
《Matrix capsules with EM Routing》新膠囊網路
本文介紹了Hinton的第二篇膠囊網路論文“Matrix capsules with EM Routing”,其作者分別為Geoffrey E Hinton、Sara Sabour和Nicholas Frosst。我們首先討論矩陣膠囊並應用EM(期望最大化)路由對不同角度的影象進行分類。對於那些想了解具體實現的讀者,本文的第二部分是一個關於矩陣膠囊和EM路由的tensorflow實現。
CNN所面臨的挑戰
在上一篇關於膠囊的文章中,我們提到了CNN在探索空間關係中面臨的挑戰,並討論了膠囊網路如何解決這些問題。讓我們回顧一下CNN在分類相同型別但不同角度的影象時所面臨的一些重要的挑戰。例如,正確地分類不同的方向的人臉。
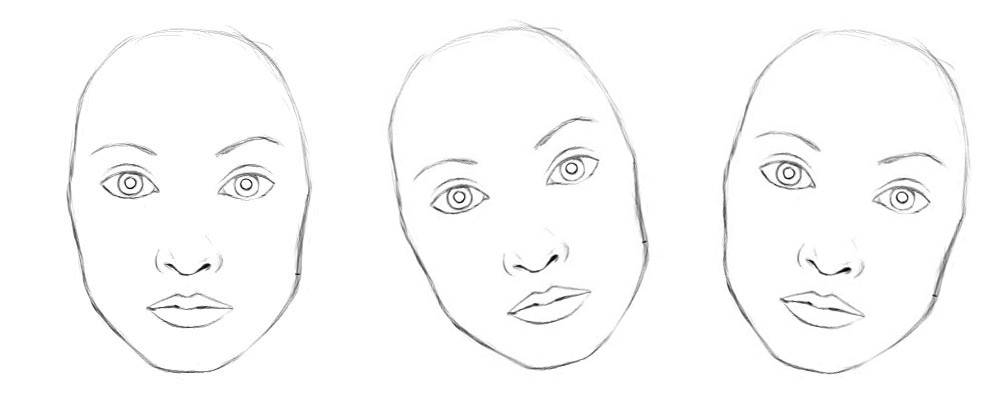
從概念上講,CNN需要訓練多個神經元來處理不同的特徵方向(0°,20°,20°),並用一個頂層的人臉檢測神經元檢測人臉。
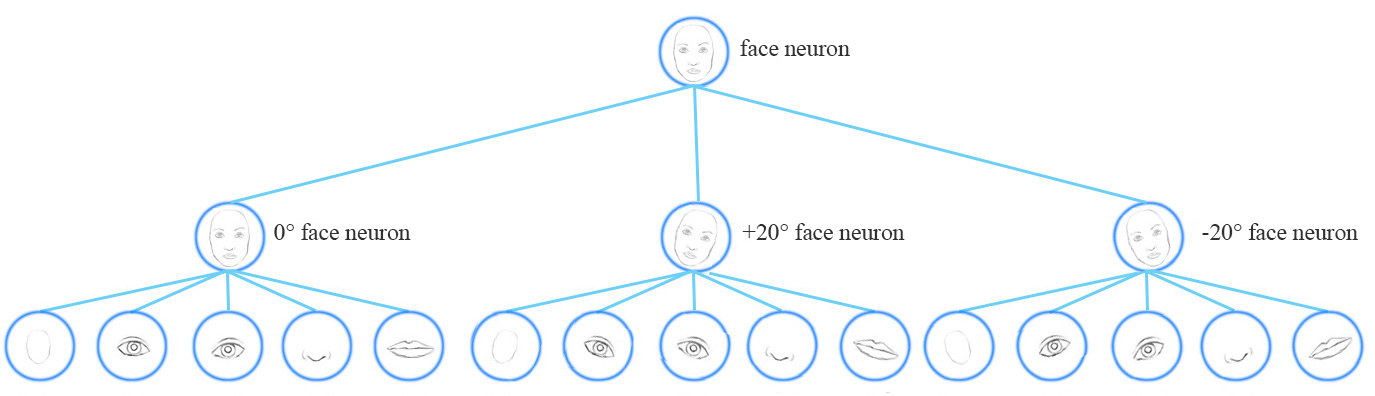
為了解決這個問題,我們添加了更多的卷積層和特徵對映。然而,這種方法傾向於記住資料集,而不是概括解決方案。它需要大量的訓練資料,去覆蓋不同的變體以及避免過擬合。MNIST資料集包含55000個訓練資料,每個數字有5500個樣本。然而,小孩子們根本不需要這麼多樣本來學習數字識別。我們現有的深度學習模型,包括CNN,在利用資料上都顯得非常低效。
對抗攻擊
對於將個別特徵進行簡單的移動,旋轉或大小調整的對抗樣本,CNN顯得非常脆弱。
我們可以對影象新增微小的不可見的更改,從而輕鬆地欺騙一個深層神經網路。左邊的圖片被CNN正確地歸類為熊貓。通過選擇性地從中間圖片向熊貓圖片中新增微小的變化,CNN居然把右邊的合成影象歸類為長臂猿。
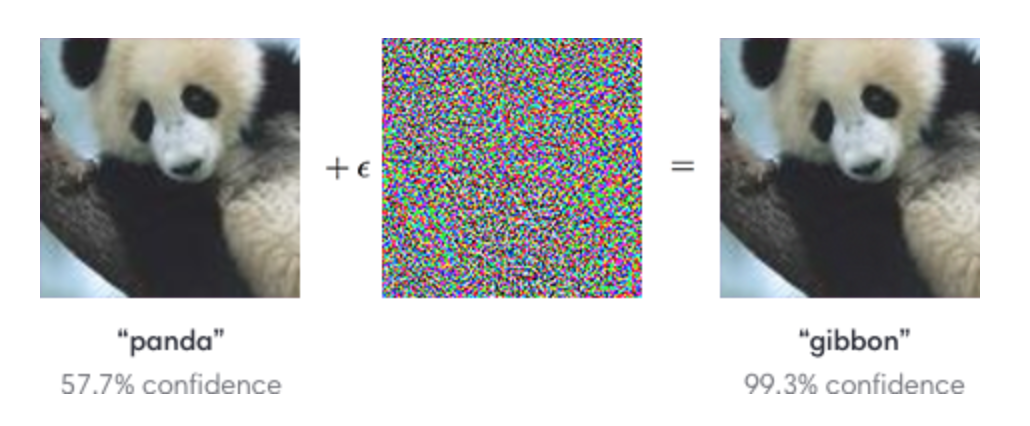
(圖片來自OpenAI)
膠囊
一個膠囊能夠捕捉特徵的可能性及其變體。因此,膠囊不僅能檢測到特徵,還能通過訓練來學習和檢測變體。
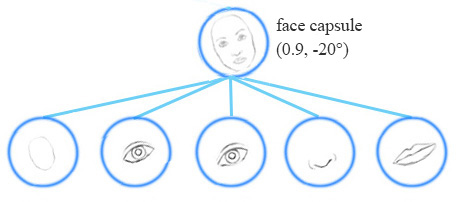
例如,同一網路層可以檢測順時針旋轉的面部。
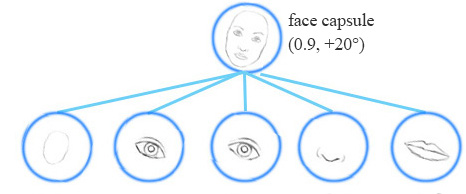
同變性是可以相互變換的物件的檢測。直觀地說,一個膠囊檢測到臉右旋轉20°(或左旋轉20°),並不是通過匹配一個右旋轉20°的變體來識別到臉部。通過迫使模型在膠囊中學習特徵變數,我們可以用較少的訓練資料更有效地推斷可能的變體。在CNN中,最終的標籤是視角不變的,即頂層神經元檢測到一個人臉,但丟失了旋轉角度資訊。對於同變性來說,像旋轉角度這類變化的資訊被儲存在膠囊裡面。保留這些空間方向的資訊可以幫助我們避免對抗樣本攻擊。
矩陣膠囊
