
膠囊網路架構
介紹
本文將介紹CapsNet的體系結構,我同時嘗試計算CapsNet的可訓練引數數目。結果是大約820萬可訓練引數,與論文中的數字(113萬6千)不同。論文字身不是很詳細,沒有涉及一些網路實現的具體設定,因此有一些問題我至今沒有搞清楚(論文作者沒有提供程式碼)。不管怎麼說,我仍然認為計算網路的引數本身是一個很好的學習過程,因為它幫助人們理解特定架構的所有構建模組。
CapsNet由兩部分組成:編碼器和解碼器。前3層是編碼器,後3層是解碼器:
- 第一層:卷積層
- 第二層:PrimaryCaps(主膠囊)層
- 第三層:DigitCaps(數字膠囊)層
- 第四層:第一全連線層
- 第五層:第二全連線層
- 第六層:第三全連線層
第一部分 編碼器
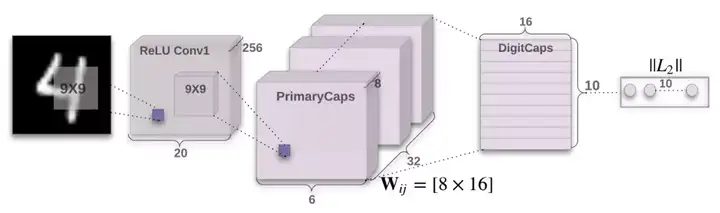 CapsNet編碼器架構,圖片來源:原論文
CapsNet編碼器架構,圖片來源:原論文上圖中,網路的編碼器部分接受一張28x28的MNIST數字影象作為輸入,學習將它編碼為由例項引數構成的16維向量(本系列前面幾篇文章解釋了這一過程),這也是膠囊進行工作的所在。預測輸出是由DigitCaps輸出的長度構成的10維向量。
第一層 卷積層
輸入:28x28影象(單色)
輸出:20x20x256張量
引數:20992
卷積層檢測2D影象的基本特徵。在CapsNet中,卷積層有256個步長為1的9x9x1核,使用ReLU啟用。如果你不明白這句話是什麼意思,這裡有一些很棒的資源讓你快速掌握卷積背後的關鍵概念。計算引數時,別忘了卷積層中的每個核有1個偏置項。因此這一層共有(9x9+1)x256 = 20992個可訓練引數。
第二層 PrimaryCaps層
輸入:20x20x256張量
輸出:6x6x8x32張量
引數:5308672
這一層包含32個主膠囊,接受卷積層檢測到的基本特徵,生成特徵的組合。這一層的32個主膠囊本質上和卷積層很相似。每個膠囊將8個9x9x256卷積核應用到20x20x256輸入張量,因而生成6x6x8輸出張量。由於總共有32個膠囊,輸出為6x6x8x32張量。這一層共有5308672個可訓練引數(計算過程與上一層類似)。
第三層 DigitCaps層
輸入:6x6x8x32張量
輸出:16x10矩陣
引數:1497600
這一層包含10個數字膠囊,每個膠囊對應一個數字。每個膠囊接受一個6x6x8x32張量作為輸入。你可以把它看成6x6x32的8維向量,也就是1152輸入向量。在膠囊內部,每個輸入向量通過8x16權重矩陣將8維輸入空間對映到16維膠囊輸出空間。因此,每個膠囊有1152矩陣,以及用於動態路由的1152 c係數和1152 b係數。乘一下:1152 x 8 x 16 + 1152 + 1152,每個膠囊有149760可訓練引數,乘以10得到這一層最終的引數數目。
損失函式
損失函式乍一看很複雜,但實際上並非如此。 它與SVM損失函式很像。回想一下,DigitCaps層的輸出是10個16維向量,這有助於理解損失函式是如何工作的。訓練時,對於每個訓練樣本,根據下面的公式計算每個向量的損失值,然後將10個損失值相加得到最終損失。我們正在討論監督學習,所以每個訓練樣本都有正確的標籤,在這種情況下,它將是一個10維one-hot編碼向量,該向量由9個零和1個一(正確位置)組成。在損失函式公式中,正確的標籤決定了Tc的值:如果正確的標籤與特定DigitCap的數字對應,Tc為1,否則為0。
