
Kaggle 入門級題目titanic資料分析(EDA)嘗試
Titanic: ML from disaster
deal with csv trainning data using pandas etc.
Titanic是kaggle的一個toy級別的入門問題,主要是為了熟悉一下kaggle題目的解題思路,以及用到的處理方法,演算法,以及對應的函式庫的使用。首先,用pandas做資料的讀寫,並且可以大致看一下資料長什麼樣子;然後,用seaborn可以瞭解一下資料的一些統計規律,尤其是各個特徵的分佈情況,為之後選擇何種模型提供一個參考;然後matplotlib可以完成一些比較基本的和底層的視覺化的任務;然後進行建模,可以用scikit-learn,如果用到DL的話,需要考慮tensorflow等;最後進行調參,以及不同模型之間的整合(ensemble),得到最終的結果。
Titanic問題是通過給定船上人員的各種身份資訊,如性別,年齡,姓名,艙位等等,以及是否生還的資訊,希望找到一個合理的模型,或者叫做判據,來對於一個已知身份的人,預測其在這場海難中是否會生還。當然,有這個實際問題來看,其準確率不可能做到1.00,如果做到了,一定是對於這個問題本身過擬合了(overfitting),因為生還與否和每個人的身份,年齡,地位,性別等有一定關係,但是並不是完全由這些因素決定的。我們希望找到一個模型,能夠較大把握的預測生還的機率即可,也就是準確度較高即可。
該問題實際上是一個給定部分可選擇的特徵並且指出特徵的實際含義的情況下的二分類問題。
先看看資料長什麼樣子,對於不方便程式設計處理的做一下預處理,比如填補空缺,或者將字串轉成布林值,以及其他的型別轉換。然後觀察一下統計特徵,先根據經驗選擇要使用的特徵。
import pandas as pd
import numpy as np
import seaborn as sns # 不知道為啥seaborn的簡寫是sns...documentation裡這樣寫就這樣吧
import matplotlib.pyplot as pltpath = './titanic/'
trainset = pd.read_csv( path + 'train.csv')
trainset.describe()trainset.shape
(891, 12)
trainset.head(3)trainset.tail(3)先看一下這些column都是什麼,index在最左邊是標號,一共891個traindata,passengerid就是編號,比index多1,對於特徵無用。survived表示是否生還,0代表死,1代表生。pclass代表票的等級,分別是1,2,3等。 name,sex,age不需要說明。sibsp為 # of siblings / spouses aboard the Titanic,就是兄弟姐妹以及配偶的人數。parch為# of parents / children aboard the Titanic,也就是父母或子女,直系親屬的數量。ticket為票號,fare是票價,cabin是艙位,embarked是登船地點,S,C,Q分別代表三個城市。C = Cherbourg, Q = Queenstown, S = Southampton。
我們先看一下這些資料的分佈,用seaborn直方圖
sns.distplot(trainset['Survived'], kde = False, rug = False)
plt.show()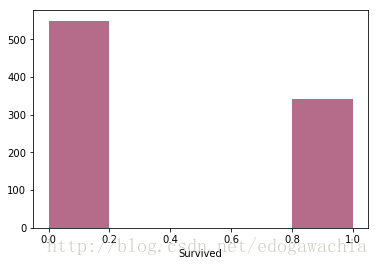
sns.distplot(trainset['Survived'], kde = True, rug = False) # kde set true when we need ratio (pdf approx) instead of real number
# rug set true, then there are small tick at each observation
plt.show() 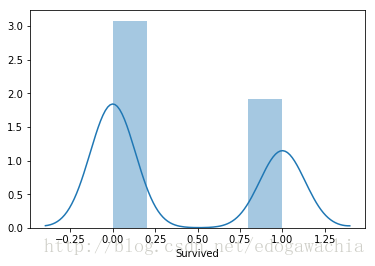
trainset['Survived'].unique()
array([0, 1])svvd = trainset['Survived']
print 'dead : ' + str(len(svvd[svvd == 0])) + ' ' + str(float(len(svvd[svvd == 0]))/len(svvd)*100) + '%'
print 'survived : ' + str(len(svvd[svvd == 1])) + ' ' + str(float(len(svvd[svvd == 1]))/len(svvd)*100) + '%' dead : 549 61.6161616162%
survived : 342 38.3838383838%說明死亡率百分之六十多,也就是說,如果直接全部預測死亡的話,還會有60%左右的準確率。相當於recall達到100%,因為FN=0,假陰性為零,這是顯然的,因為我們的預測中根本沒有陰性,所以不存在真假陰性。但是準確率由於有FP,假陽性,所以大概能夠有60%。這個數值應當作為我們的標準,就是benchmark,因為不需要對特徵進行任何分析,直接考慮需要預測的結果的分佈都能達到這樣的準確率。
trainset.Pclass.unique() # 也可以用成員運算子加上column的名稱,作為成員提取某一列array([3, 1, 2])sns.distplot(trainset.Pclass,kde=False)
plt.show()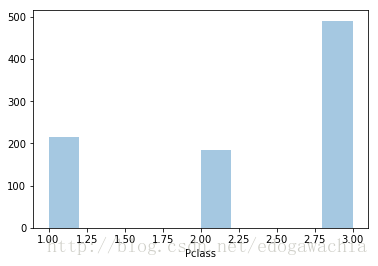
