
計算機視覺目標檢測演算法綜述
傳統目標檢測三步走:區域選擇、特徵提取、分類迴歸
遇到的問題:
1.區域選擇的策略效果差、時間複雜度高
2.手工提取的特徵魯棒性較差
深度學習時代目標檢測演算法的發展:
Two-Stage:
R-CNN
地位:是用卷積神經網路(CNN)做目標檢測的第一篇,意義影響深遠。
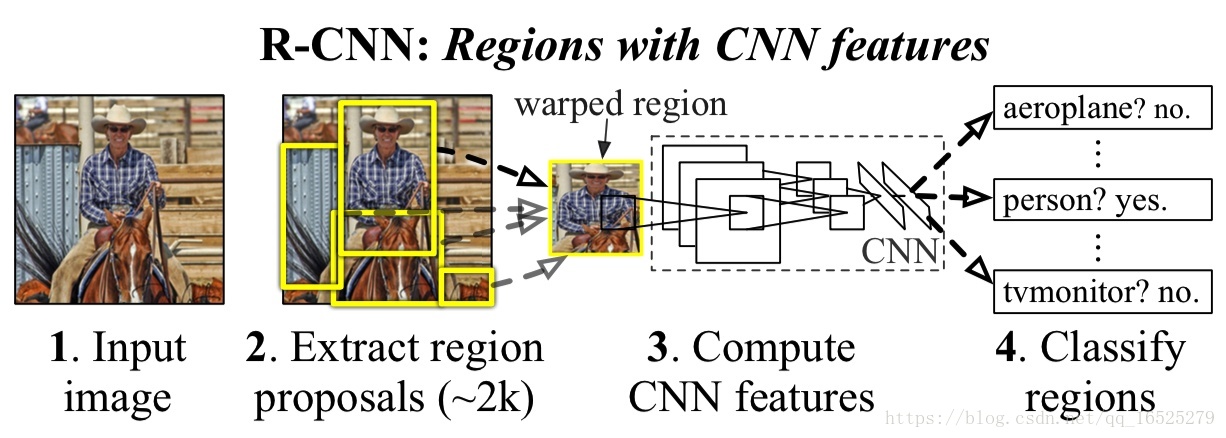
核心思想:
1.區域選擇不再使用滑窗,而是採用啟發式候選區域生成演算法(Selective Search)
2.特徵提取也從手工變成利用CNN自動提取特徵,增強了魯棒性。
流程步驟:
1.使用Selective Search演算法從待檢測影象中提取2000個左右的區域候選框
2.把所有侯選框縮放成固定大小(原文采用227×227)
3.使用CNN(有5個卷積層和2個全連線層)提取候選區域影象的特徵,得到固定長度的特徵向量
4.將特徵向量輸入到SVM分類器,判別輸入類別;送入到全連線網路以迴歸的方式精修候選框
優點:
1.速度
傳統的區域選擇使用滑窗,每滑一個視窗檢測一次,相鄰視窗資訊重疊高,檢測速度慢。R-CNN 使用一個啟發式方法(Selective Search),先生成候選區域再檢測,降低資訊冗餘程度,從而提高檢測速度。
2.特徵提取
傳統的手工提取特徵魯棒性差,限於如顏色、紋理等低層次(Low level)的特徵。
不足:
1.算力冗餘