一個矩陣膠囊同神經元一樣可以捕捉啟用(可能性),但也捕捉到了一個4x4的姿態矩陣。在計算機圖形學中,一個姿態矩陣定義了一個物體的平移和旋轉,它相當於一個物體的視角的變化。
(圖片來源於論文Matrix capsules with EM routing)
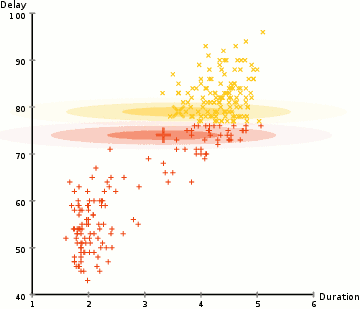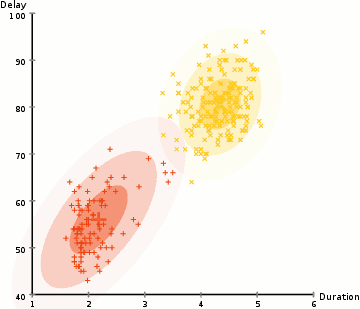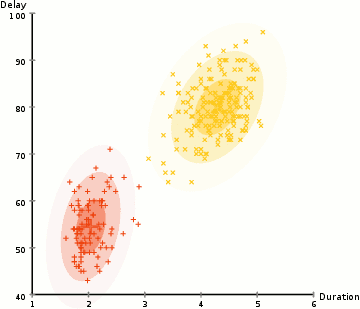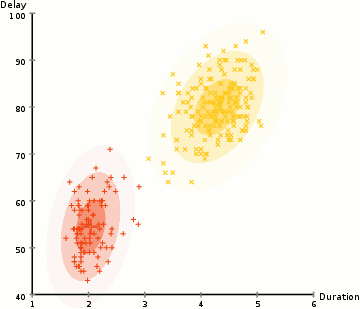
例如,下面的第二行影象代表上面同一物件的不同視角。在矩陣膠囊中,我們訓練模型來捕捉姿態資訊(方向、方位角等)。當然,就像其他深度學習方法一樣,這僅僅是我們的意圖,並不能得到保證。

(圖片來源於論文Matrix capsules with EM routing)
EM(期望最大化)路由的目的是通過使用聚類技術(EM)將膠囊分組形成一個部分-整體關係。在機器學習中,我們使用EM聚類簇將資料點聚類為高斯分佈。例如,我們通過兩個高斯分佈G1=N(μ1,σ12)” role=”presentation” style=”position: relative;”>G1=N(μ1,σ21)G1=N(μ1,σ12)建模,將下面的資料聚類為兩簇。然後我們用對應的高斯分佈來表示資料點。
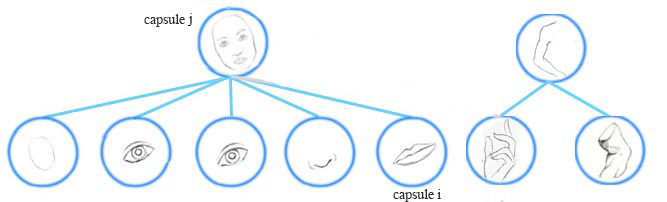
在人臉檢測這個示例中,低層中每一個嘴巴、眼睛和鼻子的檢測膠囊都對其可能的父膠囊的姿態矩陣進行預測(投票)。每個投票都是父膠囊的姿態矩陣的一個預測值,它通過將自己的姿態矩陣乘以訓練得到的變換矩陣W” role=”presentation” style=”position: relative;”>WW來計算。
v=MW” role=”presentation”>v=MWv=MW
我們將在執行時使用EM路由,將膠囊分組到父膠囊中:
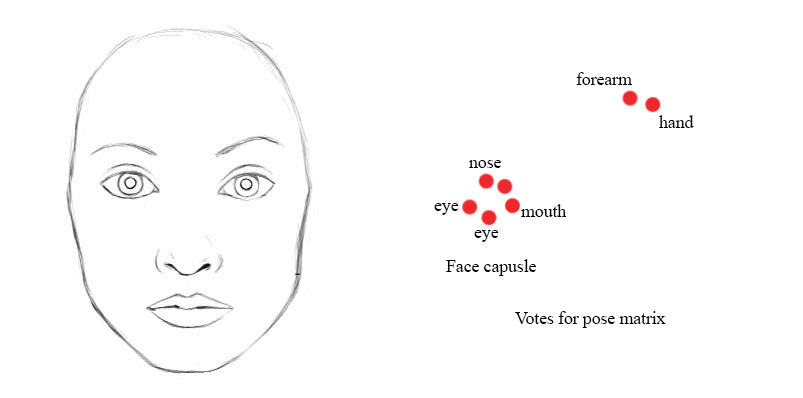
例如,如果鼻子,嘴和眼睛膠囊都有一個相似的姿態矩陣值的投票,那麼我們將他們聚集在一起形成父膠囊:人臉膠囊。
A higher level feature (a face) is detected by looking for agreement between votes from the capsules one layer below. We use EM routing to cluster capsules that have close proximity of the corresponding votes.
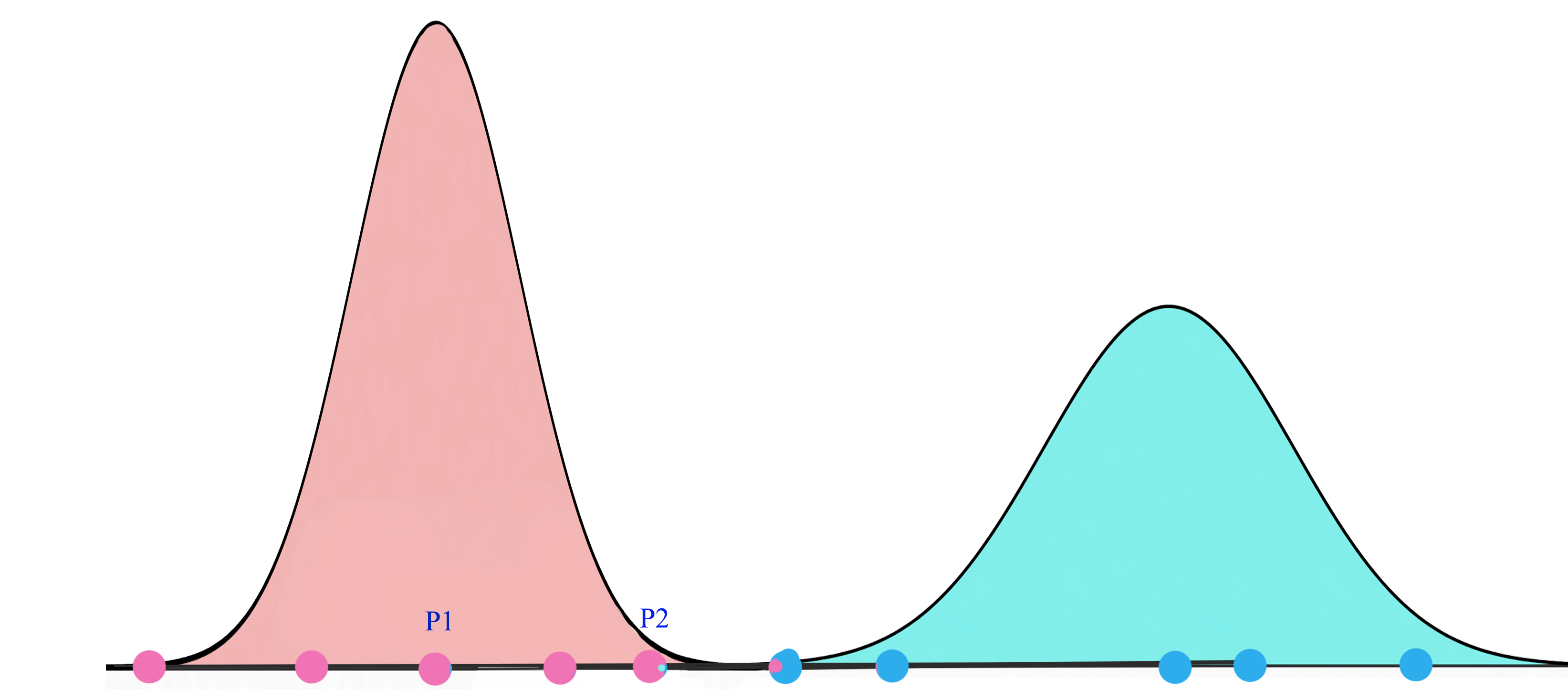
高斯混合模型 & 期望最大化(EM)
我們先來了解一下EM。高斯混合模型將資料點聚類為混合高斯分佈,由均值μ” role=”presentation” style=”position: relative;”>μμ描述。
