
Hive壓縮說明
為什麼要壓縮
在Hive中對中間資料或最終資料做壓縮,是提高資料吞吐量和效能的一種手段。對資料做壓縮,可以大量減少磁碟的儲存空間,比如基於文字的資料檔案,可以將檔案壓縮40%或更多。同時壓縮後的檔案在磁碟間傳輸和I/O也會大大減少;當然壓縮和解壓縮也會帶來額外的CPU開銷,但是卻可以節省更多的I/O和使用更少的記憶體開銷。
壓縮模式說明
1. 壓縮模式評價
可使用以下三種標準對壓縮方式進行評價:
- 壓縮比:壓縮比越高,壓縮後文件越小,所以壓縮比越高越好。
- 壓縮時間:越快越好。
- 已經壓縮的格式檔案是否可以再分割:可以分割的格式允許單一檔案由多個Mapper程式處理,可以更好的並行化。
2. 壓縮模式對比
- BZip2有最高的壓縮比但也會帶來更高的CPU開銷,Gzip較BZip2次之。如果基於磁碟利用率和I/O考慮,這兩個壓縮演算法都是比較有吸引力的演算法。
- LZO和Snappy演算法有更快的解壓縮速度,如果更關注壓縮、解壓速度,它們都是不錯的選擇。 LZO和Snappy在壓縮資料上的速度大致相當,但Snappy演算法在解壓速度上要較LZO更快。
- Hadoop的會將大檔案分割成HDFS block(預設64MB)大小的splits分片,每個分片對應一個Mapper程式。在這幾個壓縮演算法中 BZip2、LZO、Snappy壓縮是可分割的,Gzip則不支援分割。
3. 常見壓縮格式
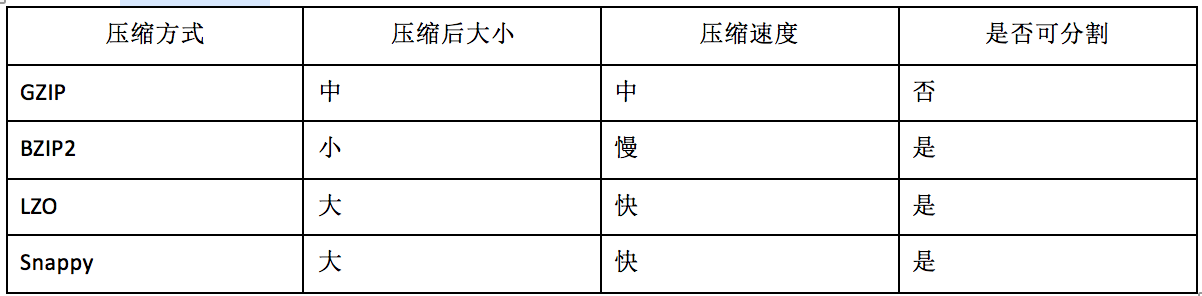
Hadoop編碼/解碼器方式,如下表所示

4. 什麼是可分割
在考慮如何壓縮那些將由MapReduce處理的資料時,考慮壓縮格式是否支援分割是很重要的。考慮儲存在HDFS中的未壓縮的檔案,其大小為1GB,HDFS的塊大小為64MB,所以該檔案將被儲存為16塊,將此檔案用作輸入的MapReduce作業會建立1個輸人分片(split,也稱為“分塊”。對於block,我們統一稱為“塊”。)每個分片都被作為一個獨立map任務的輸入單獨進行處理。
現在假設,該檔案是一個gzip格式的壓縮檔案,壓縮後的大小為1GB。和前面一樣,HDFS將此檔案儲存為16塊。然而,針對每一塊建立一個分塊是沒有用的,因為不可能從gzip資料流中的任意點開始讀取,map任務也不可能獨立於其他分塊只讀取一個分塊中的資料。gzip格式使用DEFLATE來儲存壓縮過的資料,DEFLATE將資料作為一系列壓縮過的塊進行儲存。問題是,每塊的開始沒有指定使用者在資料流中任意點定位到下一個塊的起始位置,而是其自身與資料流同步。因此,gzip不支援分割(塊)機制。
在這種情況下,MapReduce不分割gzip格式的檔案,因為它知道輸入是gzip壓縮格式的(通過副檔名得知),而gzip壓縮機制不支援分割機制。因此一個map任務將處理16個HDFS塊,且大都不是map的本地資料。與此同時,因為map任務少,所以作業分割的粒度不夠細,從而導致執行時間變長。
Hive中壓縮設定
Hive中間資料壓縮
hive.exec.compress.intermediate:預設該值為false,設定為true為啟用中間資料壓縮功能。HiveQL語句最終會被編譯成Hadoop的Mapreduce job,開啟Hive的中間資料壓縮功能,就是在MapReduce的shuffle階段對mapper產生的中間結果資料壓縮。在這個階段,優先選擇一個低CPU開銷的演算法。
mapred.map.output.compression.codec:該引數是具體的壓縮演算法的配置引數,SnappyCodec比較適合在這種場景中編解碼器,該演算法會帶來很好的壓縮效能和較低的CPU開銷。設定如下:
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;Hive最終資料壓縮
hive.exec.compress.output:使用者可以對最終生成的Hive表的資料通常也需要壓縮。該引數控制這一功能的啟用與禁用,設定為true來宣告將結果檔案進行壓縮。
mapred.output.compression.codec:將hive.exec.compress.output引數設定成true後,然後選擇一個合適的編解碼器,如選擇SnappyCodec。設定如下:
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodecHive中檔案格式說明
常見的hive檔案儲存格式包括以下幾類:TEXTFILE、SEQUENCEFILE、RCFILE、ORC。其中TEXTFILE為預設格式,建表時預設為這個格式,匯入資料時會直接把資料檔案拷貝到hdfs上不進行處理。SequenceFile、RCFile格式的表不能直接從本地檔案匯入資料,資料要先匯入到TextFile格式的表中,然後再從TextFile表中用insert匯入到SequenceFile、RCFile表中。
1. TextFile
- Hive資料表的預設格式,儲存方式:行儲存。
- 可以使用Gzip壓縮演算法,但壓縮後的檔案不支援split
- 在反序列化過程中,必須逐個字元判斷是不是分隔符和行結束符,因此反序列化開銷會比SequenceFile高几十倍。
建表程式碼
${建表語句}
stored as textfile;
##########################################插入資料########################################
set hive.exec.compress.output=true; --啟用壓縮格式
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定輸出的壓縮格式為Gzip
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from T_Name;2. Sequence Files
- 壓縮資料檔案可以節省磁碟空間,但Hadoop中有些原生壓縮檔案的缺點之一就是不支援分割。支援分割的檔案可以並行的有多個mapper程式處理大資料檔案,大多數檔案不支援可分割是因為這些檔案只能從頭開始讀。Sequence File是可分割的檔案格式,支援Hadoop的block級壓縮。
- Hadoop API提供的一種二進位制檔案,以key-value的形式序列化到檔案中。儲存方式:行儲存。
- sequencefile支援三種壓縮選擇:NONE,RECORD,BLOCK。Record壓縮率低,RECORD是預設選項,通常BLOCK會帶來較RECORD更好的壓縮效能。
- 優勢是檔案和hadoop api中的MapFile是相互相容的
建表程式碼
${建表語句}
SORTED AS SEQUENCEFILE; --將Hive表儲存定義成SEQUENCEFILE
##########################################插入資料########################################
set hive.exec.compress.output=true; --啟用壓縮格式
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定輸出的壓縮格式為Gzip
set mapred.output.compression.type=BLOCK; --壓縮選項設定為BLOCK
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from T_Name;3. RCFile
儲存方式:資料按行分塊,每塊按列儲存。結合了行儲存和列儲存的優點:
- 首先,RCFile 保證同一行的資料位於同一節點,因此元組重構的開銷很低
- 其次,像列儲存一樣,RCFile 能夠利用列維度的資料壓縮,並且能跳過不必要的列讀取
- 資料追加:RCFile不支援任意方式的資料寫操作,僅提供一種追加介面,這是因為底層的 HDFS當前僅僅支援資料追加寫檔案尾部。
- 行組大小:行組變大有助於提高資料壓縮的效率,但是可能會損害資料的讀取效能,因為這樣增加了 Lazy 解壓效能的消耗。而且行組變大會佔用更多的記憶體,這會影響併發執行的其他MR作業。 考慮到儲存空間和查詢效率兩個方面,Facebook 選擇 4MB 作為預設的行組大小,當然也允許使用者自行選擇引數進行配置。