先生成候選區域,再對區域進行卷積,這裡有兩個問題:其一是候選區域會有一定程度的重疊,對相同區域進行重複卷積;其二是每個區域進行新的卷積需要新的儲存空間。
2.圖片縮放
候選區域中的影象輸入CNN(卷積層並不要求輸入影象的尺寸固定,只有第一個全連線層需要確定輸入維度,因為它和前一層之間的權重矩陣是固定大小的,其他的全連線層也不要求影象的尺寸固定)中需要固定尺寸(227 * 227),會造成物體形變,導致檢測效能下降。
3.訓練測試不簡潔
候選區域生成、特徵提取、分類、迴歸都是分開操作,中間資料還需要單獨儲存。
SPP Net
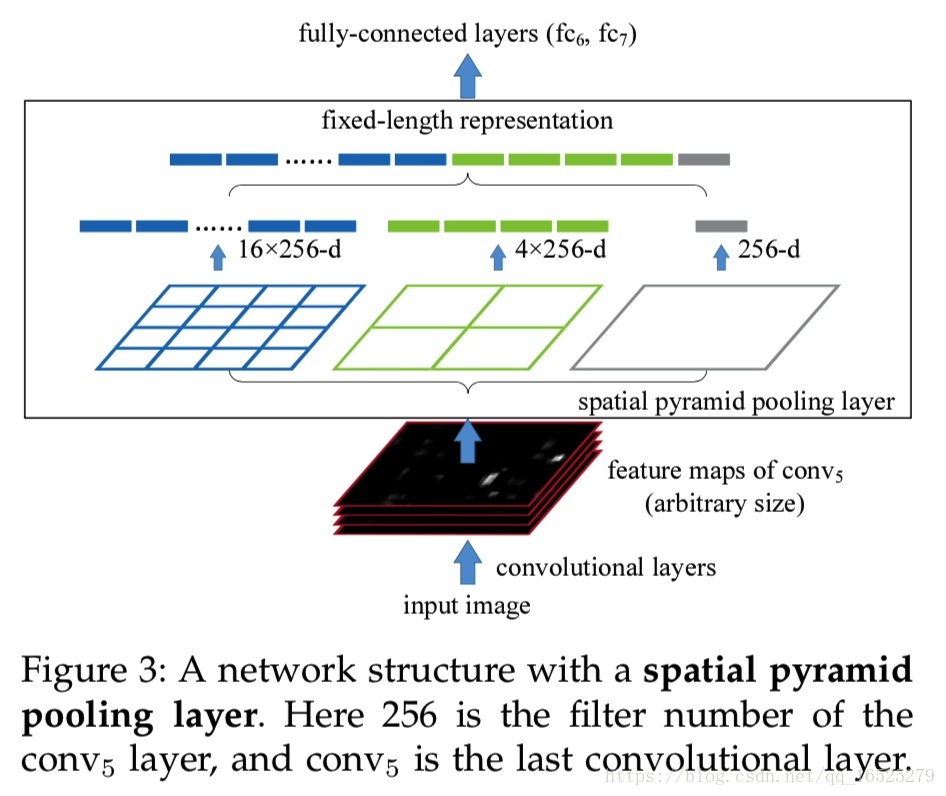
優點:
1.將提取候選框特徵向量的操作轉移到卷積後的特徵圖上進行,將R-CNN中的多次卷積變為一次卷積,大大降低了計算量,不僅減少儲存量而且加快了訓練速度。
2.在最後一個卷積層和第一個全連線層之間做一些處理,引入了Spatial Pyramid pooling層,對卷積特徵影象進行空間金字塔取樣獲得固定長度的輸出,可對特徵層任意長寬比和尺度區域進行特徵提取。
Spatial Pyramid pooling具體做法:
在得到卷積特徵圖之後,對卷積特徵圖進行三種尺度的切分:4*4,2*2,1*1,對於切分出來的每個小塊進行max-pooling下采樣,之後再將下采樣的結果全排列成一個列向量,送入全連線層。
Spatial Pyramid pooling操作示意圖:
