
大數據反欺詐技術架構
時間也過了很久了,最近看到圈裏一些東西,發現當時的這套架構並未落伍,依然具有很大的參考價值,所以今天跟大夥聊聊關於大數據反欺詐體系怎麽搭建,主要來源是來自於我工作的時候的實踐,以及跟行業裏的很多大佬交流的實踐,算是集小成的一個比較好的實踐。
這套架構我做的時候主要領域是信貸行業的大數據反欺詐,後來也看過電商的架構,也看過金融大數據的架構,發現其實大家使用的其實也差不多是這個套路,只是在各個環節都有不同的細節。
大佬說的,能用圖的,盡量不要打字,那我就打少點字,多做點圖。其實大數據不外乎這麽幾個步驟。數據源開拓、數據抽取、數據存儲、數據清洗和處理、數據應用,且聽我一個一個說。
數據源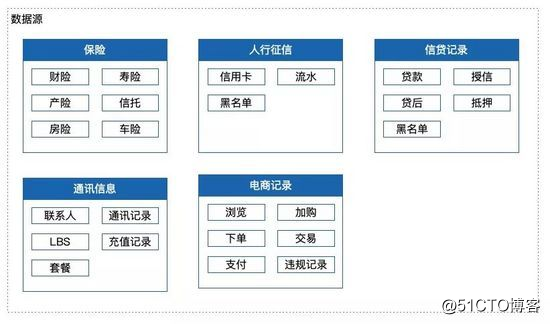
數據源是一個比較重要的點,畢竟如果連數據源都是垃圾,那麽毫無疑問可以預見,最終產出的一定是垃圾,所以挑選數據源和對接數據源的時候都要關註,該機構產出的數據是不是都是質量比較高的數據。
比如人行征信數據就是一個質量非常非常高的數據,主要涉及信用卡、銀行流水、老賴、失信、強制執行信息等,都非常核心,任何一個點都可能是一筆壞賬的苗頭。以及各種行政機構提供的付費機密數據。
比如運營商通訊數據、比如大型電商的行為數據、比如各種保險數據,以及各個機構貸款記錄的互相溝通,這些數據源,都非常核心也都非常值錢,是現在反欺詐非常核心的數據。
當然也有更加粗暴更加高效的做法,就是直接購買外部的黑名單數據,這讓反欺詐變得更加簡單,遇到就直接拒,可以減少非常的人力物力成本去做其他的核查。
數據抽取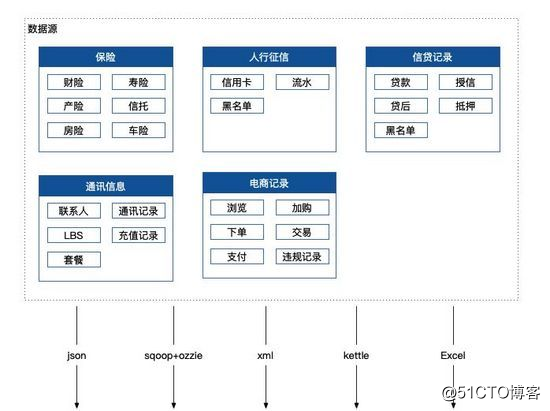
有了高質量的數據源後,當然就是怎麽抽取的問題了,各個機構所提供的數據格式是多種多樣的,其中包括 http 接口的json、xml,內部其他數據源的 etl、定時人工上報的 Excel,以及 sqoop+ozzie 這兩個直接數據抽取通道,這個過程只需要保證通道穩定,數據服務冪等即可,沒什麽特殊的地方。
數據存儲
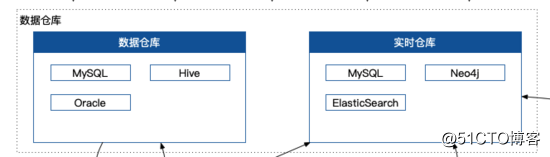
數據存儲其實就是建立一個數據倉庫和一個實時倉庫,數據倉庫用於存儲來自各大數據源的原始數據,實時倉庫用於業務系統的核心作業,數據倉庫的數據量一般都以 T 為單位,實時倉庫以 M 和 G 為單位。
離線計算&實時計算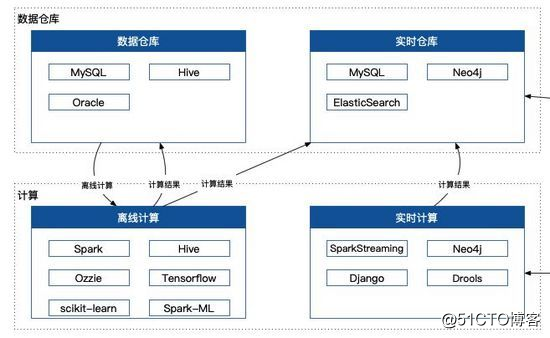
數據保證了,那麽計算就是這套架構的核心之處,從大的角度來看可以分成離線計算和實時計算。
