
針對不同資料庫,獲取當前使用者所有有許可權檢視的表,以及表的建立時間、更新時間、註釋等資訊,表中欄位的相關資訊(包含分頁實現)
最近在處理一個需求,需求是這樣的:
- 給定任意一個數據庫的JDBC連線、使用者名稱、密碼
- 查詢出所有有許可權訪問的表的相關資訊:表名,建立時間,更新時間,註釋
- 要支援分頁
- 資料庫型別有:MySQL、GBase、Oracle、DB2、Greenplum、Hive
- 本來還有 HDFS和Kafka的,但是後來去掉了。
我自己平時主要使用的是 mysql, 所以,對於 mysql 而言,這個需求還是比較好處理的。但是其他幾個就比較困難了,甚至有些之前連名字都沒有聽過,如 Greenplum、GBase。
不過,需求總得處理啊。就為這個需求,我整整搞了四天。下面就把處理方法記錄一下吧。在重點的地方我會加上註釋。
首先,看一下最終的型別的結構圖吧
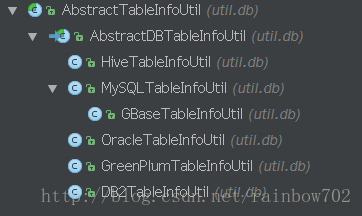
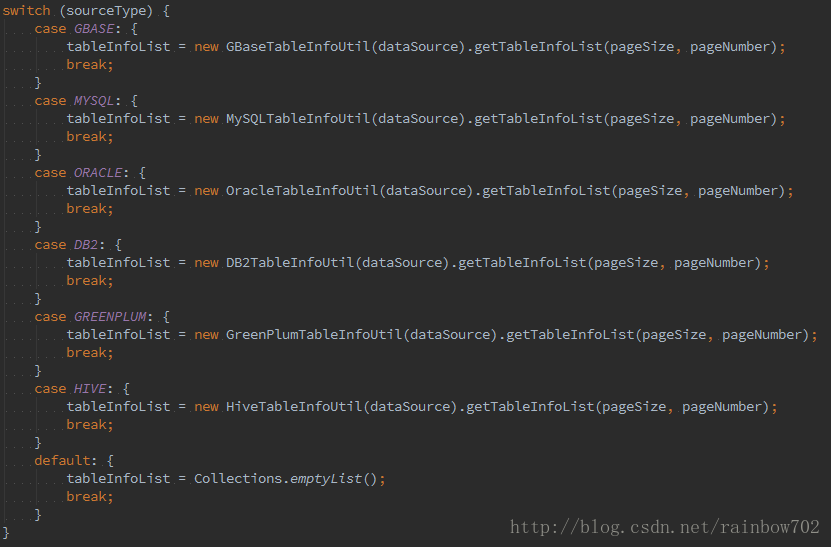
然後看一下使用方式
根據不同的資料庫型別,使用對應的子類進行處理。
AbstractTableInfoUtil.java
所有處理類的超類
public abstract class AbstractTableInfoUtil {
// 一個物件,它包括了 jdbc url、jdbc driver class、username、password
protected final BiDataSource dataSource;
public AbstractTableInfoUtil AbstractDBTableInfoUtil.java
作為所有資料處理類的超類。
之所以新建這個超類,是因為需求一開始還有 HDFS 和 Kafka ,而這兩個是 非DB類的。
public abstract class AbstractDBTableInfoUtil extends AbstractTableInfoUtil {
private static final String TABLE = "TABLE";
private static final String TABLE_SCHEMA = "TABLE_SCHEM";
private static final String TABLE_NAME = "TABLE_NAME";
private static final String COLUMN_NAME = "COLUMN_NAME";
private static final String COLUMN_SIZE = "COLUMN_SIZE";
private static final String TYPE_NAME = "TYPE_NAME";
private static final String COLUMN_DEF = "COLUMN_DEF";
/**
* 需要排除的 schema。
* 一般是那些系統的schema。
* 在子類中具體指定。
*/
protected String excludeSchema;
public AbstractDBTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
}
// util 方法,用於將 "%" 和 "_" 進行轉義
protected static String escapeWildcard(String source, String escape) {
if (null == source || "".equals(source)) {
return null;
}
String result = source.replace("%", (escape + "%"));
result = result.replace("_", (escape + "_"));
return result;
}
// 獲取有許可權訪問的所有表的總數
@Override
public int getTableCount(final BiDataSource dataSource) {
int total = 0;
// 由子類生成 獲取總數 的SQL 語句
String sql = getTableCountSQL();
play.Logger.info(sql);
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
PreparedStatement ps = connection.prepareStatement(sql)) {
ResultSet countResult = ps.executeQuery();
if (countResult.next()) {
total = countResult.getInt(1);
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return total;
}
// 獲取表的總數的SQL。由子類實現。
protected abstract String getTableCountSQL();
// 獲取表的所有欄位
// 所有資料庫都會提供相應的 JDBC driver,
// 所以我們只要通過 JDBC 中的 getColumns() 方法,就可以獲取表中的所有欄位
@Override
protected List getTableFields(final BiDataSource dataSource, final String schemaName, final String tableName) {
List list = new ArrayList();
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password)) {
DatabaseMetaData metaData = connection.getMetaData();
// 注意,此處 需要對 schema 和 table 的名稱進行 "%" 和 "_" 字元的轉義
final String schema = escapeWildcard(schemaName, metaData.getSearchStringEscape());
final String table = escapeWildcard(tableName, metaData.getSearchStringEscape());
ResultSet resultSet;
SourceType sourceType = this.getSourceType();
// mysql 和 gbase 與其他DB的處理方式不一樣
// 為啥不一樣?如果不這麼處理,那麼,mysql 將無法獲取 jdbc url 指定的schema 以外的schema 中的表的欄位
// 比如,給定一個jdbc url: jdbc:mysql://localhost:3306/test
// 那麼,我們將只能獲取 test 這個schema 下的表的欄位
// 具體請參照: http://stackoverflow.com/questions/38557956/databasemetadatagetcolumns-returns-an-empty-resultset
if (sourceType == SourceType.MYSQL || sourceType == SourceType.GBASE) {
resultSet = metaData.getColumns(schema, null, table, "%");