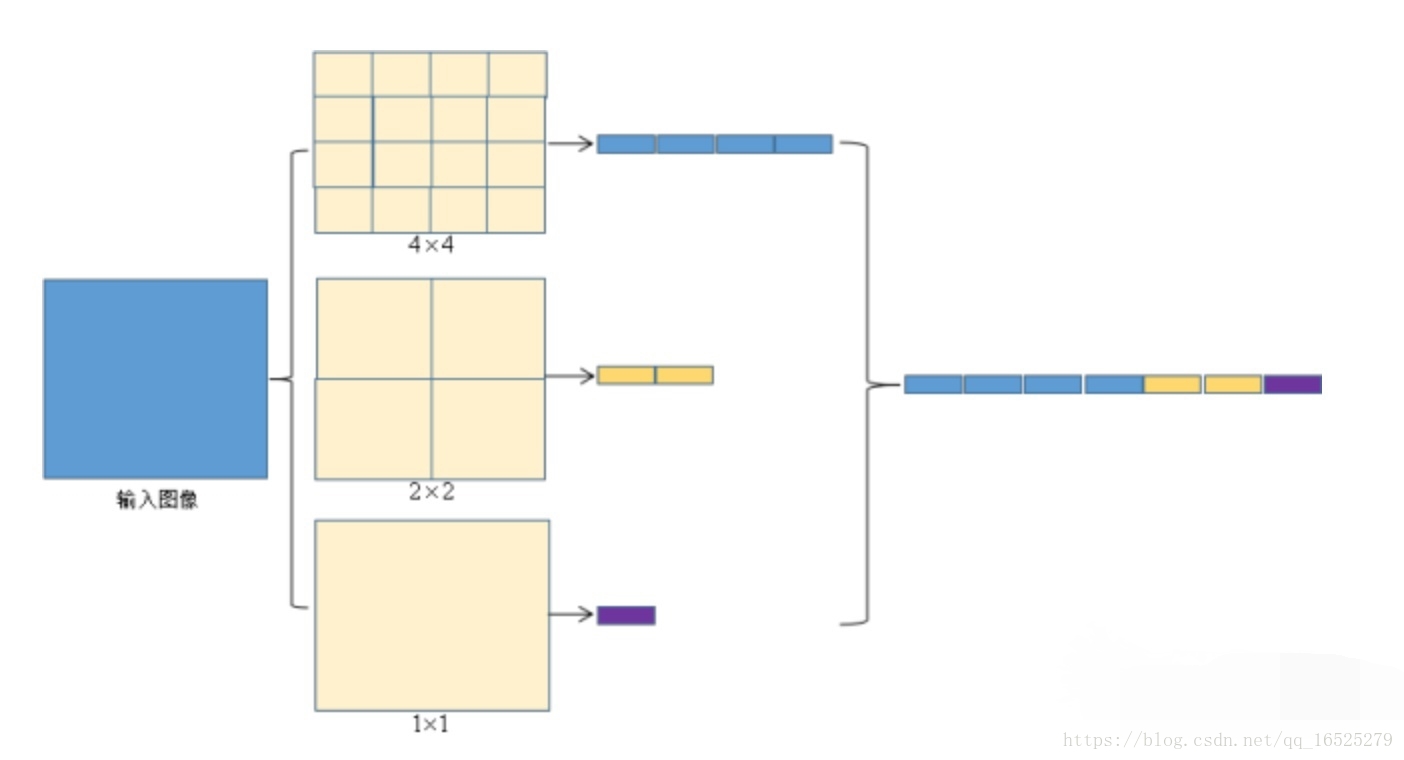
例如每個候選區域在最後的512張卷積特徵圖中得到了512個該區域的卷積特徵圖,通過spp-net下采樣後得到了一個512×(4×4+2×2+1×1)維的特徵向量,這樣就將大小不一的候選區的特徵向量統一到了一個維度。
總結:不僅減少了計算冗餘,更重要的是打破了固定尺寸輸入這一束縛。
Fast R-CNN
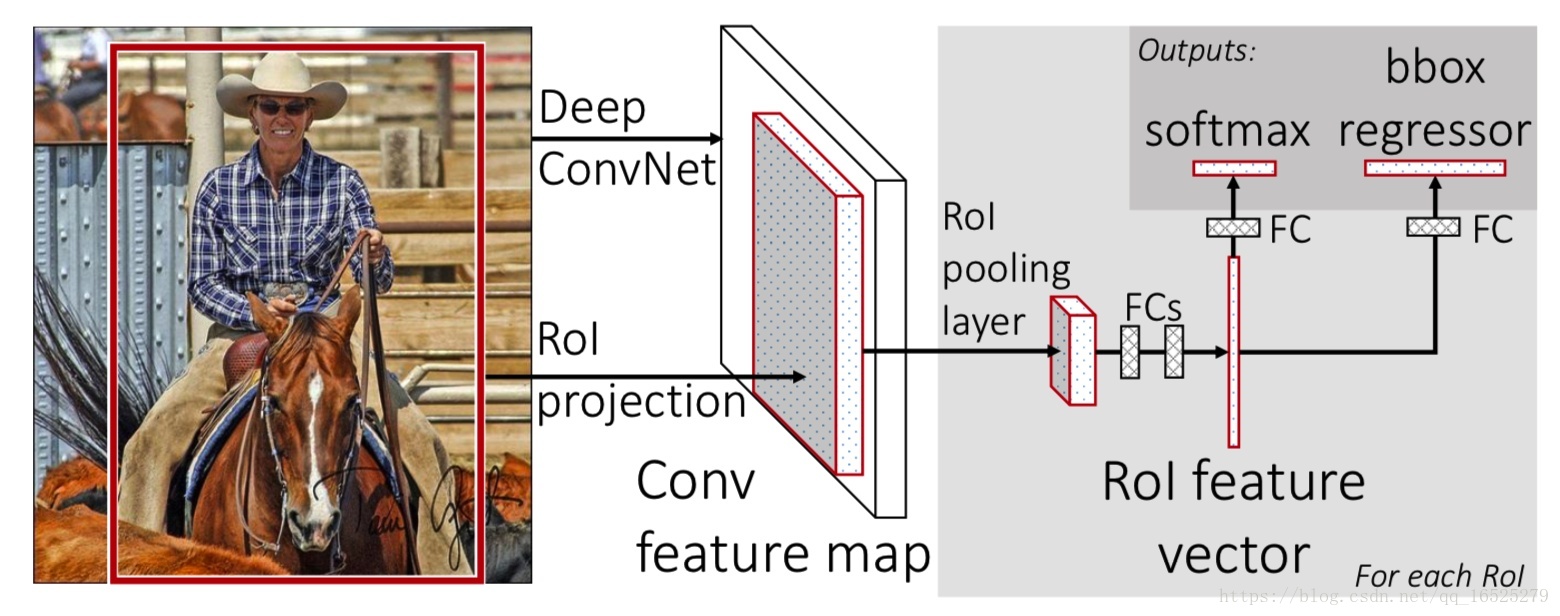
結構創新:將原來的序列結構改成並行結構。
網路創新:加入RoI pooling layer,它將不同大小候選框的卷積特徵圖統一取樣成固定大小的特徵。ROI池化層的做法和SPP層類似,但只使用一個尺度進行網格劃分和池化。
Fast R-CNN針對R-CNN和SPPNet在訓練時是多階段的和訓練的過程中很耗費時間空間的問題進行改進。設計了多工損失函式(multi-task loss),將分類任務和邊框迴歸統一到了一個框架之內。
Faster R-CNN
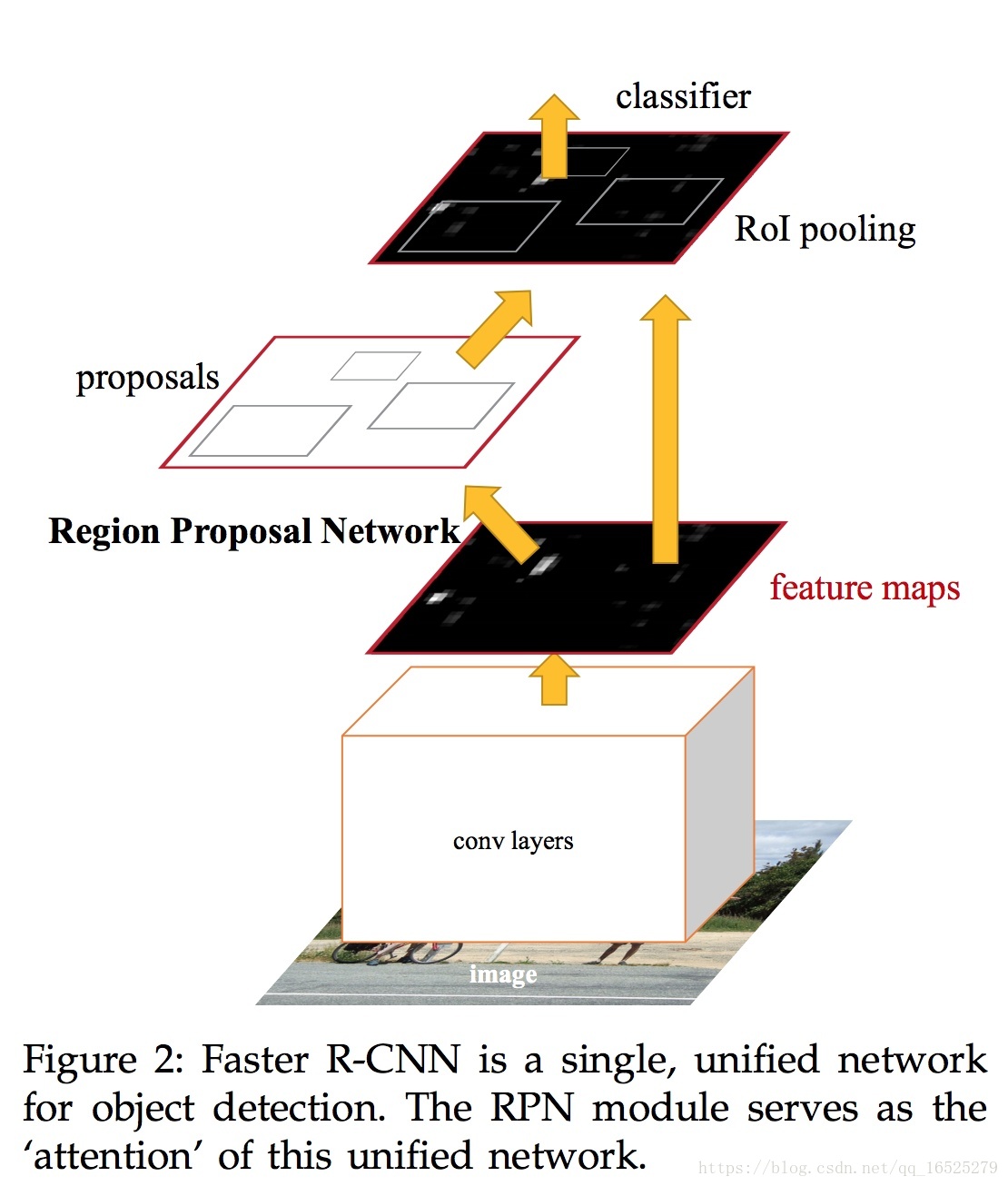
在Faster R-CNN之前,生成候選區域都是用的一系列啟發式演算法(Selective Search),基於Low Level特徵生成區域。
存在的問題:
1.生成區域的靠譜程度隨緣,而Two Stage演算法正是依靠生成區域的靠譜程度——生成大量無效區域則會造成算力的浪費、少生成區域則會漏檢;