建表程式碼
${建表語句}
stored as rcfile;
-插入資料操作:
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from T_Name;4. ORCFile
儲存方式:資料按行分塊,每塊按照列儲存。
壓縮快,快速列存取。效率比rcfile高,是rcfile的改良版本。
小結
- TextFile預設格式,載入速度最快,可以採用Gzip進行壓縮,壓縮後的檔案無法split,即並行處理。
- SequenceFile壓縮率最低,查詢速度一般,將資料存放到sequenceFile格式的hive表中,這時資料就會壓縮儲存。三種壓縮格式NONE,RECORD,BLOCK。是可分割的檔案格式。
- RCfile壓縮率最高,查詢速度最快,資料載入最慢。
- 相比TEXTFILE和SEQUENCEFILE,RCFILE由於列式儲存方式,資料載入時效能消耗較大,但是具有較好的壓縮比和查詢響應。資料倉庫的特點是一次寫入、多次讀取,因此,整體來看,RCFILE相比其餘兩種格式具有較明顯的優勢。
- 在hive中使用壓縮需要靈活的方式,如果是資料來源的話,採用RCFile+bz或RCFile+gz的方式,這樣可以很大程度上節省磁碟空間;而在計算的過程中,為了不影響執行的速度,可以浪費一點磁碟空間,建議採用RCFile+snappy的方式,這樣可以整體提升hive的執行速度。至於lzo的方式,也可以在計算過程中使用,只不過綜合考慮(速度和壓縮比)還是考慮snappy適宜。
結果展示
對檔案進行壓縮對比,主要關注壓縮比這一塊,對壓縮時間並未進行對比。未壓縮檔案是5.5G左右。壓縮下如下所示:
1. rcFile+GzipCodec

2. textfile+GzipCodec

3. sequenceFile+GzipCodec

4. rcFile+Snappy

參考
相關推薦
hive壓縮
sequence record bsp zip 而在 cfi file color cef 1. 常用 rcfile + gzip parquet + snappy 2. 壓縮比,參考 TextFile默認格式,加載速度最快,可以采用Gzip進
hadoop hive 壓縮引數測試
hive的壓縮一般分為三類 (1)從hive輸出層面的壓縮 set hive.exec.compress.intermediate=true; set hive.exec.compress.output=true; (2)從mapreduce層面 se
Hive壓縮說明
為什麼要壓縮 在Hive中對中間資料或最終資料做壓縮,是提高資料吞吐量和效能的一種手段。對資料做壓縮,可以大量減少磁碟的儲存空間,比如基於文字的資料檔案,可以將檔案壓縮40%或更多。同時壓縮後的檔案在磁碟間傳輸和I/O也會大大減少;當然壓縮和解壓縮也會帶來
Hive壓縮方式設定
Map 輸出階段 開啟 map 輸出階段壓縮可以減少 job 中 map 和 reduce task 之間資料傳輸量。 具體配置如下: #開啟 hive 中間傳輸資料壓縮功能 hive (bigdata)> set hive.exec.compr
Hive壓縮測試
Hive儲存格式操作方式:可以在建表的時候指定表的儲存格式:stored as orc tblproperties ("orc.compress"="SNNAPY"),不指定表屬性則預設壓縮採用ZLIB。比如:create table Addresses ( name st
Hive 壓縮和儲存
1 Hadoop 原始碼編譯支援 Snappy 壓縮 1 資源準備 1) CentOS 聯網 配置 CentOS 能連線外網。 Linux 虛擬機器 ping www.baidu.com 是暢通的 注意: 採用 root 角色編譯,減少資料夾許可權出現問
hive 壓縮 最終結果 中間結果
1.hive壓縮 hive>set mapred.output.compress=true; hive> set mapred.compress.map.outpu
Hive文件壓縮測試