} else {
resultSet = metaData.getColumns(null, schema, table, "%");
}
while (resultSet.next()) {
// TableFieldInfo 是一個POJO
TableFieldInfo tableFieldInfo = new TableFieldInfo();
tableFieldInfo.name = resultSet.getString(COLUMN_NAME);
tableFieldInfo.type = resultSet.getString(TYPE_NAME);
tableFieldInfo.defaultValue = resultSet.getObject(COLUMN_DEF);
tableFieldInfo.length = resultSet.getInt(COLUMN_SIZE);
Map map = tableFieldInfo.toMap();
list.add(map);
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return list;
}
// 獲取 jdbc url 下所有有許可權訪問的 schema
// 本來沒有這個方法的,在最後處理到 Hive 時,沒有辦法了,才加了這個方法
public List<String> getSchemas(final BiDataSource dataSource) {
List<String> schemaList = new ArrayList<>();
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password)) {
DatabaseMetaData dbMetaData = connection.getMetaData();
ResultSet schemaSet = dbMetaData.getSchemas();
while (schemaSet.next()) {
schemaList.add(schemaSet.getString(TABLE_SCHEMA));
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return schemaList;
}
// 獲取指定 schema 下的所有表
// 本來沒有這個方法的,在最後處理到 Hive 時,沒有辦法了,才加了這個方法
// 不過,這個方法被下面的同名方法給取代了,但也沒有刪除此方法。
public List<String> getTables(final BiDataSource dataSource, String schemaName) {
List<String> tableList = new ArrayList<>();
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password)) {
DatabaseMetaData dbMetaData = connection.getMetaData();
final String schema = escapeWildcard(schemaName, dbMetaData.getSearchStringEscape());
ResultSet tableRet;
SourceType sourceType = this.getSourceType();
// 此處處理,請參見上面 getTableFields() 方法的說明
if (sourceType == SourceType.MYSQL || sourceType == SourceType.GBASE) {
tableRet = dbMetaData.getTables(schema, null, "%", new String[]{TABLE});
} else {
tableRet = dbMetaData.getTables(null, schema, "%", new String[]{TABLE});
}
while (tableRet.next()) {
tableList.add(tableRet.getString(TABLE_NAME));
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableList;
}
// 獲取指定 schema 下的所有表
// 本來沒有這個方法的,在最後處理到 Hive 時,沒有辦法了,才加了這個方法
// 與上面的方法基本一樣,該方法可以同時處理多個 schema
public List<Pair<String, String>> getTables(final BiDataSource dataSource, List<String> schemas) {
// pair: {key: schema, value: table}
List<Pair<String, String>> tableList = new ArrayList<>();
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password)) {
DatabaseMetaData dbMetaData = connection.getMetaData();
for (String schemaName : schemas) {
final String schema = escapeWildcard(schemaName, dbMetaData.getSearchStringEscape());
ResultSet tableRet;
SourceType sourceType = this.getSourceType();
try {
// 此處處理,請參見上面 getTableFields() 方法的說明
if (sourceType == SourceType.MYSQL || sourceType == SourceType.GBASE) {
tableRet = dbMetaData.getTables(schema, null, "%", new String[]{TABLE});
} else {
tableRet = dbMetaData.getTables(null, schema, "%", new String[]{TABLE});
}
while (tableRet.next()) {
tableList.add(new Pair(schemaName, tableRet.getString(TABLE_NAME)));
}
} catch (SQLException e) {
play.Logger.error(e.getMessage(), e);
}
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableList;
}
}MySQLTableInfoUtil.java
Mysql資料庫對應的處理類。
public class MySQLTableInfoUtil extends AbstractDBTableInfoUtil {
private static final String TABLE_NAME = "TABLE_NAME";
private static final String TABLE_SCHEMA = "TABLE_SCHEMA";
