和改進,如下
- 網路採用DarkNet-19:19層,裡面包含了大量3x3卷積,同時借鑑inceptionV1,加入1x1卷積核全域性平均池化層。結構如下

- 去掉全連線層:和SSD一樣,模型中只包含卷積和平均池化層(平均池化是為了變為一維向量,做softmax分類)。這樣做一方面是由於物體檢測中的目標,只是圖片中的一個區塊,它是區域性感受野,沒必要做全連線。而是為了輸入不同尺寸的圖片,如果採用全連線,則只能輸入固定大小圖片了。
- batch normalization:卷積層後加入BN,對下一次卷積輸入的資料做歸一化。可以在增大學習率的前提下,同樣可以穩定落入區域性最優解。從而加速訓練收斂,在相同耗時下,增大了有效迭代次數。
- 使用anchors:借鑑faster R-CNN和SSD,對於一箇中心點,使用多個anchor,得到多個bounding box,每個bounding box包含4個位置座標引數(x y w h)和21個類別概率資訊。而在yolo中,每個grid(對應anchor),僅預測一次類別,而且只有兩個bounding box來進行座標預測。
- pass through layer:yolo原本最終特徵圖為13x13x256。yoloV2還利用了之前的26x26的特徵圖進行目標檢測。26x26x256的feature map分別按行和列隔點取樣,得到4幅13x13x256的feature map,將他們組織成一幅13x13x2048的feature map。這樣做的目的是提高小物體的識別率。因為越靠前的卷積,其感受野越小,越有利於小物體的識別。
- 高解析度輸入Training:yolo採用224x224圖片進行預訓練,而yoloV2則採用448x448
- Multi-Scale Training:輸入不同尺寸的圖片,迭代10次,就改變輸入圖片尺寸。由於模型中去掉了全連線層,故可以輸入不同尺寸的圖片了。從320x320,到608x608
yolo和yoloV2只能識別20類物體,為了優化這個問題,提出了yolo9000,可以識別9000類物體。它在yoloV2基礎上,進行了imageNet和coco的聯合訓練。這種方式充分利用imageNet可以識別1000類物體和coco可以進行目標位置檢測的優點。當使用imageNet訓練時,只更新物體分類相關的引數。而使用coco時,則更新全部所有引數。
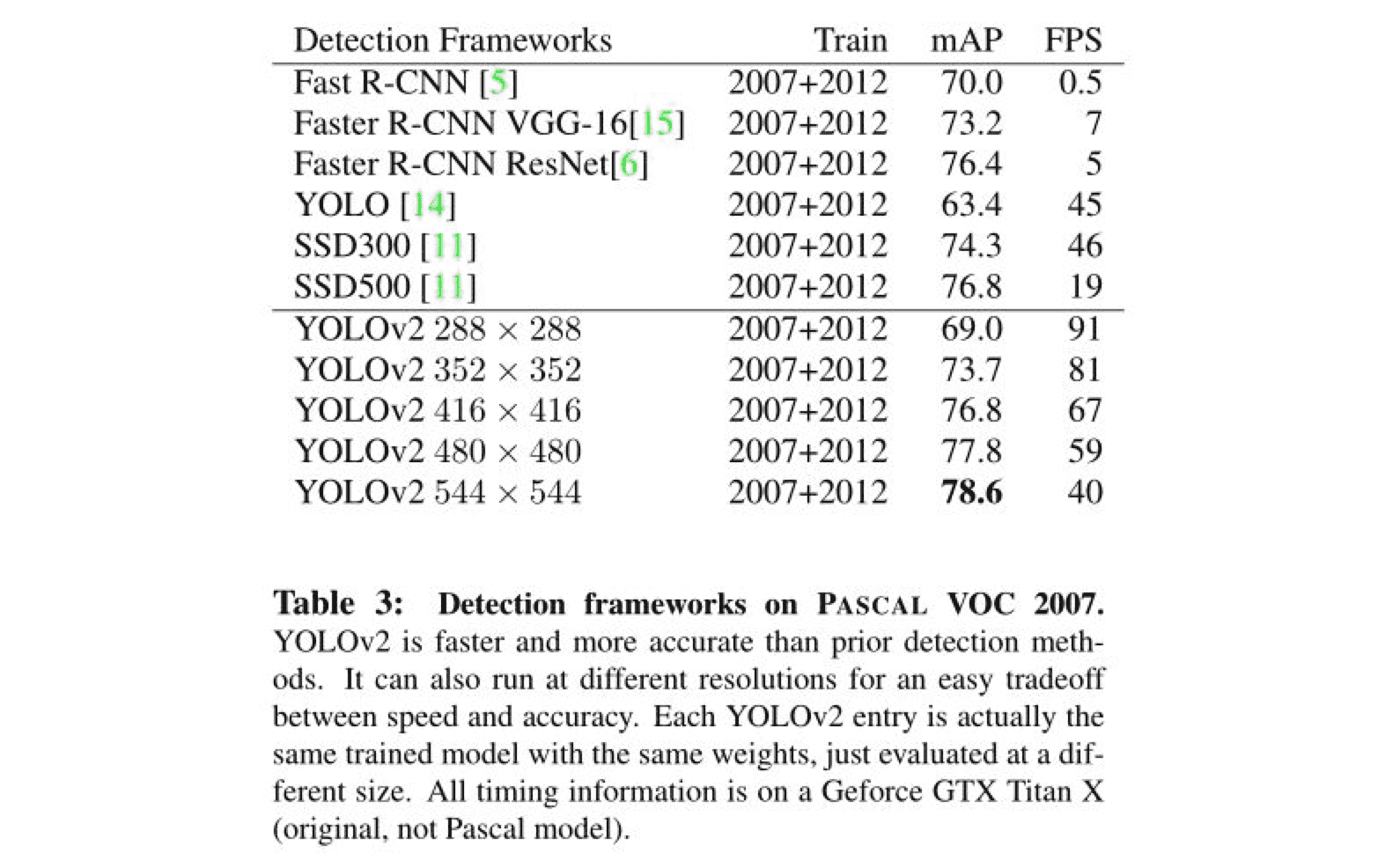
當前目標檢測模型演算法也是層出不窮。在two-stage領域,2017年Facebook提出了mask R-CNN。CMU也提出了A-Fast-RCNN 演算法,將對抗學習引入到目標檢測領域。Face++也提出了Light-Head R-CNN,主要探討了 R-CNN 如何在物體檢測中平衡精確度和速度。
one-stage領域也是百花齊放,2017年首爾大學提出 R-SSD 演算法,主要解決小尺寸物體檢測效果差的問題。清華大學提出了 RON 演算法,結合 two stage 名的方法和 one stage 方法的優勢,更加關注多尺度物件定位和負空間樣本挖掘問題。
8 總結
目標檢測領域的深度學習演算法,需要進行目標定位和物體識別,演算法相對來說還是很複雜的。當前各種新演算法也是層不出窮,但模型之間有很強的延續性,大部分模型演算法都是借鑑了前人的思想,站在巨人的肩膀上。我們需要知道經典模型的特點,這些tricks是為了解決什麼問題,以及為什麼解決了這些問題。這樣才能舉一反三,萬變不離其宗。綜合下來,目標檢測領域主要的難點如下
- 檢測速度:實時性要求高,故網路結構不能太複雜,引數不能太多,卷積層次也不能太多。
- 位置準確率:(x y w h)引數必須準確,也就是檢測框大小尺寸要匹配,且重合度IOU要高。SSD和faster RCNN通過多個bounding box來優化這個問題
- 漏檢率:必須儘量檢測出所有目標物體,特別是靠的近的物體和尺寸小的物體。SSD和faster RCNN通過多個bounding box來優化這個問題