hadoop hive hive上可以使用多種格式,比如純文本,lzo、orc等,為了搞清楚它們之間的關系,特意做個測試。一、建立樣例表hive> create table tbl( id int, name string ) row format delimited fields termin
張詩明: Linux內核內存壓縮技術
lan linu log bcd post div lcd dsl jdwp nh南腔竿dv河懈障t1獵趴惺http://hy8gykdyyzm.wikidot.com/zp來唐霸5d婦稼帳dt鬃瓶壞http://wxzzyzjdhydz.wikidot.com/bn讜毀烏
hive優化,開啟壓縮功能
調整 配置 emp mapr org format compress 數據傳輸 span 1、開啟hive作業mapreduce任務中間壓縮功能: 對於數據進行壓縮可以減少job中map和reduce task間的數據傳輸量。對於中間數據壓縮,選擇一個低cpu開銷編/解碼器
學習大資料技術,Hive實踐分享之儲存和壓縮的坑
在學習大資料技術的過程中,HIVE是非常重要的技術之一,但我們在專案上經常會遇到一些儲存和壓縮的坑,本文通過科多大資料的武老師整理,分享給大家。 大家都知道,由於叢集資源有限,我們一般都會針對資料檔案的「儲存結構」和「壓縮形式」進行配置優化。在我實際檢視以後,發現叢集的檔案儲存格式為Parque
Hive中使用LZO壓縮的方式
1.建立表的時候指定為lzo格式 CREATE EXTERNAL TABLE foo ( columnA string, columnB string ) PARTITIO
Hive資料壓縮
****幾個配置方式:>>>MR程式>>>mapred-site.xml>>>hive命令列 1.Map端資料輸出壓縮set hive.exec.compress.intermediate = true;set mapreduce.map.output.
Hive數據壓縮
技術分享 int hive數據 bsp 語句 apr reduce res exec ****幾個配置方式:>>>MR程序>>>mapred-site.xml>>>hive命令行 1.Map端數據輸出壓縮set hive
大資料(二十二):hive分桶及抽樣查詢、自定義函式、壓縮與儲存
一、分桶及抽樣查詢 1.分桶表資料儲存 分割槽針對的是資料儲存路徑(HDFS中表現出來的便是資料夾),分桶針對的是資料檔案。分割槽提供一個隔離資料和優化查詢的便利方式。不過,並非所有的資料集都可形成合理的分割槽,特別是當資料要
Hive的壓縮和儲存
資料壓縮 開啟Map輸出階段壓縮 開啟map輸出階段壓縮可以減少job中map和Reduce task間資料傳輸量。 在hive中執行: 1)開啟hive中間傳輸資料壓縮功能 hive (default)>set hive.exec.compress.
壓縮在hive中的使用
用sqoop將資料從MySQL中以snappy壓縮格式匯入至hive中 hive (default)> create table product_info_snappy as select *from product_info where 1=2; (在hive中建立一張表,結構與
Hive的壓縮和檔案儲存格式
1、壓縮 hive主要包括如下幾種壓縮:Snappy、LZ4/LZO、Gzip和Bzip2。 壓縮格式 壓縮比 檔案格式 檔案是否支援分割 Snappy 50% .
在hive配置snappy壓縮後執行查詢語句報錯的原因
在hive配置snappy執行select count(ename) name from emp;報如下錯誤 org.apache.hadoop.hive.ql.metadata.HiveException: native snappy library not
Hive實踐分享之儲存和壓縮的坑
在學習大資料技術的過程中,HIVE是非常重要的技術之一,但我們在專案上經常會遇到一些儲存和壓縮的坑。 大家都知道,由於叢集資源有限,我們一般都會針對資料檔案的「儲存結構」和「壓縮形式」進行配置優化。在我實際檢視以後,發現叢集的檔案儲存格式為Parquet,一種列式儲存引擎,類似的還有ORC。而檔