private static final String CREATE_TIME = "CREATE_TIME";
private static final String UPDATE_TIME = "UPDATE_TIME";
private static final String TABLE_COMMENT = "TABLE_COMMENT";
public MySQLTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
// 指定系統 schema
excludeSchema = "('information_schema')";
}
@Override
protected SourceType getSourceType() {
return SourceType.MYSQL;
}
// 獲取表的總數的SQL
@Override
protected String getTableCountSQL() {
// 在 使用 MessageFormat 時,一定要注意:若字串需要使用單引號(')時,必須連續寫兩個,否則,將在 format 時,將會被去掉
// 即,如果寫成 'T',那麼,最終結果是 T,如果是 ''T'',最終結果才是 'T'
// 不過,作為引數傳給 format 時,只需要寫一個 ' 即可,如上面的 excludeSchema 的值
String sql = MessageFormat.format("SELECT COUNT(1) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA NOT IN {0} AND TABLE_TYPE=''BASE TABLE''", excludeSchema);
play.Logger.info(sql);
return sql;
}
// 獲取指定數量的 表的集合,即分頁
@Override
protected List getTableInfoList(final BiDataSource dataSource, final int pageSize, final int pageNumber) {
// mysql的版本需要在 5.7 以上,否則,create_time 和 update_time 可能返回NULL
play.Logger.warn("For mysql, make sure the server which you connect to is of version >= 5.7.x");
play.Logger.warn("If not, the CREATE_TIME and UPDATE_TIME maybe return NULL");
List tableProperties = new ArrayList();
final int offset = (pageNumber - 1) * pageSize;
final int limit = pageSize;
// 把欄位名作成了引數({0} ~ {4})傳了進去,這樣做是為了保證在下面的 ResultSet get時,可以直接使用 列名,而不是使用 index
String sql = MessageFormat.format("" +
"SELECT {0}, {1}, {2}, {3}, {4} FROM INFORMATION_SCHEMA.TABLES " +
"WHERE TABLE_SCHEMA NOT IN {5} AND TABLE_TYPE=''BASE TABLE'' " +
"ORDER BY {1} LIMIT ? OFFSET ?",
TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT, CREATE_TIME, UPDATE_TIME, excludeSchema);
play.Logger.info(sql);
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
PreparedStatement ps = connection.prepareStatement(sql)) {
ps.setInt(1, limit);
ps.setInt(2, offset);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
// TableInfo 是一個POJO
TableInfo tableInfo = new TableInfo();
tableInfo.schema = resultSet.getString(TABLE_SCHEMA);
tableInfo.tableComment = resultSet.getString(TABLE_COMMENT);
tableInfo.tableName = resultSet.getString(TABLE_NAME);
Date createTime = resultSet.getDate(CREATE_TIME);
tableInfo.createTime = createTime != null ? createTime.getTime() : -1;
Date updateTime = resultSet.getDate(UPDATE_TIME);
tableInfo.updateTime = updateTime != null ? updateTime.getTime() : tableInfo.createTime;
tableProperties.add(tableInfo.toMap());
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableProperties;
}
}GBaseTableInfoUtil.java
GBase資料庫的處理。
本來對GBase這個資料庫一點都不瞭解,後來在網上找了它的使用手冊之後,發現對它的處理跟MYSQL是一樣的。
public class GBaseTableInfoUtil extends MySQLTableInfoUtil {
public GBaseTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
}
@Override
protected SourceType getSourceType() {
return SourceType.GBASE;
}
}OracleTableInfoUtil.java
Oracle 資料庫的處理。
public class OracleTableInfoUtil extends AbstractDBTableInfoUtil {
private static final String OWNER = "OWNER";
private static final String TABLE_NAME = "TABLE_NAME";
private static final String COMMENTS = "COMMENTS";
private static final String CREATED = "CREATED";
private static final String LAST_DDL_TIME = "LAST_DDL_TIME";
private static final String EXCLUDE_SCHEMA_PREFIX_APEX = "'APEX%'";
private static final String EXCLUDE_TABLESPACE_PREFIX_SYSTEM = "'SYS%'";
public OracleTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
// Oracle的系統 schema 非常多,無法列全,此處是根據我自己的oracle中已經存在的 系統schema 進行列舉的
excludeSchema = "" +
"('ANONYMOUS', 'APPQOSSYS', 'AUDSYS', 'CTXSYS', 'DBSNMP', 'DIP', 'DVF', 'DVSYS', " +
"'FLOWS_FILES', 'GSMADMIN_INTERNAL', 'GSMCATUSER', 'GSMUSER', " +
"'LBACSYS', 'MDDATA', 'MDSYS', 'MGMT_VIEW', 'OJVMSYS', " +
"'OLAPSYS', 'ORACLE_OCM', 'ORDDATA', 'ORDPLUGINS', 'ORDSYS', " +
"'OUTLN', 'OWBSYS', 'OWBSYS_AUDIT', 'SCOTT', 'SI_INFORMTN_SCHEMA', " +
"'SPATIAL_CSW_ADMIN_USR', 'SPATIAL_WFS_ADMIN_USR', 'SYS', 'SYSBACKUP', " +
"'SYSDG', 'SYSKM', 'SYSMAN', 'SYSTEM', 'WMSYS', 'XDB', 'XS$NULL')";
}
@Override
protected SourceType getSourceType() {
return SourceType.ORACLE;
}
@Override
protected String getTableCountSQL() {
// 大家可以注意一下,這裡我還加了兩個限制條件
// 1. OWNER NOT LIKE 'APEX%'
// 2. TABLESPACE_NAME NOT LIKE 'SYS%'
// 這兩個條件都是為了過濾 系統schema 的
String sql = MessageFormat.format("SELECT COUNT(1) FROM ALL_TABLES WHERE OWNER NOT IN {0} AND OWNER NOT LIKE {1} AND TABLESPACE_NAME NOT LIKE {2}",
excludeSchema, EXCLUDE_SCHEMA_PREFIX_APEX, EXCLUDE_TABLESPACE_PREFIX_SYSTEM);
play.Logger.info(sql);
return sql;
}
@Override
protected List getTableInfoList(final BiDataSource dataSource, final int pageSize, final int pageNumber) {
List tableProperties = new ArrayList();
final int start = (pageNumber - 1) * pageSize + 1;
final int end = start + pageSize;
// oracle 的相關資訊需要從幾張表中關聯得出
// 1. ALL_TABLES
// 2. ALL_OBJECTS
// 3. USER_TAB_COMMENTS
// 另外,請注意一下 Oracle 的分頁方式。其中,為了讓結果按 TABLE_NAME排序,我們必須做一個子查詢,否則,分頁出來的結果可能不是你想要的
String sql = MessageFormat.format(
"" +
"SELECT " +
" * " +
"FROM " +
" (" +
" SELECT " +
" AT.*, UTC.{2} {2}, AO.{3} {3}, AO.{4} {4}, ROWNUM RN" +
" FROM" +
" (" +
" SELECT" +
" {0}, {1}" +
" FROM" +
" ALL_TABLES" +
" WHERE" +
" OWNER NOT IN {5}" +
" AND" +
" OWNER NOT LIKE {6}" +
" AND" +
" TABLESPACE_NAME NOT LIKE {7}" +
" ORDER BY {1}" +
" ) AT" +
" LEFT JOIN" +
" ALL_OBJECTS AO" +
" ON" +
" AT.OWNER=AO.OWNER" +
" AND" +
" AT.TABLE_NAME=AO.OBJECT_NAME" +
" LEFT JOIN" +
" USER_TAB_COMMENTS UTC" +
" ON" +
" AO.OBJECT_NAME=UTC.TABLE_NAME" +
" WHERE" +
" ROWNUM<?" +
" ) " +
"WHERE" +
" RN>=?",
OWNER, TABLE_NAME, COMMENTS, CREATED, LAST_DDL_TIME, excludeSchema, EXCLUDE_SCHEMA_PREFIX_APEX, EXCLUDE_TABLESPACE_PREFIX_SYSTEM);
play.Logger.info(sql);
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
PreparedStatement ps = connection.prepareStatement(sql)) {
ps.setInt(1, end);
ps.setInt(2, start);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
TableInfo tableInfo = new TableInfo();
tableInfo.schema = resultSet.getString(OWNER);
tableInfo.tableName = resultSet.getString(TABLE_NAME);
tableInfo.tableComment = resultSet.getString(COMMENTS);
Date createTime = resultSet.getDate(CREATED);
tableInfo.createTime = createTime != null ? createTime.getTime() : -1;
Date updateTime = resultSet.getDate(LAST_DDL_TIME);
tableInfo.updateTime = updateTime != null ? updateTime.getTime() : tableInfo.createTime;
tableProperties.add(tableInfo.toMap());
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableProperties;
}
}DB2TableInfoUtil.java
DB2資料庫的處理。
public class DB2TableInfoUtil extends AbstractDBTableInfoUtil {
private static final String TABSCHEMA = "TABSCHEMA";
private static final String TABNAME = "TABNAME";