2.生成候選區域的演算法(Selective Search)是在 CPU 上執行的,而訓練在GPU上面,跨結構互動必定會有損效率。
革新:提出Region Proposal Network(RPN)網路替代Selective Search演算法,利用神經網路自己學習去生成候選區域。
這種生成方法同時解決了上述的兩個問題,神經網路可以學到更加高層、語義、抽象的特徵,生成的候選區域的可靠程度大大提高。
使得整個目標識別真正實現了端到端的計算,將所有的任務都統一在了深度學習的框架之下,所有計算都在GPU內進行,使得計算的速度和精度都有了大幅度提升。
從上圖看出RPN和RoI pooling共用前面的卷積神經網路——將RPN嵌入原有網路,原有網路和RPN一起預測,大大地減少了引數量和預測時間。
Faster R-CNN在做下采樣和RoI Pooling時都對特徵圖大小做了取整操作。
整體思路:首先對整張圖片進行卷積計算,得到卷積特徵,然後利用RPN進行候選框選擇,再返回卷積特徵圖取出候選框內的卷積特徵利用ROI提取特徵向量最終送入全連線層進行精確定位和分類,總之:RPN+Fast R-CNN=Faster R-CNN。
RPN網路
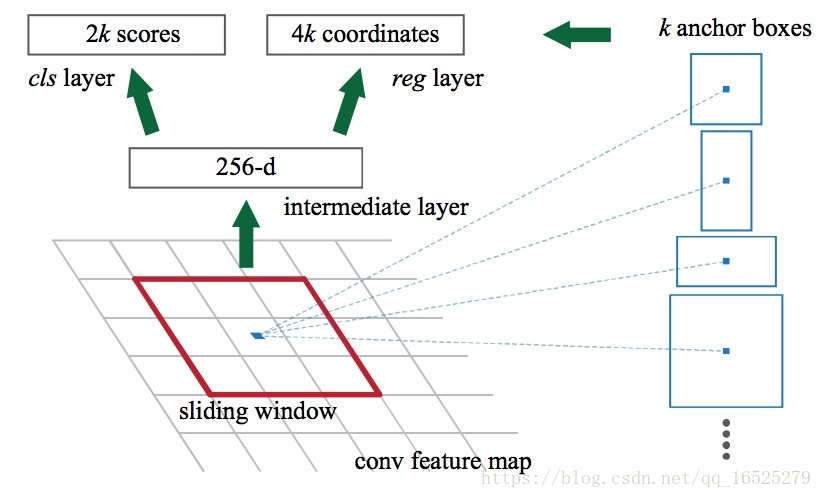
在RPN中引入了anchor的概念,feature map中每個滑窗位置都會生成 k 個anchor,然後判斷anchor覆蓋的影象是前景還是背景,同時迴歸Bounding box(Bbox)的精細位置,預測的Bbox更加精確。