離線計算主要會做兩件事情。Hive 、Spark 數據整合與清洗和離線數據建模。Hive 數據整合主要做的事情就是把各個數據庫裏面的東西,進行清洗和過濾,最終寫到我們定義的標準表裏邊,提供給下遊的計算使用。如果是非常復雜的數據清洗,我們會使用 Spark 寫程序來做,畢竟有一些操作不是 Hive 這種標準 SQL 能解決的。離線數據建模,就是對於這批數據進行建模,以便後續用於實時計算和應用中,算法嘛,精通兩個基本就穩了,LogisticRegression & 決策樹,不要問我為什麽。
實時計算又會做些什麽事情?SparkStreaming和Flink用於實時流計算,主要是用於一些統計類的事情,以及多個數據流的 join 操作。在這裏我們希望做到什麽事情呢?就是希望服務可以準實時,什麽叫準實時呢?就是在一個可以接受的範圍內,我允許你有一定的延遲,這塊我們一開始的任務延遲是 30 min。
我們踩過哪些坑呢?
一開始我們希望使用流批次計算來實現實時計算,實踐下來準實時跟實時還是區別很大的,一個業務通常是允許不了分鐘級別的延遲的,然而 Spark 的 GraphX 必然有分鐘級別的延遲,只適合離線計算。
Hive + Ozzie 處理離線批量處理是一個非常大的利器,很多人都以為Hive數據清洗不就寫寫幾行 SQL?幾百張乃至幾千張表背後的復雜的數據清洗規則,任務依賴,任務重跑,數據質量,數據血緣關系維護。相信我,要是沒有細心和工具,這些能把你搞崩潰。
ElasticSearch 集群多個機器的負載吞吐量,比單臺機器高性能的要高,畢竟網絡卡在那。
我們趟了很多的坑,摸了很多的時候,最終決定把所有的實時操作都架構在 ElasticSearch 和 Neo4j 上,因為我們不僅僅需要實時的全文本全字段社交關系生成,更是需要實時搜索多維度多層社交關系並反欺詐分析,而這個關系可能是百萬級別的,根據六度理論,決定了我們選取的層次不能太多,所以最終我們只抽取其中三層社交關系。最終確定這個架構,這很核心地確定了我們的響應時間,並最終決定了我們服務的可用性。
很多地方產生的結果數據只是整個決策鏈上的一個細節,所以我們還需要 Drools 這類規則引擎幫助做一個最終決策。
業務應用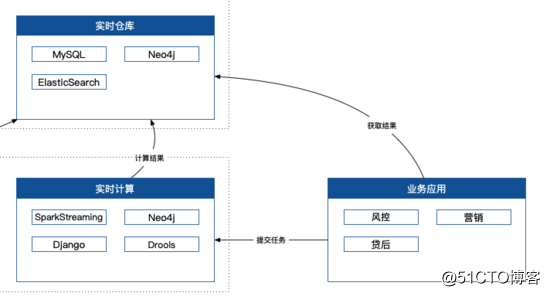
最終業務系統應該怎麽使用,怎麽對外提供服務?這也是一個非常核心的問題,因為這部分要求非常非常穩定,以及非常非常高效,一般來說不允許有太高的延遲,同時還要求非常高的並發量。這就要求了我們第一要盡量提高計算效率,第二要求我們對於系統的架構要有非常高的保障。
計算效率要高效,有什麽技巧呢,保證各個系統之間的交互都是聚合、加工、計算後的結果,而不是原始數據,畢竟網絡傳輸是需要很高成本的在目標數據量非常大的場景下。比如一次性要加載幾十萬條數據,那全部拉回來再重新計算是不是就顯得很蠢了?為什麽不在目標系統裏以數據服務的形式提供呢?