private static final String REMARKS = "REMARKS";
private static final String CREATE_TIME = "CREATE_TIME";
private static final String STATS_TIME = "STATS_TIME";
private static final String ALTER_TIME = "ALTER_TIME";
public DB2TableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
// 系統 schema
excludeSchema = "('SYSCAT', 'SYSIBM', 'SYSIBMADM', 'SYSPUBLIC', 'SYSSTAT', 'SYSTOOLS')";
}
@Override
protected SourceType getSourceType() {
return SourceType.DB2;
}
@Override
protected String getTableCountSQL() {
// 從 SYSCAT.TABLES 表中可以得到想要的結果
String sql = MessageFormat.format("SELECT COUNT(1) FROM SYSCAT.TABLES WHERE TABSCHEMA NOT IN {0} AND TYPE = ''T''", excludeSchema);
play.Logger.info(sql);
return sql;
}
@Override
protected List getTableInfoList(final BiDataSource dataSource, final int pageSize, final int pageNumber) {
List tableProperties = new ArrayList();
final int start = (pageNumber - 1) * pageSize;
final int end = start + pageSize;
// DB2 的分頁方式與 Oracle 的類似。而且,為了排序,也需要先做一個 子查詢
String sql = MessageFormat.format(
"" +
"SELECT " +
" TAB.* " +
"FROM " +
" (" +
" SELECT " +
" T.*, ROWNUMBER() OVER() AS ROW_NUMBER " +
" FROM" +
" (" +
" SELECT" +
" {0}, {1}, {2}, {3}, {4}, {5}" +
" FROM" +
" SYSCAT.TABLES" +
" WHERE" +
" TABSCHEMA NOT IN {6}" +
" AND" +
" TYPE=''T''" +
" ORDER BY {1}" +
" ) AS T" +
" ) TAB " +
"WHERE" +
" TAB.ROW_NUMBER>?" +
" AND" +
" TAB.ROW_NUMBER<=?",
TABSCHEMA, TABNAME, REMARKS, CREATE_TIME, STATS_TIME, ALTER_TIME, excludeSchema);
play.Logger.info(sql);
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
PreparedStatement ps = connection.prepareStatement(sql)) {
ps.setInt(1, start);
ps.setInt(2, end);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
TableInfo tableInfo = new TableInfo();
tableInfo.schema = resultSet.getString(TABSCHEMA);
tableInfo.tableName = resultSet.getString(TABNAME);
tableInfo.tableComment = resultSet.getString(REMARKS);
Date createTime = resultSet.getDate(CREATE_TIME);
tableInfo.createTime = createTime != null ? createTime.getTime() : -1;
Date statsTime = resultSet.getDate(STATS_TIME);
Date alterTime = resultSet.getDate(ALTER_TIME);
tableInfo.updateTime = (statsTime != null ? statsTime.getTime() : (alterTime != null ? alterTime.getTime() : tableInfo.createTime));
tableProperties.add(tableInfo.toMap());
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableProperties;
}
}GreenPlumTableInfoUtil.java
Greenplum資料庫的處理。
Greenplum是基於 postgresql 的。
這個是我調查時間最長的一個數據庫。
它的 CREATE_TIME 和 UPDATE_TIME 沒有專門的表來記錄,表的註釋還需要通過內建函式來獲取。
public class GreenPlumTableInfoUtil extends AbstractDBTableInfoUtil {
private static final String TABLE_CATALOG = "TABLE_CATALOG";
private static final String TABLE_SCHEMA = "TABLE_SCHEMA";
private static final String TABLE_NAME = "TABLE_NAME";
private static final String CREATE_TIME = "CREATE_TIME";
private static final String UPDATE_TIME = "UPDATE_TIME";
private static final String TABLE_COMMENT = "TABLE_COMMENT";
public GreenPlumTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
// 系統 schema
excludeSchema = "('information_schema', 'pg_catalog', 'gp_toolkit')";
}
@Override
protected SourceType getSourceType() {
return SourceType.GREENPLUM;
}
@Override
protected String getTableCountSQL() {