解釋:為了提取候選框,作者使用了一個小的神經網路也即就是一個n×n的卷積核(文中採用了3×3的網路),在經過一系列卷積計算的特徵圖上進行滑移,進行卷積計算。每一個滑窗計算之後得到一個低維向量(例如VGG net 最終有512張卷積特徵圖,每個滑窗進行卷積計算的時候可以得到512維的低維向量),得到的特徵向量,送入兩種層:一種是邊框迴歸層進行定位,另一種是分類層判斷該區域是前景還是背景。3*3滑窗對應的每個特徵區域同時預測輸入影象3種尺度(128,256,512),3種長寬比(1:1,1:2,2:1)的region proposal,這種對映的機制稱為anchor。所以對於40*60圖圖,總共有約20000(40*60*9)個anchor,也就是預測20000個region proposal。
總結:Faster R-CNN可以說是真正意義上的深度學習目標檢測演算法。Faster R-CNN將一直以來分離的region proposal和CNN分類融合到了一起,使用端到端的網路進行目標檢測,無論在速度上還是精度上都得到了不錯的提高。然而Faster R-CNN還是達不到實時的目標檢測,預先獲取region proposal,然後在對每個proposal分類計算量還是比較大。
小結:
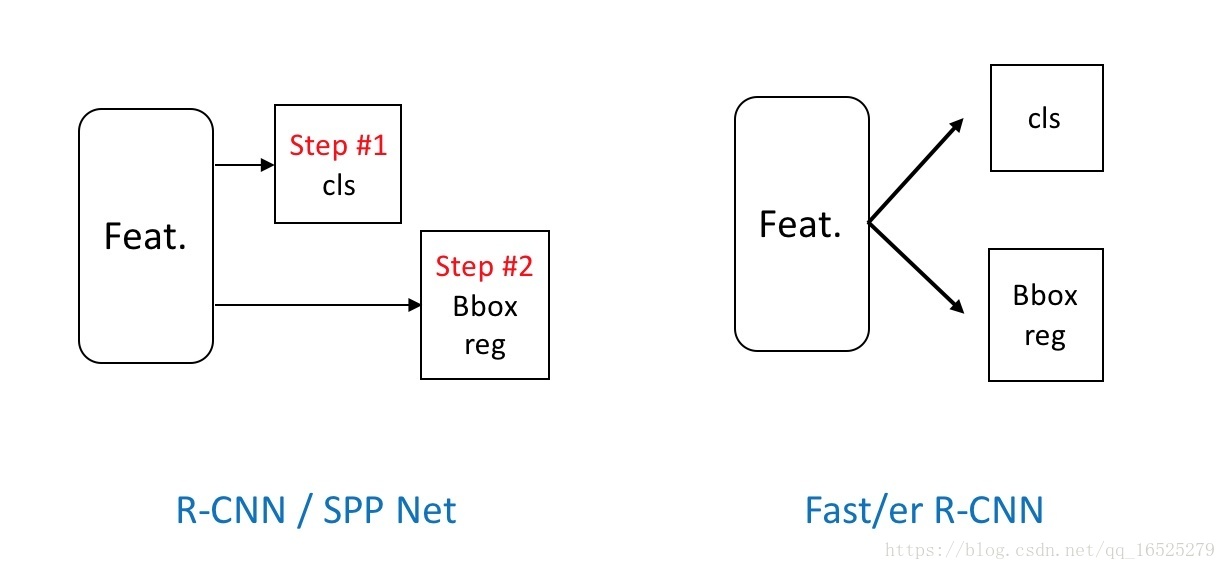