 給原論文中的公式加上色彩
給原論文中的公式加上色彩假設正確的標籤是1,這意味著第一個DigitCap負責編碼數字1的存在。這一DigitCap的損失函式的Tc為1,其餘9個DigitCap的Tc為0。當Tc為1時,損失函式的第二項為零,損失函式的值通過第一項計算。在我們的例子中,為了計算第一個DigitCap的損失,我們從m+減去這一DigitCap的輸出向量,其中,m+取固定值0.9。接著,我們保留所得值(僅當所得值大於零時)並取平方。否則,返回0。換句話說,當正確DigitCap預測正確標籤的概率大於0.9時,損失函式為零,當概率小於0.9時,損失函式不為零。
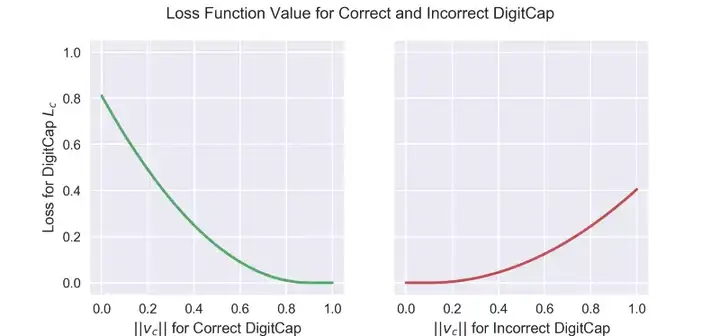 正確與不正確DigitCap的損失函式的值。注意,紅線沒有綠線那麼陡峭,這是由於等式中的lambda係數
正確與不正確DigitCap的損失函式的值。注意,紅線沒有綠線那麼陡峭,這是由於等式中的lambda係數對不匹配正確標籤的DigitCap而言,Tc為零,因此將演算第二項。在這一情形下,DigitCap預測不正確標籤的概率小於0.1時,損失函式為零,預測不正確標籤的概率大於0.1時,損失函式不為零。
最後,公式包括了一個lambda係數以確保訓練中的數值穩定性(lambda為固定值0.5)。這兩項取平方是為了讓損失函式符合L2正則,看起來作者們認為這樣正則化一下效果更好。
第二部分 解碼器
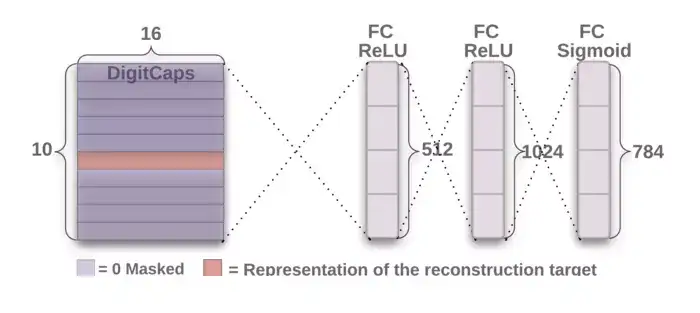 CapsNet解碼器架構,來源:原論文
CapsNet解碼器架構,來源:原論文解碼器從正確的DigitCap中接受一個16維向量,並學習將其解碼為數字影象(請注意,它在訓練時僅使用正確的DigitCap向量,忽略不正確的DigitCap)。解碼器被用來作為正則子,它接受正確的DigitCap的輸出作為輸入,並學習重建一張28×28畫素的影象,損失函式為重建影象與輸入影象之間的歐氏距離。解碼器強制膠囊學習對重建原始影象有用的特徵。重建影象越接近輸入影象越好。下圖展示了一些重建影象的例子。
 上為原始影象,下為重建影象。來源:原論文
上為原始影象,下為重建影象。來源:原論文第四層 第一全連線層
輸入:16x10
輸出:512
引數:82432
低層的每個輸出加權後傳導至全連線層的每個神經元作為輸入。每個神經元同時具備一個偏置項。16x10輸入全部傳導至這一層的512個神經元中的每個神經元。因此,共有(16x10 + 1)x512可訓練引數。
以下兩層的計算與此類似:引數數量 = (輸入數 + 偏置) x 層中的神經元數。
第五層 第二全連線層
輸入:512
輸出:1024
引數:525312
第六層 第三全連線層
輸入:1024
輸出:784(重整後重建28x28解碼影象)
引數:803600
網路中的引數總數:8238608
轉自知乎:https://zhuanlan.zhihu.com/p/33955995