String sql = MessageFormat.format("SELECT COUNT(1) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA NOT IN {0} AND TABLE_TYPE=''BASE TABLE''", excludeSchema);
play.Logger.info(sql);
return sql;
}
@Override
protected List getTableInfoList(final BiDataSource dataSource, final int pageSize, final int pageNumber) {
List tableProperties = new ArrayList();
final int offset = (pageNumber - 1) * pageSize;
final int limit = pageSize;
// 三個表通過 pg_class 表中的 OID 欄位進行關關聯
// 請特別注意一下 INFORMATION_SCHEMA.TABLES 是如何來計算OID的
// 也請注意一下,表的註釋 是通過 OBJ_DESCRIPTION() 這個內建函式來獲取的
String sql = MessageFormat.format("" +
"SELECT" +
" T.{0}, T.{1}, T.{2}, OBJ_DESCRIPTION(C.OID) AS \"{3}\", MIN(O.STATIME) AS \"{4}\", MAX(O.STATIME) AS \"{5}\" " +
"FROM" +
" INFORMATION_SCHEMA.TABLES AS T" +
" LEFT JOIN" +
" PG_CLASS AS C" +
" ON" +
" C.OID=(T.{1}||''.''||T.{2})::REGCLASS" +
" LEFT JOIN" +
" PG_STAT_LAST_OPERATION AS O" +
" ON" +
" C.OID=O.OBJID " +
"WHERE" +
" TABLE_SCHEMA NOT IN {6}" +
" AND" +
" TABLE_TYPE=''BASE TABLE'' " +
"GROUP BY" +
" T.{0}, T.{1}, T.{2}, \"{3}\" " +
"ORDER BY {2} " +
"LIMIT ? OFFSET ?",
TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT, CREATE_TIME, UPDATE_TIME, excludeSchema);
play.Logger.info(sql);
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
PreparedStatement ps = connection.prepareStatement(sql)) {
ps.setInt(2, offset);
ps.setInt(1, limit);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
TableInfo tableInfo = new TableInfo();
tableInfo.tableComment = resultSet.getString(TABLE_COMMENT);
tableInfo.schema = resultSet.getString(TABLE_SCHEMA);
tableInfo.tableName = resultSet.getString(TABLE_NAME);
Date createTime = resultSet.getDate(CREATE_TIME);
tableInfo.createTime = createTime != null ? createTime.getTime() : -1;
Date updateTime = resultSet.getDate(UPDATE_TIME);
tableInfo.updateTime = updateTime != null ? updateTime.getTime() : tableInfo.createTime;
tableProperties.add(tableInfo.toMap());
}
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
}
return tableProperties;
}
}HiveTableInfoUtil.java
Hive倉庫的處理。
對Hive的調查時間也很長。
它跟其它資料庫不一樣,因為它的 jdbc url 是連線hive的,而 hive 本身還有一個 meta store (即 元資料 的資料庫),這個meta store 我們是無法連線到的。這就導致了,我們無法像其它資料庫那樣,可以通過類似 information_schema.tables 類來獲取 table一覽。所以,我進行了變通,先通過 AbstractDBTableInfoUtil 類中的 getSchemas() 方法來獲取所有的 schema,然後,呼叫 AbstractDBTableInfoUtil 類中的 getTables() 遍歷這些 schema,獲取它們對應的所有表
public class HiveTableInfoUtil extends AbstractDBTableInfoUtil {
private static final String COL_NAME = "col_name";
private static final String DATA_TYPE = "data_type";
private static final String COMMENT = "comment";
private static final String CREATE_TIME = "CreateTime:";
private static final String TABLE_PARAMETERS = "Table Parameters:";
private static final String TABLE_PARAMETERS_COMMENT = "comment";
private static final String TABLE_PARAMETERS_TRANSIENT_LAST_DDL_TIME = "transient_lastDdlTime";
private static final String DATE_FORMAT = "EEE MMM dd HH:mm:ss z yyyy";
public HiveTableInfoUtil(final BiDataSource dataSource) {
super(dataSource);
}
@Override
protected SourceType getSourceType() {
return SourceType.HIVE;
}
@Override
public int getTableCount(final BiDataSource dataSource) {
// 先獲取所有 schema,再獲取每個 schema 的所有 table
List<Pair<String, String>> tables = getTables(dataSource, getSchemas(dataSource));
return tables.size();
}
@Override
protected String getTableCountSQL() {