一開始的序列到並行,從單一資訊流到兩條資訊流。
總的來說,從R-CNN, SPP NET, Fast R-CNN, Faster R-CNN一路走來,基於深度學習目標檢測的流程變得越來越精簡,精度越來越高,速度也越來越快。可以說基於region proposal的R-CNN系列目標檢測方法是當前目標最主要的一個分支。
One-Stage:
儘管Faster R-CNN在計算速度方面已經取得了很大進展,但是仍然無法滿足實時檢測的要求,因此有人提出了基於迴歸的方法直接從圖片中迴歸出目標物體的位置以及種類。具有代表性的兩種方法是YOLO和SSD。
YOLO

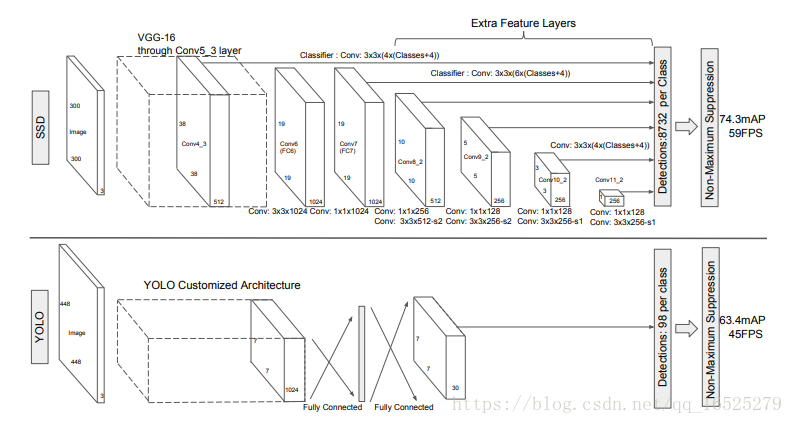
區別於R-CNN系列為代表的兩步檢測演算法,YOLO捨去了候選框提取分支(Proposal階段),直接將特徵提取、候選框迴歸和分類在同一個無分支的卷積網路中完成,使得網路結構變得簡單,檢測速度較Faster R-CNN也有近10倍的提升。這使得深度學習目標檢測演算法在當時的計算能力下開始能夠滿足實時檢測任務的需求。
網路結構:
首先將圖片resize到固定尺寸(448 * 448),然後通過一套卷積神經網路,最後接上全連線直接輸出結果,這就他們整個網路的基本結構。
更具體地做法,是將輸入圖片劃分成一個S*S的網格,每個網格負責檢測網格里面的物體是啥,並輸出Bbox Info和置信度。這裡的置信度指的是該網格內含有什麼物體和預測這個物體的準確定。