(圖片來源於Wikipedia)
對於一個兩叢集的高斯混合模型,我們先隨機的初始化叢集G1=(μ1,σ12)” role=”presentation” style=”position: relative;”>G1=(μ1,σ21)G1=(μ1,σ12)分佈下,看到所有的資料點的概率最大化。
在給定集合G1” role=”presentation” style=”position: relative;”>G1G1的概率為:
在每次迭代中,我們開始於2個高斯分佈,之後會根據資料點重新計算其μ” role=”presentation” style=”position: relative;”>μμ。
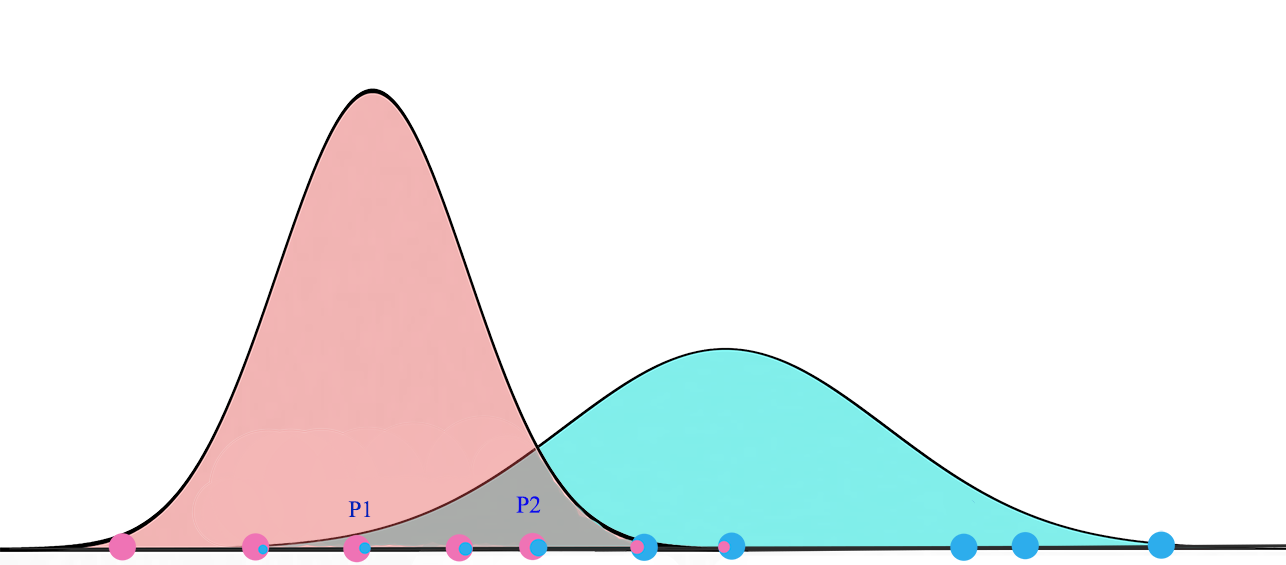
最終,我們會收斂到兩個高斯分佈,它使觀察到的資料點的似然最大化。
使用EM進行協議路由(Routing-By-Agreement)
現在,我們探討更多的細節。一個更高層次的特徵(一張臉)通過尋找來自下一層膠囊的投票的協商被檢測到。一個從膠囊i” role=”presentation” style=”position: relative;”>ii計算得到。
一個膠囊i” role=”presentation” style=”position: relative;”>ii通過成本函式和反向傳播學到。它不僅學習了人臉的組成,而且能夠保證在經過變換後父膠囊與其子元件的姿態資訊匹配。
下面是矩陣膠囊的協議路由(Routing-By-Agreement)的視覺化圖。姿態矩陣Ti” role=”presentation” style=”position: relative;”>TiTi)
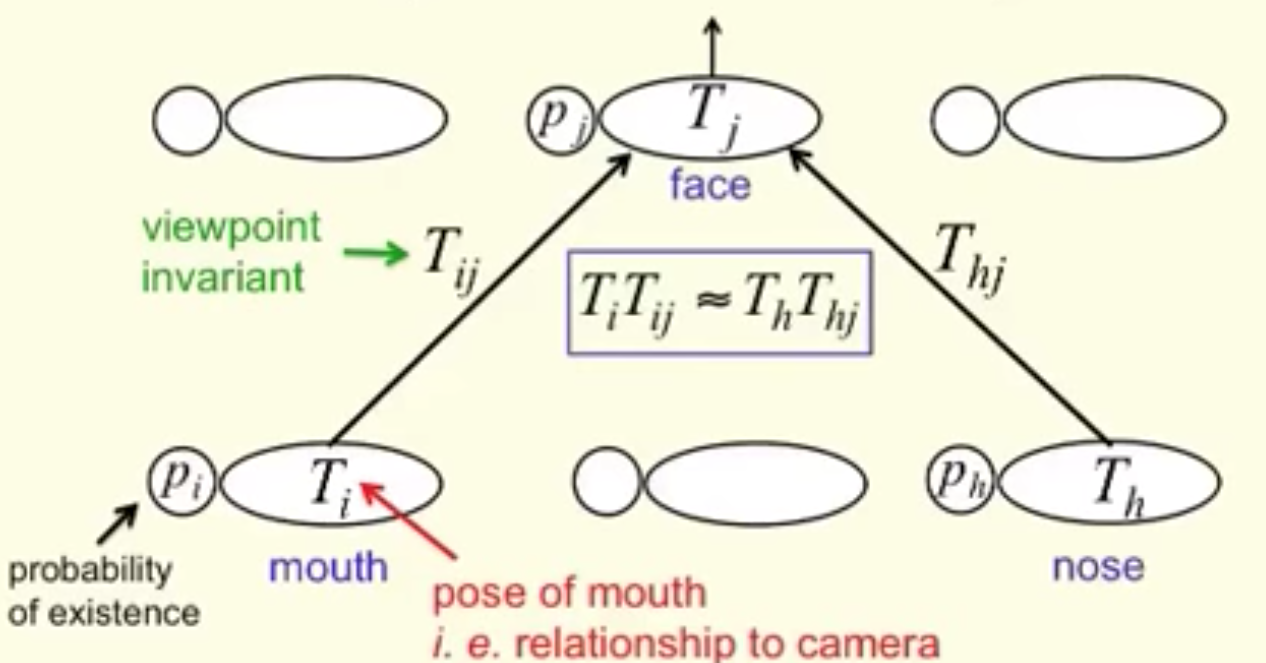
(圖片來源於Geoffrey Hinton)
即使視角改變,姿態矩陣和投票也會以協調的方式變化。在我們的例子中,當臉部旋轉時,選票的位置可能會從紅色點變為粉紅色點。然而,EM路由是基於鄰近度的,它仍然可以將相同的子膠囊聚集在一起。因此,變換矩陣對於物體的任何視角都是相同的:視角不變性。用於物件的不同方向,我們只需要一組轉換矩陣和一個父膠囊。

膠囊分配
EM路由在執行時將膠囊分組形成一個更高級別的膠囊。它同時會計算分配概率rij” role=”presentation” style=”position: relative;”>rijrij也將是零。
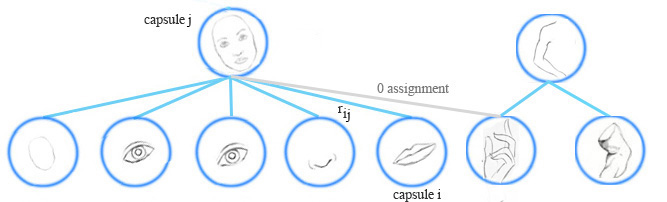
計算膠囊的啟用值和姿態矩陣
膠囊輸出的計算不同於深度網路的神經元。在EM聚類中,我們通過高斯分佈來表示資料點。在EM路由中,我們仍用高斯模型對父膠囊的姿態矩陣進行建模。姿態矩陣是一個4×4矩陣,即16個元素。我們用具有16個μ” role=”presentation” style=”position: relative;”>μμ表示姿態矩陣的一個元素。