return null;
}
@Override
protected List getTableInfoList(final BiDataSource dataSource, final int pageSize, final int pageNumber) {
// 先獲取所有 schema,再獲取每個 schema 的所有 table
List<Pair<String, String>> allTables = getTables(dataSource, getSchemas(dataSource));
// 因為無法通過 SQL 進行分頁,所以,只好手動分頁
final int start = (pageNumber - 1) * pageSize;
final int end = start + pageSize;
List<Pair<String, String>> targetTables = allTables.subList((start < 0 ? 0 : start), (end > allTables.size() ? allTables.size() : end));
// 對於 分頁 中的每個table獲取相關資訊
List<TableInfo> tableProperties = getTableInfo(dataSource, targetTables);
return tableProperties;
}
private List<TableInfo> getTableInfo(final BiDataSource dataSource, final List<Pair<String, String>> tables) {
List<TableInfo> tableInfoList = new ArrayList<>();
try (Connection connection = DriverManager.getConnection(dataSource.url, dataSource.username, dataSource.password);
Statement ps = connection.createStatement()) {
for (Pair<String, String> table : tables) {
TableInfo tableInfo = getInitTableInfo(table);
String sql = MessageFormat.format("DESC FORMATTED {0}.{1}", table.getKey(), table.getValue());
play.Logger.info(sql);
ResultSet resultSet = ps.executeQuery(sql);
String col_name;
String data_type;
boolean tableParamPresented = false;
// 對於 Hive 的表的結構資訊的解析
// 下方給出了一個 "desc formatted xxxHiveTable" 語句返回的樣例
// 這裡的解析邏輯就是根據這個樣例來進行的
while (resultSet.next()) {
col_name = resolveNull(resultSet.getString(COL_NAME));
data_type = resolveNull(resultSet.getString(DATA_TYPE));
if (CREATE_TIME.equalsIgnoreCase(col_name)) {
tableInfo.createTime = getCreateTime(data_type);
}
if (TABLE_PARAMETERS.equalsIgnoreCase(col_name)) {
tableParamPresented = true;
}
if (tableParamPresented && TABLE_PARAMETERS_COMMENT.equalsIgnoreCase(data_type)) {
tableInfo.tableComment = resolveNull(resultSet.getString(COMMENT));
}
if (tableParamPresented && TABLE_PARAMETERS_TRANSIENT_LAST_DDL_TIME.equalsIgnoreCase(data_type)) {
tableInfo.updateTime = getUpdateTime(resolveNull(resultSet.getString(COMMENT)));
}
}
if (tableInfo.updateTime == -1) {
tableInfo.updateTime = tableInfo.createTime;
}
tableInfoList.add(tableInfo);
}
} catch (SQLException e) {
play.Logger.error(e.getMessage(), e);
}
return tableInfoList;
}
private TableInfo getInitTableInfo(Pair<String, String> table) {
TableInfo tableInfo = new TableInfo();
tableInfo.schema = table.getKey();
tableInfo.tableName = table.getValue();
// set init value
tableInfo.createTime = -1;
tableInfo.updateTime = -1;
tableInfo.tableComment = null;
return tableInfo;
}
private String resolveNull(final String str) {
return (str == null ? "" : str.trim());
}
/*
* create time is sth.like 'Wed Mar 01 10:47:12 CST 2017'
*/
@SuppressWarnings("deprecation")
private long getCreateTime(String createTime) {
Date date;
try {
date = new SimpleDateFormat(DATE_FORMAT, Locale.US).parse(createTime);
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
try {
date = new Date(createTime);
} catch (Exception e1) {
date = new Date(-1);
}
}
return date.getTime();
}
/*
* update time is sth. like '1486978518',
* this is UNIX time stamp, we need to append '000' to change it.
*/
private long getUpdateTime(String updateTime) throws SQLException {
long update;
try {
update = Long.parseLong(updateTime + "000");
} catch (Exception e) {