更具體的是如下定義:

從這個定義得知,當框中沒有物體的時候,整個置信度都會變為 0 。
這個想法其實就是一個簡單的分而治之想法,將圖片卷積後提取的特徵圖分為S*S塊,然後利用優秀的分類模型對每一塊進行分類,將每個網格處理完使用NMS(非極大值抑制)的演算法去除重疊的框,最後得到我們的結果。
YOLO模型:
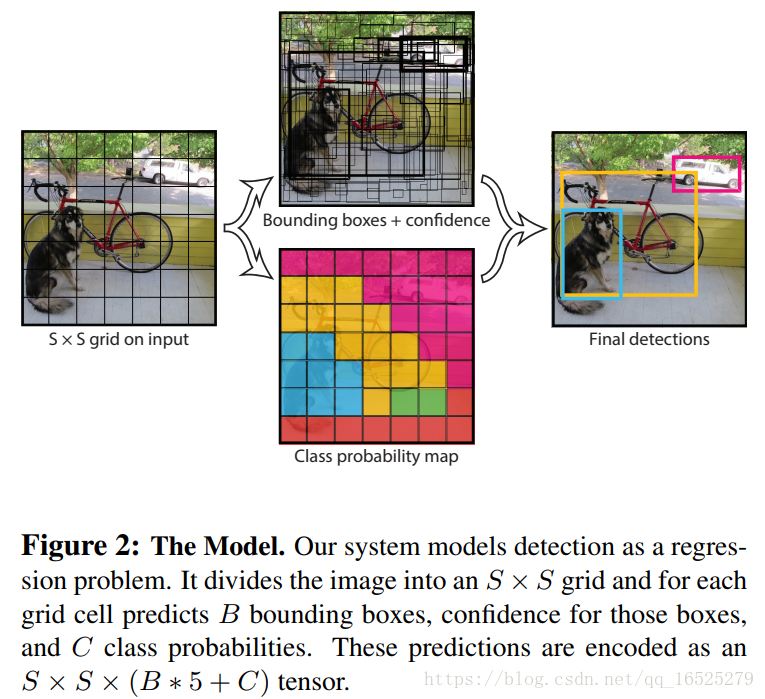
圖片描述:
(1) 給個一個輸入影象,首先將影象劃分成7*7的網格。
(2) 對於每個網格,我們都預測2個邊框(包括每個邊框是目標的置信度以及每個邊框區域在多個類別上的概率)。
(3)根據上一步可以預測出7*7*2個目標視窗,然後根據閾值去除可能性比較低的目標視窗,最後非極大值抑制去除冗餘視窗即可。
可以看到整個過程非常簡單,不需要中間的region proposal在找目標,直接回歸便完成了位置和類別的判定。
SSD
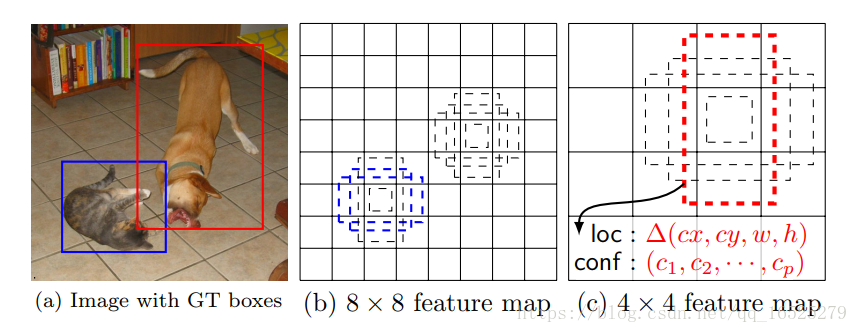
YOLO 這樣做的確非常快,但是問題就在於這個框有點大,就會變得粗糙——小物體就容易從這個大網中漏出去,因此對小物體的檢測效果不好。
所以 SSD 就在 YOLO 的主意上添加了 Faster R-CNN 的 Anchor 概念,並融合不同卷積層的特徵做出預測。
上圖是SSD的一個框架圖,首先SSD獲取目標位置和類別的方法跟YOLO一樣,都是使用迴歸,但是YOLO預測某個位置使用的是全圖的特徵,SSD預測某個位置使用的是這個位置周圍的特徵(感覺更合理一些)。