令vij” role=”presentation” style=”position: relative;”>vijvij個元素。我們應用高斯概率密度函式:
來計算vijh” role=”presentation” style=”position: relative;”>vhijvijh的高斯模型的概率:
pi|jh=12π(σjh)2exp(−(vijh−μjh)22(σjh)2)” role=”presentation”>phi|j=12π(σhj)2−−−−−−√exp(−(vhij−μhj)22(σhj)2)pi|jh=12π(σjh)2exp(−(vijh−μjh)22(σjh)2)
取自然對數:
ln(pi|jh)=ln12π(σjh)2exp(−(vijh−μjh)22(σjh)2)=−ln(σjh)−ln(2π)2−(vijh−μjh)22(σjh)2” role=”presentation” style=”position: relative;”>ln(phi|j)=ln12π(σhj)2−−−−−−√exp(−(vhij−μhj)22(σhj)2)=−ln(σhj)−ln(2π)2−(vhij−μhj)22(σhj)2ln(pi|jh)=ln12π(σjh)2exp(−(vijh−μjh)22(σjh)2)=−ln(σjh)−ln(2π)2−(vijh−μjh)22(σjh)2\rm{ln}(p^h_{i|j})=ln\frac{1}{\sqrt{2\pi(\sigma^h_j)^2}}\rm {exp}(-\frac{(v^h_{ij}-\mu^h_{j})^2}{2(\sigma ^h_j)^2}) \\
我們估算一下啟用一個膠囊的成本。成本越低,膠囊就越有可能被啟用。如果成本高,投票就不匹配父高斯分佈,因此被啟用的概率就越低。
令costij” role=”presentation” style=”position: relative;”>costijcostij的成本,它是對數似然取負:
由於低層的膠囊與膠囊j” role=”presentation” style=”position: relative;”>jj按比例計算成本。所有下層膠囊的成本為:
costjh=∑irijcostijh=∑i−rijln(pi|jh)=∑irij((vijh−μjh)22(σjh)2+ln(σjh)+ln(2π)2)=∑irij(σjh)22(σjh)2+(ln(σjh)+ln(2π)2)∑irij=(ln(σjh)+k)∑irij其中k为常量” role=”presentation” style=”position: relative;”>costhj=∑irijcosthij=∑i−rijln(phi|j)=∑irij((vhij−μhj)22(σhj)2+ln(σhj)+ln(2π)2)=∑irij(σhj)22(σhj)2+(ln(σhj)+ln(2π)2)∑irij=(ln(σhj)+k)∑irij其中k為常量costjh=∑irijcostijh=∑i−rijln(pi|jh)=∑irij((vijh−μjh)22(σjh)2+ln(σjh)+ln(2π)2)=∑irij(σjh)22(σjh)2+(ln(σjh)+ln(2π)2)∑irij=(ln(σjh)+k)∑irij其中k為常量cost_{j}^h=\sum_i r_{ij}cost_{ij}^h \\ =\sum_i -r_{ij}ln(p^h_{i|j}) \\ =\sum_i r_{ij}(\frac{(v^h_{ij}-\mu^h_j)^2}{2(\sigma^h_j)^2}+ln(\sigma^h_{j})+\frac{ln(2\pi)}{2}) \\ =\frac{\sum_i r_{ij}(\sigma^h_j)^2}{2(\sigma^h_j)^2}+(ln(\sigma^h_j)+\frac{ln(2\pi)}{2})\sum_ir_{ij} \\
我們用下面的公式來確定膠囊j” role=”presentation” style=”position: relative;”>jj是否會被啟用:
aj=sigmoid(λ(bj−∑hcostjh))” role=”presentation”>aj=sigmoid(λ(bj−∑hcosthj))aj=sigmoid(λ(bj−∑hcostjh))
原文中,“−bij” role=”presentation” style=”position: relative;”>−bij−bij。相反,我們通過反向傳播和成本函式來訓練它。
rij” role=”presentation” style=”position: relative;”>rijrij首先被初始化為1,然後每次路由迭代後增加1。論文並沒有說明細節,我們建議在實現中採用不同的方案進行試驗。
EM路由
利用EM路由迭代計算出姿態矩陣和輸出膠囊的啟用值。EM法交替地呼叫步驟E和步驟M,將資料點擬合到混合高斯模型 。步驟E確定父膠囊每個資料點分配的概率rij” role=”presentation” style=”position: relative;”>rijrij將構成父膠囊的4×4姿態矩陣。
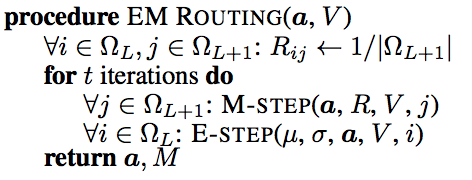
(圖片來源於論文Matrix capsules with EM routing)
上面的a” role=”presentation” style=”position: relative;”>aa。
步驟M的細節:
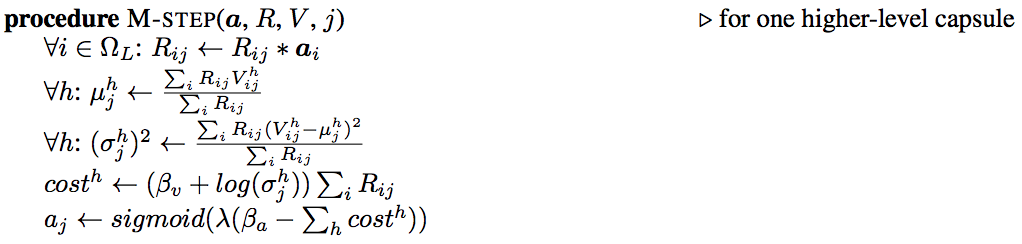
在步驟M中,我們計算μ” role=”presentation” style=”position: relative;”>μμ(溫度引數的倒數)增加1。
