
文字分詞方法
廢話不多說,我就直接上乾貨吧,從過去到現在所知道的分詞方法有以下幾種:
1、mmseg4j
2、詞頻分組(有序文字足夠)
3、jieba分詞
下面細說一下幾種分詞方法,
第一種,mmseg4j,我使用這種方法是以R來分詞的,所以就用R來說這個包,R中這個包的名字叫“rmmseg4j”,詳情見該帖:[程式分享]R與中文分詞,R中的mmseg包,使用方法如下R code,這種方法還有一個java版本的分詞,大家有興趣的可以試試。
install.packages("rmmseg4j") library(rmmseg4j)#載入安裝包 #然後就是直接的分詞了 word = "我愛小貓小狗,你呢?" mmseg4j(word)
第二種,詞頻分組,該方法就講講邏輯,不具體貼出code了。這種方法是限制較大,它必須根據詞頻、字頻得來的,所以原始資料必須是文章或者是一堆有關聯的關鍵詞,且必須有一定量級才可以使用;
首先,拆分詞句成單字,取一批高頻單字,找出高頻單字所組成的詞,從中選出頻數最高的詞,該詞就是分出的高頻詞根,然後再將該高頻詞根從原文或者詞中去掉,繼續遞迴,最終無法得出詞根為止,這批結果就是高頻詞根了。
該方法限制較多,且可能由於文章或者詞庫的變動較大,對於拆出的詞根會有很大的影響。
第三種,jieba是“結巴”中文分詞(Python)的版本,支援最大概率法(Maximum Probability),隱式馬爾科夫模型(Hidden Markov Model),索引模型(QuerySegment),混合模型(MixSegment)共四種分詞模式。接觸它的時候是使用的R版本,後面才開始使用python版本這裡我就不想詳細具體說怎麼使用的問題,我直接貼上地址,大家可以學習,
1、
2、【python版本的結巴分詞技術詳解】,【python結巴分詞使用方法】
關於結巴分詞,網上有很多相關資料,大家可以自己搜搜。這裡只是起個引線作用。
這三種方式,使用後,覺得準確率和效率最好的方法應該是第三種,所以推薦大家使用第三種方式,大家如果有更好的方法也請推薦給我,謝謝。
相關推薦
文字分詞方法
廢話不多說,我就直接上乾貨吧,從過去到現在所知道的分詞方法有以下幾種: 1、mmseg4j 2、詞頻分組(有序文字足夠) 3、jieba分詞 下面細說一下幾種分詞方法, 第一種,mmseg4j,我使用這種方法是以R來分詞的,所以就用R來說這個包,R中這
常見的中文分詞方法
常見的中文分詞方法 1.基於規則的方法(字串匹配、機械分詞) 定義:按照一定規則將待分析的漢字串與詞典中的詞條進行匹配,找到則切分,否則不予切分。按照匹配切分的方式,主要有正向最大匹配方法、逆向最大匹配方法和雙向最大匹配三種方法。
[python] jieba 模組 -- 給中文文字分詞
在文字處理時,英文文字的分詞一直比中文文字要好處理許多。因為英文文字只需要通過空格就可以分割,而中文的詞語往往就很難從句子中分離出來。這種時候我們往往需要一個“詞典”來實現分詞,而尋找“詞典”又是件非常麻煩的事。 不過, python 強大的第三方模組中早有了解決方案。在 PyPI 上面搜尋“中
elasticsearch 外掛開發-自定義分詞方法
自定義elasticsearch外掛實現 1 外掛專案結構 這是一個傳統的maven專案結構,主要是多了一些外掛需要的的目錄和檔案 plugin.xml和plugin-descriptor.properties這兩個是外掛的主要配置和描述 pom.xml裡面也
期末作業——波士頓房價預測及中文文字分詞
一、boston房價預測 1. 讀取資料集 from sklearn.datasets import load_boston boston = load_boston() boston.keys() print(boston.DESCR) boston.data.shape imp
java 中文文字分詞
java 中文文字分詞 本文使用 classifier4J 以及 IKAnalyzer2012_u6 實現中文分詞。可以增加自定義詞庫,詞庫儲存為 “exdict.dic” 檔案,一個詞一行。 // MyTokenizer.java 檔案 import java.io.Buff
淺談分詞演算法(4)基於字的分詞方法(CRF)
目錄 前言 目錄 條件隨機場(conditional random field CRF) 核心點 線性鏈條件隨機場 簡化形式 CRF分詞 CRF VS HMM 程式碼實現 訓練程式碼 實驗結果 參考文獻