在這891個人中,頭等艙大佬有兩百多,中間的也是兩百左右,吊斯艙有五百左右。
trainset.loc[trainset.Sex == 'male','Sex'] = 0 # loc 定位到sex==‘male’的行,後面表示修改‘sex’column的值
trainset.loc[trainset.Sex == 'female','Sex'] = 1
sns.distplot(trainset.Sex,kde=False)
plt.show()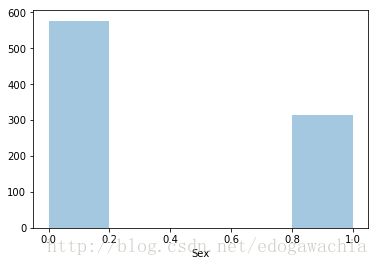
sns.distplot(trainset[trainset.Sex == 0].Age.dropna(),hist = False, color='black', label='male')
sns.distplot(trainset[trainset.Sex == 1].Age.dropna(),hist = False, color='red', label='female')
plt.title('Age versus Class')
plt.show()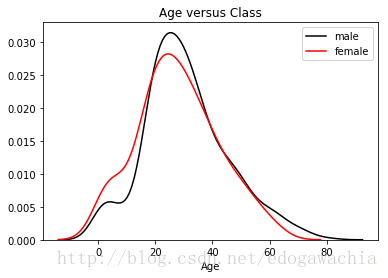
sns.distplot(trainset[trainset.Pclass == 1].Age.dropna(),hist = False, color='blue', label='class 1')
sns.distplot(trainset[trainset.Pclass == 2].Age.dropna(),hist = False, color='green', label='class 2')
sns.distplot(trainset[trainset.Pclass == 3].Age.dropna(),hist = False, color='pink', label='class 3')
plt.title('Age versus Class')
plt.show()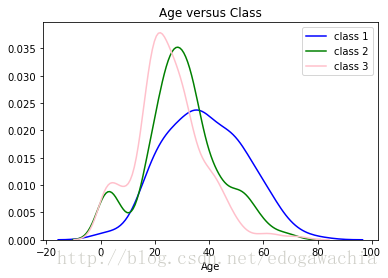
hhh,買得起頭等艙的年齡相對大一些,吊斯們以青年為主。符合我們的認知。
sns.distplot(trainset[trainset.Pclass == 1].Fare.dropna(),hist = False, color='blue', label='class 1')
sns.distplot(trainset[trainset.Pclass == 2].Fare.dropna(),hist = False, color='green', label='class 2')
sns.distplot(trainset[trainset.Pclass == 3].Fare.dropna(),hist = False, color='pink', label='class 3')
plt.title('Fare versus class')
plt.show()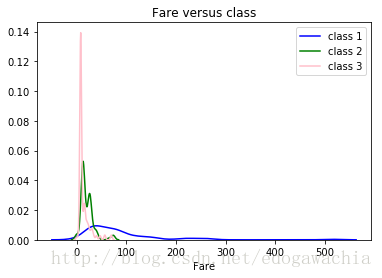
plt.figure()
plt.subplot(121)
sns.distplot(trainset[trainset.Survived == 1].Pclass.dropna(),hist = True, color='blue', label='survived', kde = False)
plt.title('survived')
plt.subplot(122)
sns.distplot(trainset[trainset.Survived == 0].Pclass.dropna(),hist = True, color='red', label='dead', kde = False)
plt.title('dead')
plt.show()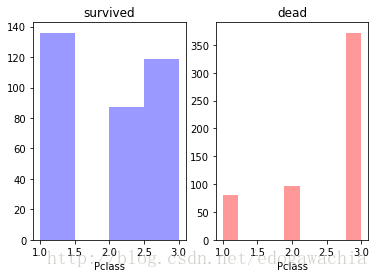
death_number = trainset[trainset.Survived == 0].groupby('Pclass').Survived
alive_number = trainset[trainset.Survived == 1].groupby('Pclass').Survived
death_ratio = death_number.count()/(alive_number.count() + death_number.count())
fig, axes = plt.subplots(1,1,figsize = (5,2),dpi = 100)
axes.bar(range(1,4), death_ratio, width=0.35, facecolor = 'black', edgecolor = 'blue')
axes.set_xticks([1,2,3])
axes.set_xticklabels(['class 1', 'class 2', 'class 3'])
plt.title('death ratio versus class')
plt.show()
plt.close(fig)
alive_fare = trainset[trainset.Survived == 0].Fare
dead_fare = trainset[trainset.Survived == 1].Fare
fig, axes = plt.subplots(1,1)
sns.distplot(alive_fare, hist = False, kde = True, color = 'pink', rug = False, label = 'alive')