步驟E的細節:
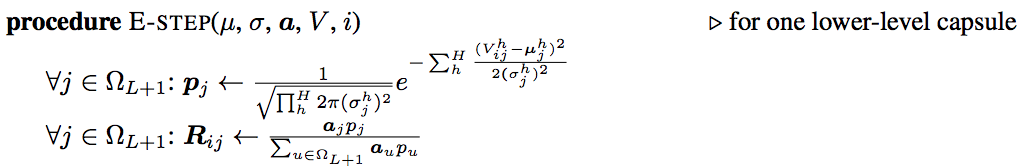
步驟E中,我們基於新的μ” role=”presentation” style=”position: relative;”>μμ,分配則增加。
We use the aj” role=”presentation” style=”position: relative;”>ajaj to form the 4x4 pose matrix.
反向傳播與EM路由的角色
在CNN中,我們用下面公式計算一個神經元的啟用值:
然而,一個膠囊的輸出,包括啟用值和姿態矩陣,是通過EM路由計算得到的。我們使用EM路由計算父膠囊的輸出,基於變換矩陣W” role=”presentation” style=”position: relative;”>WW。
在EM路由中,我們通過計算分配概率rij” role=”presentation” style=”position: relative;”>rijrij來量化子膠囊和父膠囊之間的連線。這個值很重要,但生命週期短暫。我們在EM路由計算前為每一個數據點使用均勻分佈重新將它初始化。在任何情況,無論訓練或測試,我們使用EM路由計算膠囊的輸出。
損失函式(使用Spread損失)
矩陣膠囊需要一個損失函式來訓練W” role=”presentation” style=”position: relative;”>WW)的損失被定義為:
at” role=”presentation” style=”position: relative;”>
相關推薦
《Matrix capsules with EM Routing》新膠囊網路
本文介紹了Hinton的第二篇膠囊網路論文“Matrix capsules with EM Routing”,其作者分別為Geoffrey E Hinton、Sara Sabour和Nicholas Frosst。我們首先討論矩陣膠囊並應用EM(期望最大化)路由對不同角度的影
Matrix Capsule with EM Routing
摘要capsule 是一組神經元,其輸出可表徵同一個實體的不同性質。我們描述了一種 capsule 版本,其中每個 capsule 都有一個 logistic 單元(用來表示一個實體的存在)和一個 4×4 的姿態矩陣(pose matrix)(可以學習表徵該實體與觀看者之間的
學習筆記《Dynamic Routing Between Capsules》-(“膠囊”網路之區域性空間關係)
喜歡才能持久,熱愛才會盡心! 0 前言 昨天的面試官講了利用自動駕駛鐳射雷達資料探測路上行人、車輛問題的區域性空間關係的見解,提到了Vector向量多方位,多角度問題,我感覺和Capsule裡的Ve
Hinton膠囊網路論文《Dynamic Routing between Capsules》的程式碼正式開源