自然語言處理-中文分詞方法總結
中文分詞是中文文字處理的一個基礎步驟,也是中文人機自然語言互動的基礎模組。不同於英文的是,中文句子中沒有詞的界限,因此在進行中文自然語言處理時,通常需要先進行分詞,分詞效果將直接影響詞性、句法樹等模組的效果。當然分詞只是一個工具,場景不同,要求也不同。前人做的工
lingpipe: 文字分詞識別例子
1)什麼是lingpipe? 詳細見百度,簡而言之是自然語言處理軟體包(Natural Language Processing,NLP)。 lingpipe主要包含以下模組: 主題分類(Top Classification) 命名實體識別(Named Entity Rec
python自然語言處理(NLP)1------中文分詞1,基於規則的中文分詞方法
python中文分詞方法之基於規則的中文分詞 目錄 常見中文分詞方法 推薦中文分詞工具 參考連結 一、四種常見的中文分詞方法: 基於規則的中文分詞 基於統計的中文分詞 深度學習中文分詞 混合分詞方法 基於規則的中
概率語言模型分詞方法
4.6 概率語言模型的分詞方法 從統計思想的角度來看,分詞問題的輸入是一個字串C=C1,C2,……,Cn,輸出是一個詞串S=W1,W2,……,Wm,其中m<=n。對於一個特定的字串C,會有多個切分方案S對應,分詞的任務就是在這些S中找出概率最大的一個切分方案,也就是
常用中文分詞方法
一、正向最大匹配FMM從左到右將待分詞文字中的最多個連續字元與詞表匹配,如果匹配上,則切分出一個詞。二、逆向最大匹配從右到左將待分詞文字中的最多個連續字元與詞表匹配,如果匹配上,則切分出一個詞。三、雙向最大匹配正向最大匹配演算法和逆向最大匹配演算法.如果兩個演算法得到相同的分
Python進行文字預處理(文字分詞,過濾停用詞,詞頻統計,特徵選擇,文字表示)
系統:win7 32位 分詞軟體:PyNLPIR 整合開發環境(IDE):Pycharm 功能:實現多級文字預處理全過程,包括文字分詞,過濾停用詞,詞頻統計,特徵選擇,文字表示,並將結果匯出為WEKA能夠處理的.arff格式。 直接上程式碼: #!/usr/bin/
64位的R中使用Rwordseg做文字分詞遇到的安裝問題
一般Rwordseg並不存在CRAN中,所以進行線上安裝時的命令為: install.packages("Rwordseg", repos = "http://R-Forge.R-project.org", type = "source") 而Rword
自然語言處理基礎(1)--基本分詞方法
基本的分詞方法包括最大匹配法、最大概率法(最短加權路徑法)、最少分詞法、基於HMM的分詞法、基於互現資訊的分詞方法、基於字元標註的方法和基於例項的漢語分詞方法等。 1.最大匹配法 最大匹配法需要一個詞表,分詞的過程中用文字的候選
自然語言處理的中文分詞方法
中文分詞方法 平臺:win7,python,vs2010 1、CRF++ CRF++是著名的條件隨機場開源工具,也是目前綜合性能最佳的CRF工具。 一、工具包的下載: 其中有兩種,一種是Linux下(帶原始碼)的,一種是win32的,下載 ht
hanlp中文自然語言處理分詞方法介紹
自然語言處理在大資料以及近年來大火的人工智慧方面都有著非同尋常的意義。那麼,什麼是自然語言處理呢?在沒有接觸到大資料這方面的時候,也只是以前在學習計算機方面知識時聽說過自然語言處理。書本上對於自然語言處理的定義或者是描述太多專業化。換一個通俗的說法,自然語言處理就是把我們人類
經典的分詞方法實現(JAVA)
基於規則的自動分詞演算法 原理 (1) 事先人工建立好分詞詞典和分詞規則庫。 (2) 原理為基於字串匹配進行分詞,這樣就要求有足夠大的詞表為依據。 (3) 通過一定的演算法來實現,如正向最大匹配法、逆向最大匹配法、雙向匹配法等。 (4) 憂缺點:當分詞
資料庫分詞查詢的優缺點以及英文和中文各自的分詞方法(一)
1.為什麼需要資料庫分詞查詢 假設有一個數據庫表,表中有一個title欄位 table1 假如有300萬的資料 id為主鍵,title也設定了索引 id title 1 這是計算機,
Hive基於UDF進行文字分詞
## 本文大綱 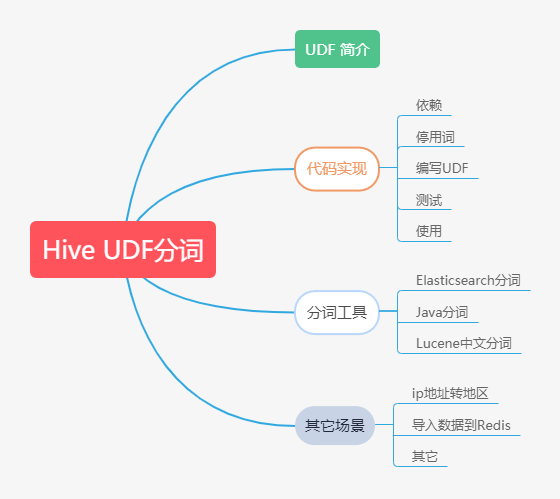 ## UDF 簡介 `Hive`作為一個`sql`查詢引擎,