sns.distplot(dead_fare, hist = False, kde = True, color = 'black', rug = False, label = 'dead')
plt.title('survived/dead versus fare')
plt.show()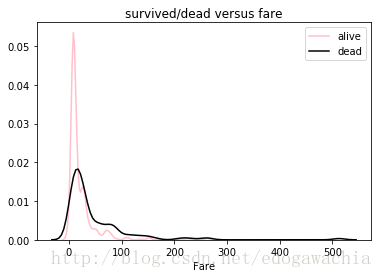
trainset.head(3)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | 1 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
trainset.loc[trainset.Embarked == 'S','Embarked'] = 1
trainset.loc[trainset.Embarked == 'C','Embarked'] = 2
trainset.loc[trainset.Embarked == 'Q','Embarked'] = 3
trainset.tail(3)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen “Carrie” | 1 | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | 1 |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | 0 | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | 2 |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | 0 | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | 3 |
traincorr = trainset.dropna().drop('PassengerId',axis=1).corr()
traincorr| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| Survived | 1.000000 | -0.034542 | 0.532418 | -0.254085 | 0.106346 | 0.023582 | 0.134241 |
| Pclass | -0.034542 | 1.000000 | 0.046181 | -0.306514 | -0.103592 | 0.047496 | -0.315235 |
| Sex | 0.532418 | 0.046181 | 1.000000 | -0.184969 | 0.104291 | 0.089581 | 0.130433 |
| Age | -0.254085 | -0.306514 | -0.184969 | 1.000000 | -0.156162 | -0.271271 | -0.092424 |
| SibSp | 0.106346 | -0.103592 | 0.104291 | -0.156162 | 1.000000 | 0.255346 | 0.286433 |
| Parch | 0.023582 | 0.047496 | 0.089581 | -0.271271 | 0.255346 | 1.000000 | 0.389740 |
| Fare | 0.134241 | -0.315235 | 0.130433 | -0.092424 | 0.286433 | 0.389740 | 1.000000 |
sns.heatmap(traincorr,square=True,vmax=0.99,vmin=-0.99)
plt.show()
fare和pclass負相關,顯然。sex和survivd有一定的正相關性,由於sex中男性0,女性1,而survived中0dead,1survived,也是就說女性更容易獲救。age和parch有些負相關,可能因為小孩子age小,有父母陪同,所以parch大,而成年人獨自出行的多。
axes = plt.figure(figsize=(10,5)).add_subplot(111)
sns.violinplot(ax=axes, x = 'Sex',y = 'Age', hue = 'Survived', data=trainset, split = True) # split 將提琴圖從中間分開,不同hue在不同邊
axes.set_xticks([0,1])
axes.set_xticklabels(['male','female'])
plt.show()
可以看出,成年男性死亡率高,男性中獲救的多數是小孩子,而女性獲救的多數為成年人。可以看出在救援過程中,最大限度的照顧到了婦女和兒童,看來當時船上的人還是很遵從紳士精神的。
axes = plt.figure(figsize=(10,3)).add_subplot(111)
sns.violinplot(ax=axes, x = 'Pclass',y = 'Age', hue = 'Survived', data=trainset, split = True)
axes.set_xticks([0, 1, 2])
axes.set_xticklabels(['high class','median class', 'low class'])
plt.show()
axes = plt.figure(figsize=(10,3)).add_subplot(111)
sns.violinplot(ax=axes, x = 'Pclass',y = 'Sex', hue = 'Survived', data=trainset, split = True)