- 物體寬高比例不常見:SSD通過不同尺寸feature map,yoloV2通過不同尺寸輸入圖片,來優化這個問題。
- 靠的近的物體準確率低
- 小尺寸物體準確率低:SSD取消全連線層,yoloV2增加pass through layer,採用高解析度輸入圖片,來優化這個問題。
相關推薦
目標檢測演算法綜述:R-CNN,faster R-CNN,yolo,SSD,yoloV2
1 引言 深度學習目前已經應用到了各個領域,應用場景大體分為三類:物體識別,目標檢測,自然語言處理。上文我們對物體識別領域的技術方案,也就是CNN進行了詳細的分析,對LeNet-5 AlexNet VGG Inception ResNet MobileNet等各種優秀的模型
基於深度學習的目標檢測演算法綜述:演算法改進
想了解深度學習的小夥伴們,看一下! 以後自己學深度學習了,再來看此貼! 只能發一個連結了: https://mp.weixin.qq.com/s?__biz=MzU4Nzc0NDI1NA==&mid=2247483731&idx=1&sn=37667093807751
基於深度學習的目標檢測演算法綜述:常見問題及解決方案
導讀:目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標檢測演算法也從基於手工特徵的傳統演算法轉向了基於深度神經網路的檢測技術。從最初 2013 年提出的 R-CNN
目標檢測演算法理解:從R-CNN到Mask R-CNN
因為工作了以後時間比較瑣碎,所以更多的時候使用onenote記錄知識點,但是對於一些演算法層面的東西,個人的理解畢竟是有侷限的。我一直做的都是影象分類方向,最近開始接觸了目標檢測,也看了一些大牛的論文,雖然網上已經有很多相關的演算法講解,但是每個人對同一個問題的理解都不太一樣,本文主
基於深度學習的目標檢測演算法綜述(二)—Two/One stage演算法改進之R-FCN
基於深度學習的目標檢測演算法綜述(一):https://blog.csdn.net/weixin_36835368/article/details/82687919 目錄 1、Two stage 1.1 R-FCN:Object Detection via Region-based
基於深度學習的目標檢測演算法綜述(一)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40047760 目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標檢測演算法也從基於手工特徵的傳統演算法轉向了基於深度神經網路的檢測技
基於深度學習的目標檢測演算法綜述(三)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40102001 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經
基於深度學習的目標檢測演算法綜述(二)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40020809 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經
基於深度學習的目標檢測演算法綜述(一)
前言 目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標檢測演算法也從基於手工特徵的傳統演算法轉向了基於深度神經網路的檢測技術。從最初2013年提出的R-CNN、OverFeat
基於深度學習的目標檢測演算法綜述(二)
前言 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經典論文的升級版本。 2. 解決方案。這部分論文對物體檢
