
hanlp中文自然語言處理分詞方法介紹
自然語言處理在大資料以及近年來大火的人工智慧方面都有著非同尋常的意義。那麼,什麼是自然語言處理呢?在沒有接觸到大資料這方面的時候,也只是以前在學習計算機方面知識時聽說過自然語言處理。書本上對於自然語言處理的定義或者是描述太多專業化。換一個通俗的說法,自然語言處理就是把我們人類的語言通過一些方式或者技術翻譯成機器可以讀懂的語言。
人類的語言太多,計算機技術起源於外國,所以一直以來自然語言處理基本都是圍繞英語的。中文自然語言處理當然就是將我們的中文翻譯成機器可以識別讀懂的指令。中文的博大精深相信每一個人都是非常清楚,也正是這種博大精深的特性,在將中文翻譯成機器指令時難度還是相當大的!至少在很長一段時間裡中文自然語言的處理都面臨這樣的問題。
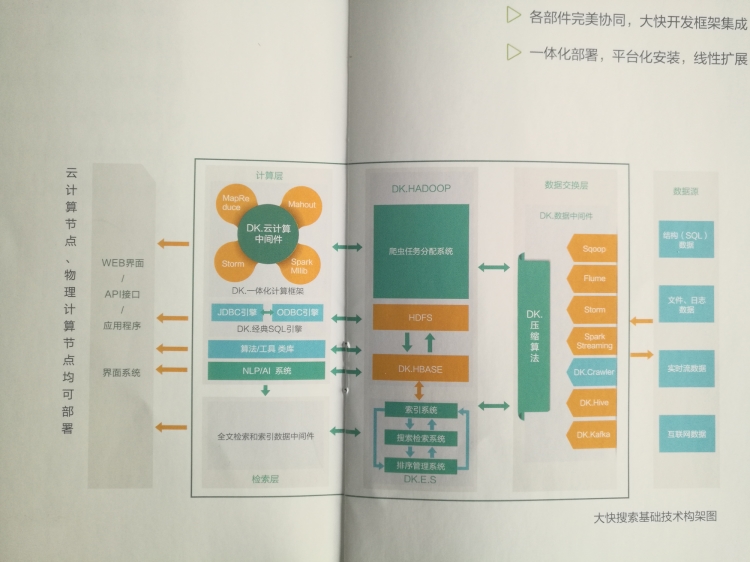
Hanlp中文自然語言處理相信很多從事程式開發的朋友都應該知道或者是比較熟悉的。Hanlp中文自然語言處理是大快搜索在主持開發的,是大快DKhadoop大資料一體化開發框架中的重要組成部分。下面就hanlp中文自然語言處理分詞方法做簡單介紹。
Hanlp中文自然語言處理中的分詞方法有標準分詞、NLP分詞、索引分詞、N-最短路徑分詞、CRF分詞以及極速詞典分詞等。下面就這幾種分詞方法進行說明。
標準分詞:

Hanlp中有一系列“開箱即用”的靜態分詞器,以Tokenizer結尾。HanLP.segment其實是對StandardTokenizer.segment的包裝
NLP分詞:
1. List<Term> termList = NLPTokenizer.segment("中國科學院計算技術研究所的宗成慶教授正在教授自然語言處理課程");
2. System.out.println(termList);
NLP分詞NLPTokenizer會執行全部命名實體識別和詞性標註。
索引分詞:

索引分詞IndexTokenizer是面向搜尋引擎的分詞器,能夠對長詞全切分,另外通過term.offset可以獲取單詞在文字中的偏移量。
N-最短路勁分詞

N最短路分詞器NShortSegment比最短路分詞器慢,但是效果稍微好一些,對命名實體識別能力更強。
一般場景下最短路分詞的精度已經足夠,而且速度比N最短路分詞器快幾倍,請酌情選擇。
CRF分詞:

CRF對新詞有很好的識別能力,但是無法利用自定義詞典。
極速詞典分詞:
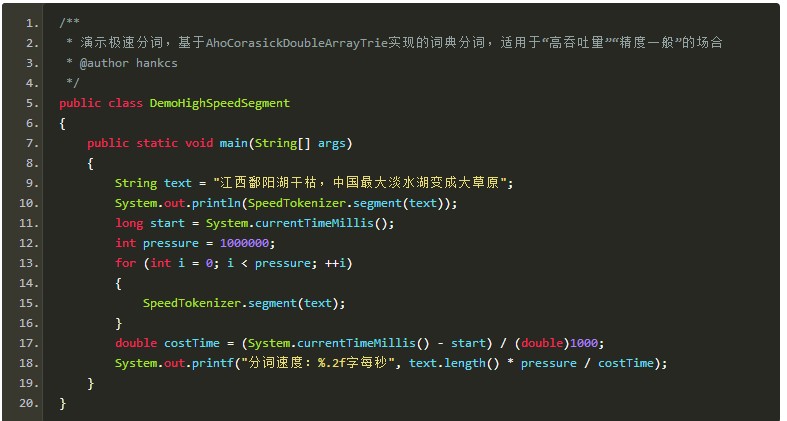
極速分詞是詞典最長分詞,速度極其快,精度一般。
在i7上跑出了2000萬字每秒的速度。
上述資訊整編的並不是很全面,以後在做補充!