執行測試驗證設定是否正確,例如: python layers_test.py 快速MNIST測試結果: 從以下網址下載並提取MNIST記錄到 $DATA_DIR/:https://s
關於矩陣膠囊與EM路由的理解(基於Hinton的膠囊網路)
本文介紹了Hinton的第二篇膠囊網路論文“Matrix capsules with EM Routing”,其作者分別為Geoffrey E Hinton、Sara Sabour和Nicholas Frosst。我們首先討論矩陣膠囊並應用EM(期望最大化)路由
曲速未來 警惕:新的網路釣魚活動將Ursnif放入對話執行緒中
區塊鏈安全諮詢公司 曲速未來 訊息:於今年9月發現的一項新的網路釣魚活動顯示,運營商越來越複雜,他們接管電子郵件帳戶並在對話執行緒中插入銀行木馬。 惡意軟體是對現有討論的回覆,這是一種強大的社會工程方法,可以保證很高的成功率,因為它
Investigating Capsule Networks with Dynamic Routing for Text Classification
探索使用動態路由的膠囊網路進行文字分類,提出三種策略穩定動態路由來減輕噪音膠囊的分佈,這些膠囊可能包含背景資訊,或是訓練不好。膠囊網路獲得很好的分類效果,而且訓練多標籤的效果好於單標籤 1 Introduction 文章或是句子建模是NLP的基礎問題,如果組成,層次,結構都考慮的話,很是複雜
北京網站建設哪家公司好?北京新起點網路專業的網站建設推廣公司
整站優化與單純的關鍵詞優化的不同。整站優化除了考慮排名外,更注重點選率和網站轉換率。它並不以北京網站建設推廣某個關鍵詞在某個搜尋引擎上的排名為得失,而是注重所有高質量相關關鍵詞在所有搜尋引擎的整體表現。整站優化比關鍵詞競價更有效。與關鍵詞競價不同,北京網站建設推廣哪家好?整站優化可以讓貴網站通過更多的高質量關
膠囊網路的簡單介紹
原文:https://kndrck.co/posts/capsule_networks_explained/ 預修知識:卷積神經網路,變分自編碼器 免責宣告:本文不涉及膠囊網路背後的數學,而是說一下它們背後的直覺和動機。 什麼是膠囊網路?為什麼要使用膠囊網路? 膠囊網路是 Ge
keras 處理文字,分類,數值資料,並新增進網路的步驟和方法
一,讀取資料: 主要使用pandas 讀取,以後考慮使用其他方法(libsvm等) 二,獲取訓練集和測試集: 這一步主要是劃分資料集,drop()掉訓練集裡的預測那一列 三,處理缺失值: 可以使用fillna(value,inplace)來把缺失值補全 四:送入網
強強聯合!螞蟻金服與新炬網路戰略合作,共同致力於國產資料庫的技術推廣和生態建設
小螞蟻說: 螞蟻金服攜手新炬網路將從資料庫專案實施 、升級遷移和整體運維服務
軍犬輿情:新時代網路輿情的特點及輿情監測的有效舉措