目標檢測演算法圖解:一文看懂RCNN系列演算法
在生活中,經常會遇到這樣的一種情況,上班要出門的時候,突然找不到一件東西了,比如鑰匙、手機或者手錶等。這個時候一般在房間翻一遍各個角落來尋找不見的物品,最後突然一拍大腦,想到在某一個地方,在整個過程中有時候是很著急的,並且越著急越找不到,真是令人沮喪。但是,如果一個簡單的計算機演算法可以在幾毫秒
基於深度學習的目標檢測演算法綜述(三)
轉自:https://zhuanlan.zhihu.com/p/40102001 基於深度學習的目標檢測演算法綜述(一) 基於深度學習的目標檢測演算法綜述(二) 基於深度學習的目標檢測演算法綜述(三) 本文內容原創,作者:美圖雲視覺技術部 檢測團隊,轉載請註明出處
深度學習目標檢測(object detection)系列(四) Faster R-CNN
Faster R-CNN簡介 RBG團隊在2015年,與Fast R-CNN同年推出了Faster R-CNN,我們先從頭回顧下Object Detection任務中各個網路的發展,首先R-CNN用分類+bounding box解決了目標檢測問題,SP
基於深度學習的目標檢測演算法綜述
導言 目標檢測的任務是找出影象中所有感興趣的目標(物體),確定它們的位置和大小,是機器視覺領域的核 心問題之一。由於各類物體有不同的外觀,形狀,姿態,加上成像時光照,遮擋等因素的干擾,目標檢測 一直是機器視覺領域最具有挑戰性的問題。本文將針對目標檢測(Object Detec
乾貨 | 基於深度學習的目標檢測演算法綜述
Original url: 精品文章,第一時間送達 來源:美圖雲視覺技術部 轉自:美團技術,未經允許不得二次轉載 目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標
深度學習筆記(三)--目標檢測演算法綜述
目前目標檢測領域的深度學習方法主要分為兩類:two stage的目標檢測演算法;one stage的目標檢測演算法。前者是先由演算法生成一系列作為樣本的候選框,再通過卷積神經網路進行樣本分類;後者則不用產生候選框,直接將目標邊框定位的問題轉化為迴歸問題處理。正是由於兩種方法的
計算機視覺目標檢測演算法綜述
傳統目標檢測三步走:區域選擇、特徵提取、分類迴歸 遇到的問題: 1.區域選擇的策略效果差、時間複雜度高 2.手工提取的特徵魯棒性較差 深度學習時代目標檢測演算法的發展: Two-Stage: R-CNN 地位:是用卷積神經網路(CNN)做目標檢測的第一篇,意
深度學習中目標檢測演算法 RCNN、Fast RCNN、Faster RCNN 的基本思想
前言 影象分類,檢測及分割是計算機視覺領域的三大任務。即影象理解的三個層次: 分類(Classification),即是將影象結構化為某一類別的資訊,用事先確定好的類別(string)或例項ID來描述圖片。這一任務是最簡單、最基礎的影象理解任務,也是深度學習模型最先取得突
論文筆記:目標檢測演算法(R-CNN,Fast R-CNN,Faster R-CNN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的視覺任務大多數考慮使用SIFT和HOG特徵,而近年來CNN和ImageNet的出現使得影象分類問題取得重大突破,那麼這方面的成功能否遷移到PASCAL VOC的目標檢測任務上呢?基於這個問題,論文提出了R-CNN。 基本步驟:如下圖
Domain Adaptive Faster R-CNN:經典域自適應目標檢測演算法,解決現實中痛點,程式碼開源 | CVPR2018
> 論文從理論的角度出發,對目標檢測的域自適應問題進行了深入的研究,基於H-divergence的對抗訓練提出了DA Faster R-CNN,從圖片級和例項級兩種角度進行域對齊,並且加入一致性正則化來學習域不變的RPN。從實驗來看,論文的方法十分有效,這是一個很符合實際需求的研究,能解決現實中場景多樣