
Spark2.x寫入Elasticsearch的效能測試
一、Spark整合ElasticSearch的設計動機
ElasticSearch 毫秒級的查詢響應時間還是很驚豔的。其優點有:
1. 優秀的全文檢索能力
2. 高效的列式儲存與查詢能力
3. 資料分散式儲存(Shard 分片)
相應的也存在一些缺點:
1. 缺乏優秀的SQL支援
2. 缺乏水平擴充套件的Reduce(Merge)能力,現階段的實現侷限在單機
3. JSON格式的查詢語言,缺乏程式設計能力,難以實現非常複雜的資料加工,自定義函式(類似Hive的UDF等)
Spark 作為一個計算引擎,可以克服ES存在的這些缺點:
1. 良好的SQL支援
2. 強大的計算引擎,可以進行分散式Reduce
3. 支援自定義程式設計(採用原生API或者編寫UDF等函式對SQL做增強)
所以在構建即席多維查詢系統時,Spark 可以和ES取得良好的互補效果
二、Spark與ElasticSearch結合的架構和原理
ES-Hadoop無縫打通了ES和Hadoop兩個非常優秀的框架,我們既可以把HDFS的資料匯入到ES裡面做分析,也可以將es資料匯出到HDFS上做備份,歸檔,其中值得一提的是ES-Hadoop全面的支援了Spark框架,其中包括Spark,Spark Streaming,Spark SQL,此外也支援Hive,Pig,Storm,Cascading,當然還有標準的MapReduce,無論用那一個框架整合ES,都是非常簡潔的。最後還可以使用Kibana提供的視覺化的資料分析一條龍服務,非常棒的組合
整個資料流轉圖如下
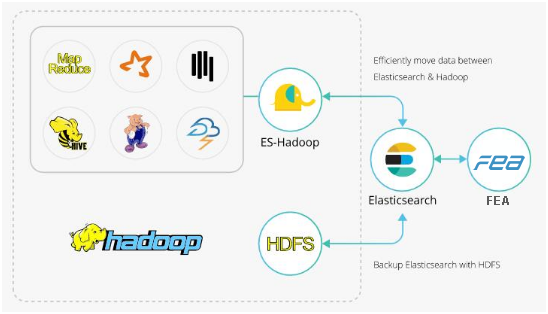
而我們今天要介紹的,就是使用ES-Hadoop裡面的ES-Spark外掛,來完成使用spark向ES裡面大批量插入資料和載入資料。
三、叢集的硬體配置
Spark叢集含有3個節點,FEA-spk和Spark叢集的互動採用yarn-client。
|
主機 |
cpu |
mem |
disk |
|
10.68.23.89 |
1200MHZ*8 |
50g |
400g |
|
10.68.23.90 |
1200MHZ*8 |
50g |
400g |
|
10.68.23.91 |
1200MHZ*8 |
50g |
400g |
四、寫入elasticsearch的資料介紹
elasticsearch副本數量是2個,每一個副本的大小是216.4g
資料的條數為88762914,欄位的個數73個
五、FEA-spk寫入ElasticSearch的原語實現
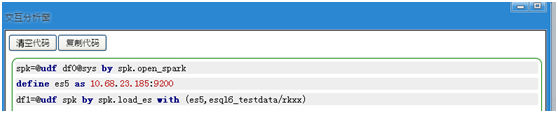
(1) 建立spk的連線
(2) 建立ElasticSearch的連線

(3) 載入資料到es中
資料的格式如下表所示

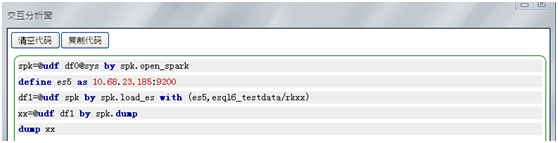
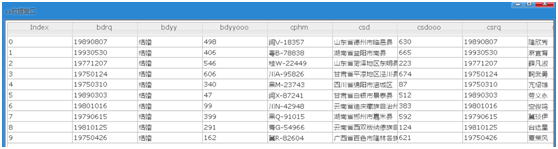
(4) 檢視一下df1表的前十行
(5)將df1表的資料寫回到ES裡面,其中spark是index,people是type
![]()
由於資料量比較大,所以我們選擇後臺執行