假如某一層特徵圖大小是8*8,那麼就使用3*3的滑窗提取每個位置的特徵,然後這個特徵迴歸得到目標的座標資訊和類別資訊(圖c)。不同於Faster R-CNN,這個anchor是在多個feature map上,這樣可以利用多層的特徵並且自然的達到多尺度(不同層的feature map 3*3滑窗感受野不同)。
特點:
1.基於多尺度特徵影象的檢測:在多個尺度的卷積特徵圖上進行預測,以檢測不同大小的目標,一定程度上提升了小目標物體的檢測精度。
2.借鑑了Faster R-CNN中的Anchor思想,在不同尺度的特徵圖上取樣候選區域,一定程度上提升了檢測的召回率以及小目標的檢測效果。
還有一個重大的進步是結合了不同尺寸大小 Feature Maps 所提取的特徵,然後進行預測。
這個嘗試就大大地提高了識別的精度,且高解析度(尺寸大)的 Feature Map 中含有更多小物體的資訊,也是因為這個原因 SSD 能夠較好的識別小物體。
總結:和 YOLO 最大的區別是,SSD 沒有接 FC 減少了大量的引數量、提高了速度。
小結:
SSD和YOLO採用了迴歸方法進行目標檢測使得目標檢測速度大大加快,SSD引入Faster R-CNN的anchor機制使得目標定位和分類精度都較YOLO有了大幅度提高。基於迴歸方法的目標檢測基本達到了實時的要求,是目標檢測的另一個主要思路。