技術架構保障,其實大部分都是基礎架構的事情了,比如動態負載均衡、一主多從、異地多機房容災、斷網演練、上遊服務故障預案等等。
建模之社交網絡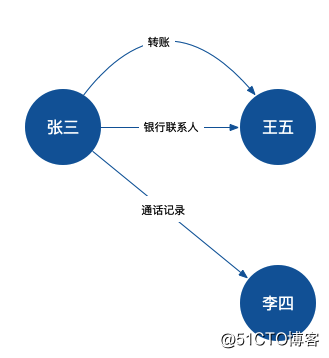
很久以前就已經介紹了各種社區發現算法,這裏就不再贅述,有興趣的自己點進去細致了解一下。
這裏聊聊一個知識圖譜的標準建立過程。
1、主體確認
2、關系建立。
3、邏輯推理建立。
4、圖譜檢索
主體確認,從圖的角度來看就是確認各個頂點,這些頂點有自己的屬性,代表著網絡裏的一個個個體。
關系建立,從其他資料關系得來,也可以根據第三步的邏輯推理得來,從圖的角度來看就是確認各個邊,這些邊有起點有終點也有自己的屬性,代表著網絡裏各個個體的關聯。
邏輯推理建立,這是非常重要的一個部分,比如姚明的老婆的母親,就是姚明的嶽母,這種先驗知識的推理可以在圖譜的幫助下,為我們解決很多的實際問題。
圖譜檢索,有了圖譜我們就開始使用,我們有四件套,主體屬性搜索,關系屬性搜索,廣度優先搜索,寬度優先搜索。我們一般的使用策略都是,優先確定一個頂點比如目標人物,然後向外擴散,直到找到所有符合條件的個體。
這裏我們踩了什麽坑做了什麽優化呢?我們一開始是把整個搜索結果拉到本地再進行計算,而圖譜搜索後的結果總是很大,畢竟我們找了很多維的關系,所以總是卡在網絡這塊。經過探索和咨詢,最終確認了 Neo4j 這種圖數據庫不僅僅提供數據查詢服務,還做了基於定制化的社交網絡分析的插件化開發,把我們的反欺詐服務以插件化的形式部署到服務器中,這就減少了非常多的網絡開銷,保障了我們服務的秒級響應。
完整架構圖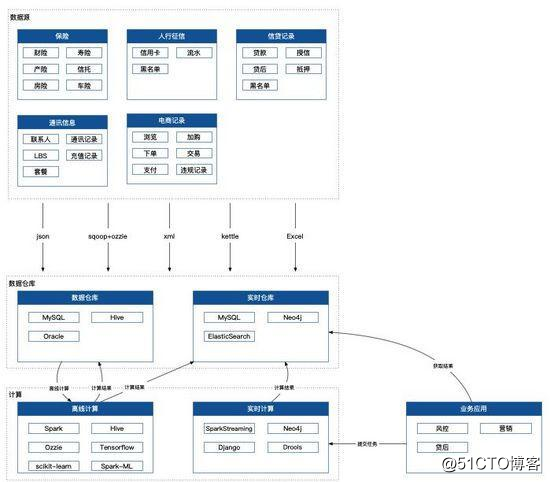
從數據來源、獲取、存儲、加工、應用,一步到位,萬一有點幫助那就更好了,如果還心存疑慮,這篇文章從下往上,再看一遍。
大數據反欺詐技術架構