進入spark web介面,檢視執行情況
![]()
我們可以看到花費了2.3小時,如果對叢集的資源和引數優化,時間可能會更短
六、Spark寫回資料到ES的效能計算
每秒處理的資料條數=總條數/總時間=88762914/(2.5*60*60)=9863條
每條記錄的大小=總大小/總條數=216.4*1024*1024k/88762914=3K
每秒能寫多少兆=每秒處理的資料條數*每條記錄的大小/1024=9863*3/1024=29M
七、FEA-spk結合ES適用的場景
不會使用Spark,想使用Spark分析存放在ES中的資料,把結果寫入到ES裡面,FEA-spk是一個不錯的選擇。
相關推薦
Spark2.x寫入Elasticsearch的效能測試
一、Spark整合ElasticSearch的設計動機 ElasticSearch 毫秒級的查詢響應時間還是很驚豔的。其優點有: 1. 優秀的全文檢索能力 2. 高效的列式儲存與查詢能力 3. 資料分散式儲存(Shard 分片) 相應的也存在一些缺點: 1
Elasticsearch效能測試
緣起 已釋出至個人部落格 工作中遇到這樣一個問題,業務中有一個支援文字檢索的功能,原本在資料量小的時候,世界都很平靜,可是當資料條數從5W漲到了100W+的時候,世界變了,響應時間急劇增長。怎麼破?這時想到了文字檢索的神器elasticsearch。立馬拿來
elasticsearch效能測試工具rally深入詳解
題記 elasticsearch效能測試研究了很久,自己想過通過批量匯入資料,然後記錄時間,統計CPU、記憶體等變化,計算得出某個效能指標。但顯然,資料量起伏不定,非常不準確。 研究發現,github上提供了rally作為elasticsearch的效能測試
elasticsearch 效能測試
最近花很大的經歷來做效能測試,把結果整理到了ppt中,可能有個別地方不準,但是可以看看一個趨勢。 主要分為兩部分,一部分是寫入elasticsearch效能,一部分是查詢測試,elasticsearch的查詢效能。 當然在elasticsearch1.3.0之後elasticsearch會提供benchma
spark2.x寫入資料到ElasticSearch5.X叢集
首先說明,到目前為止,我使用過spark1.6寫入資料到ES2.4中,使用很簡單。 當我使用spark1.6寫入到ES5.5的時候,一直不成功。 官網首先就講了 through the dedicated support available since 2.1 or thr
timescaledb和PG寫入效能測試
目錄 結論摘要 測試環境 資料構造 CASE 1 單TIME索引 單行寫入 WAL檔案增加 BATCH寫入 資源佔用 CASE 2 增加一個索引 單行寫入 BATCH寫入 資源佔用 CASE 3 大量資料 結論摘要 小
PostgreSQL 資料寫入效能測試
1主2從SR同步流複製測 搭建環境略,可參考之前文章 Server | Role 10.10.56.16 | master 10.10.56.17 | slave1 10.10.56.19 | slave2 16查詢狀態 pocdb=#
ElasticSearch寫入和查詢測試
1,ES的儲存結構瞭解 在ES中,儲存結構主要有四種,與傳統的關係型資料庫對比如下: index(Indices)相當於一個database type相當於一個table document相當於一個row properties(Fields)相當於一個
spark+kafka+Elasticsearch單機環境的部署和效能測試
版本選型 spark 1.5.2 + kafka 0.9.0.1 + Elasticsearch 2.2.1 安裝部署 1. 安裝指令碼及檔案 密碼 4m7l 2. 指令碼使用 vi /etc/hosts 新增 127.0.0.1 hostnamecd npminstall instal
Spark2.x 新特性
引入 ant 版本 eight 執行 次數 調用 出了 afr 二、Spark2.x 介紹 2.1 Spark2.x 與 Spark1.x 關系 Spark2.x 引入了很多優秀特性,性能上有較大提升,API 更易用。在“編程統一”方面非常驚艷,實現了離線計算和流計算 AP
Spark2.x 與 Spark1.x 關系
性能提升 courses structure tex data frame datasets spark1.x 基本 Spark2.x 引入了很多優秀特性,性能上有較大提升,API 更易用。在“編程統一”方面非常驚艷,實現了離線計算和流計算 API 的統一,實現了 Spar
java及spark2.X連接mongodb3.X單機或集群的方法(帶認證及不帶認證)
連接 通過 ava 更新數據 ati out client data 插入數據 首先,我們明確的是訪問Mongos和訪問單機Mongod並沒有什麽區別。接下來的方法都是既可以訪問mongod又可以訪問Mongos的。 另外,讀作java寫作scala,反正大家都看得懂...
dedeCMS遠程寫入getshell(測試版本V5.7)
ext 獲取 dmi 訪問 ges onf all lang unset 該漏洞必須結合apache的解析漏洞: 當Apache檢測到一個文件有多個擴展名時,如1.php.bak,會從右向左判斷,直到有一個Apache認識的擴展名。如果所有的擴展名Apache都不認識,那麽
spark2.x由淺入深深到底系列六之RDD java api詳解二
spark 大數據 javaapi 老湯 rdd package com.twq.javaapi.java7; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.
spark2.x由淺入深深到底系列六之RDD java api調用scala api的原理
spark 大數據 javaapi 老湯 rdd RDD java api其實底層是調用了scala的api來實現的,所以我們有必要對java api是怎麽樣去調用scala api,我們先自己簡單的實現一個scala版本和java版本的RDD和SparkContext一、簡單實現scal
spark2.x由淺入深深到底系列六之RDD java api詳解三
老湯 spark 大數據 javaapi rdd 學習任何spark知識點之前請先正確理解spark,可以參考:正確理解spark本文詳細介紹了spark key-value類型的rdd java api一、key-value類型的RDD的創建方式1、sparkContext.parall
spark2.x由淺入深深到底系列六之RDD java api詳解四
spark 大數據 javaapi 老湯 rdd 學習spark任何的知識點之前,先對spark要有一個正確的理解,可以參考:正確理解spark本文對join相關的api做了一個解釋SparkConf conf = new SparkConf().setAppName("appName")
spark2.x由淺入深深到底系列六之RDD 支持java8 lambda表達式
spark lambda java8 老湯 rdd 學習spark任何技術之前,請正確理解spark,可以參考:正確理解spark我們在 http://7639240.blog.51cto.com/7629240/1966131 中已經知道了,一個scala函數其實就是java中的一個接口
spark2.x由淺入深深到底系列六之RDD java api用JdbcRDD讀取關系型數據庫
spark 大數據 javaapi rdd jdbcrdd 學習任何的spark技術之前,請先正確理解spark,可以參考:正確理解spark以下是用spark RDD java api實現從關系型數據庫中讀取數據,這裏使用的是derby本地數據庫,當然可以是mysql或者oracle等關
spark2.x由淺入深深到底系列五之python開發spark環境配置
spark 大數據 rdd 開發環境 python 學習spark任何的技術前,請先正確理解spark,可以參考: 正確理解spark以下是在mac操作系統上配置用python開發spark的環境一、安裝pythonspark2.2.0需要python的版本是Python2.6+ 或者 P