play.Logger.error(e.getMessage(), e);
update = -1;
}
return update;
}
}“desc formatted test123;” 的返回值
相關推薦
針對不同資料庫,獲取當前使用者所有有許可權檢視的表,以及表的建立時間、更新時間、註釋等資訊,表中欄位的相關資訊(包含分頁實現)
最近在處理一個需求,需求是這樣的:
給定任意一個數據庫的JDBC連線、使用者名稱、密碼
查詢出所有有許可權訪問的表的相關資訊:表名,建立時間,更新時間,註釋
要支援分頁
資料庫型別有:MySQL、GBase、Oracle、DB2、Greenplum、Hive
獲取應用版本號,版本名稱,包名,AppName,圖標,是否是系統應用,獲取手機中所有應用,所有進程
pac version raw 是否 系統 app bsp agen nco PackageManager packageManager = getPackageManager();
PackageInfo packageInfo; = packageManager.get
MiniUI前臺分頁,假分頁實現源碼
MiniUI 假分頁背景對於數據較少,無需後臺分頁的需求,可使用以下解決方案方案MiniUI提供了監聽事件,特別方便即可實現。源碼mini.parse();
var grid = mini.get("datagridTable");
// 獲取所有數據和總記錄數 { tot
31、分頁實現——資料庫的分頁
學習目標:
1、掌握資料庫分頁演算法
2、掌握不同資料庫之間分頁演算法的不同點
學習過程:
今天的另外一個重要內容就是分頁顯示列表。現在我們在頁面上面看到的使用者列表都是全部資訊,資訊量少當然沒有問題,但是一般資料裡都會幾百或者上萬條,每次都全部顯示是不可能的,所以我們必須分頁顯示。
單純用寫的表格,分頁實現
1、html:
<div id="tableList">
<table class="table table-bordered table-striped table-hover" id="rgtable1" style="color:#444
easyui中的分頁實現(支援MySQL,SQLServer,Oracle)
package com.dxwind.common.bean;
import java.sql.CallableStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLExcept
java反射,獲取類物件所有成員變數,從字串呼叫函式
//import java.lang.reflect.Field;
/** 獲取Object物件,所有成員變數屬性值 */
public static void getObjAttr(Object obj)
{
// 獲取物件obj的所有屬性域
Field[] fiel
基於spring boot架構和word分詞器的分詞檢索,排序,分頁實現
本文不適合Java初學者,適合對spring boot有一定了解的同學。 文中可能涉及到一些實體類、dao類、工具類文中沒有這些類大家不必在意,不影響本文的核心內容,本文重在對方法的梳理。 word分詞器maven依賴<dependency>
java 分頁匯出百萬級資料到excel,分頁實現
最近修改了一個匯出員工培訓課程的歷史記錄(一年資料),匯出功能本來就有的,不過前臺做了時間限制(只能選擇一個月時間內的),還有一些必選條件, 匯出的資料非常有侷限性。心想:為什麼要做出這麼多條件限制呢?條件限制無所謂了,能限制匯出資料的準確性,但是時間? 如果我想匯出一年的資料,還要一月一月的去匯出,這也太扯
針對不同資料庫實現日期格式化
若想把在不同資料庫拿出來的各種日期轉換成不同的格式的話,參考以下做法:
資料庫中的資料是以System.currentTimeMillis();的方式存進去的。
MySQL:Date_format(FROM_UNIXTIME(create_time / 1000),'%
Spring分頁實現PageImpl<T>類
sea equals public ini ack format contain link 部分 Spring框架中PageImpl<T>類的源碼如下:
/*
* Copyright 2008-2013 the original author or aut
symfony分頁實現方法
ont param creat com render 實現 使用 ext urn 1.symfony分頁是要用到組件的,所以這裏使用KnpPaginatorBundle實現翻頁
2. 用composer下載
在命令行中: composer require "
S/4HANA和CRM Fiori應用的搜索分頁實現
odata .com 加載 aging alt -o gen rip adl 在我的博客Paging Implementation in S/4HANA for Customer Management 我介紹了S/4HANA for Customer Management裏
Smarty的分頁實現
inside fetch 數據 etc ber page arr quest vars Smarty中的分頁有很多方法。1。使用Smarty的分頁插件,如Pager,pagnition,sliding_page等,不過感覺都不是太好,幾乎都有一些Bug。有興趣試用和自己去改
Laravel 手動分頁實現
else spa path http java 處理 inf RR laravel Laravel 手動分頁實現
基於5.2版本
在開發過程中有這麽一種情況,你請求Java api獲取信息,由於信息較多,需要分頁顯示。Laravel官方提供了一個簡單的方式paginat
Display Tag的分頁實現
Display Tag Lib是一個標籤庫,用來處理jsp網頁上的Table,功能非常強,可以對的Table進行分頁、資料匯出、分組、對列排序等等,能夠大大減少程式碼量。 這個是Display Tag的官方網站http://displaytag.sourceforge.net。 首先當然是要
織夢欄目分頁實現前十頁後十頁
欄目分頁前十頁後十頁
實現教程
開啟 /include/arc.listview.class.php 找到
$prepage.="<li><a href='".$purl."PageNo=$prepagenum'>上一頁</a></li>\r\n";
MyBatis學習——第五篇(手動分頁和pagehelper分頁實現)
1:專案場景介紹
在專案中分頁是十分常見的功能,一般使用外掛實現分頁功能,但是在使用外掛之前我們首先手動寫出分頁程式碼,發然對比外掛實現的分頁,利於我們理解分頁底層實現和更好的實現外掛分頁實用技術,本次使用的外掛是PageHelper(採用都是物理分頁)
在開始之前我們建立兩個表,分別是t_
MyBatis學習——第四篇(攔截器和攔截器分頁實現)
MyBatis架構體圖
1:mybatis核心物件
從MyBatis程式碼實現的角度來看,MyBatis的主要的核心部件有以下幾個:
SqlSession &n
ajax前端分頁實現
本來不打算重複造輪子的,網上也已經有了很多關於前端分頁的框架,外掛等等,但是還是打算寫出來是因為前段時間有一個功能模組需要用到前端分頁,然後找了很多框架,以及外掛,發現其內容非常的複雜或者有的乾脆就是不能用的,一氣之下就準備自己動手寫一個,下面貼出程式碼。。
到自己寫的時候其實發現,這個還是挺簡單的,邏輯程