隨著網際網路和自媒體的爆發,讓網路輿情的發展進入到全新的時代,人人都是小喇叭,每個人都可以成為網路輿論的傳播者,網路輿情的發生、傳播和形態變得越來越多元化,對於網路輿情的監測和管理也顯得越來越重要。 網路輿情是社會輿情在網際網路空間的對映,是社會輿情全新的反映方式。關於網路
Docker釋出新的網路專案,並開始招聘中國區主管
5月1日,Docker釋出了自家的容器網路管理專案 libnetwork,libnetwork使用Go語言編寫,目標是定義一個容器網路模型(CNM),併為應用程式提供一致的程式設計介面以及網路抽象。目前libnetwork仍在全力開發中,並沒有達到使用標準。
介紹膠囊網路 capsule networks
CNN與CapsNets比較 CNN要麼需要大量圖片來訓練,要麼需要複用訓練好的CNN網路來填充當前網路的某些層。而膠囊網路,只需要少量圖片就可以訓練 對於元素豐富的圖片,CNN不能很好地處理模稜兩可的邊界。而CapsNets即使在擁擠的場景下,也能表現
關於膠囊之間的動態路由的理解(基於Hinton的膠囊網路)
本文介紹了由Sara Sabour,Nicholas Frosst和Geoffrey Hinton所著的論文“膠囊之間的動態路由”。在這篇文章中,我們將描述膠囊的基本概念,並應用膠囊網路(capsnet)檢測MNIST資料集中的數字。在本文最後的第三部分中,我們
Capsule 膠囊網路學習筆記
以前鄒班的SMT沒認真聽,還得重新回來撿。 CNN的缺點: 忽略了圖片中的位置資訊,如果在圖片中檢測到眼睛鼻子等,就認為這是一張人臉,但如果把這些器官打亂,還是會誤識別為人臉,這是CNN中max pooling的特性造成的。 如上圖所示,我們通俗的
看完這篇,別說你還不懂Hinton大神的膠囊網路,capsule network
倒計時 2 天 來源 | 王的機器(公眾號ID:MeanMachine1031) 作者 | 王聖元 0 引言 斯蒂文認為機器學習有時候像嬰兒學習,特別是在物體識別上。比如嬰兒首先學會識別邊界和顏色,然後將這些資訊用於識別形狀和圖形等更復雜的實體。比如在人臉識別上
膠囊網路(Capsule Network)的TensorFlow實現
現在我們都知道Geoffrey Hinton的膠囊網路(Capsule Network)震動了整個人工智慧領域,它將卷積神經網路(CNN)的極限推到一個新的水平。 網上已經有很多的帖子、文章和研究論文在探討膠囊網路理論,以及它如何做的比傳統的CNN更好。因此
卷及網路的弱點,有人想用膠囊網路給解決掉
大家好,我是為人造的智慧操碎了心的智慧禪師。今天轉載的文章,來自譯智社的小夥伴。這是一群來自全國
膠囊網路架構
介紹本文將介紹CapsNet的體系結構,我同時嘗試計算CapsNet的可訓練引數數目。結果是大約820萬可訓練引數,與論文中的數字(113萬6千)不同。論文字身不是很詳細,沒有涉及一些網路實現的具體設定,因此有一些問題我至今沒有搞清楚(論文作者沒有提供程式碼)。不管怎麼說,我