axes.set_xticks([0, 1, 2])
axes.set_xticklabels(['high class','median class', 'low class'])
plt.show()
從上圖看,可以看到各個艙位的男性和女性的生還比例,以及獲救的和死亡的人裡面男性和女性的比例。首先,頭等艙女性生還比例很大,而吊斯艙裡面的女性死亡率比較高,相對的,頭等艙的男性生還比率很低,而吊斯艙的男性生還率是三個艙位裡最大的。說明不同階層的人在災難事件中採取的對策還是不一樣的,相較而言,階層較高的人群可能會更遵守婦女兒童先上船的規則。但是,我們從上圖還能看出,不管那個階層,男性的死亡率都比女性要高很多,女性生還的都是多於死亡的,而男性死亡的遠多於生還的。由此看來,即便對待婦女的態度上確實有階級差異,但是總體來說,船上的男人們都履行了紳士精神,讓本來應該在災難面前力量弱於青壯年男性從而死亡率理應更高的婦女兒童爭取到了更多的機會,說明船上的男士還是很優秀的。
對於資料的EDA到此差不多了,下面要找我們可以選擇用來分類的特徵。由以上分析可以看出,sex和age兩個應該是主要的特徵,pclass也可以列入考慮,fare和pclass有一定的關係,也可以利用。之後,我們可以利用sklearn工具包用這幾個特徵分類一下,檢視結果。
2018年02月22日16:55:26
真是的,無所事事的時候別談什麼將來嘛! —— 漫畫家,空知英秋
相關推薦
Kaggle 入門級題目titanic資料分析(EDA)嘗試
Titanic: ML from disaster deal with csv trainning data using pandas etc. Titanic是kaggle的一個toy級別的入門問題,主要是為了熟悉一下kaggle題目的解題思路,以及用到的
cordova入門級簡單功能的實現(四)
cordova入門級簡單功能的實現(四) 1:安裝sdk ** 首先什麼是SDK** SDK:軟體開發工具包(縮寫:SDK、外語全稱:Software Development Kit)一般都是一些軟體工程師為特定的軟體包、軟體框架、硬體平臺、作業系統等建立應用軟體時的開發工具的集
資料分析(一)豆瓣華語電影分析
本文首發於『運籌OR帷幄』公眾號,大家也可前往公眾號檢視,《用資料帶你瞭解電影行業—華語篇》。 在之前,我們已經用通過爬蟲獲取了豆瓣華語電影共33133部電影的資料,具體爬蟲介紹請見之前的博文,爬蟲實戰(一)——利用scrapy爬取豆瓣華語電影。本文對爬蟲過程進行簡要概述後,對這部分資料
bigdata資料分析(一):Java環境配置
Java環境 1.下載jdk(用FileZilla工具連線伺服器後上傳到需要安裝的目錄) 在 /opt/deploy 下新建 java 資料夾: # mkdir / opt/deploy /java 解壓命令:tar zxvf 壓縮包名稱 (例如:tar zxvf jdk-8u191-
微信好友資料打包下載--微信資料分析(二)
簡述 其實要這麼做的原因就是,我們之前操作的每次都要登入確認什麼的,比較麻煩。所以,如果我們能夠一次性將所有的資料都下載下來,然後儲存起來,那麼就可以直接操作資料,而不需要等待拿資料的過程了~ 程式碼
微信好友個性標籤詞雲--微信資料分析(四)
簡述 程式碼 構建詞雲的時候,採用的背景圖 生成的效果為: 可以發現,我的微信朋友們的雖然表面上看起來一個個都是逗比,但是個性標籤似乎都是慢慢的正能量哇~ 下面使用的時候,我用的是我之前已經打包好
Python 金融資料分析(二)
1.樣本資料位置 series = Series() series.mean() # 均數 series.median() # 中位數 series.mode() # 眾數 series.quantil
企業如何運用好資料分析(二)
在前面提到的內容中我們不難發現數據分析能夠在企業發揮很大的作用,但是對於資料分析還是需要學習很多的知識,尤其是在進行資料分析的時候需要重視細節。因為資料分析需要嚴謹的態度,如果忽視了細節,那麼就會一著不慎滿盤皆輸。在表達資料分析結果的時候我們會用到很多的圖表。這樣才能夠做好資料分析。在這篇文章中我們會為大
資料分析(三)
Pandas的資料結構 匯入pandas: 資料分析三劍客 numpy pandas matplotlib # 三劍客 import numpy as np import pandas as pd import matplotlib.pyplot as plt
資料分析(二)
Numpy:Numeric Python 引言:要學好機器學習,先打好資料分析的基礎,打好基礎才能實現後面那些經驗的功能 一、匯入 匯入:import numpy as np 檢視版本:np.__ version __ 二、陣列ndarray 1、使用np.ar
資料分析(四)
之前我們學習了numpy,pandas。現在能自己引入資料分析的三劍客不?試一試吧,想不起來,就要看看前面的呦。 來吧,我們一起匯入一下吧! import numpy as np import pandas as pd from pandas import Se
企業如何運用好資料分析(一)
現階段,由於科技的進步以及社會的發展,使得網際網路越來越發達。網際網路時代衍生了很多的新興詞彙,分別是大資料、資料分析、物聯網、人工智慧等。現如今我們的社會生活到處都滲透著中大資料、資料分析和人工智慧,越來越多的企業都開始重視資料分析。利用好資料分析能夠甩開競爭對手,從而使得自己的企業
Spark快速大資料分析(一)
楔子 Spark快速大資料分析 前3章內容,僅作為學習,有斷章取義的嫌疑。如有問題參考原書 Spark快速大資料分析 以下為了打字方便,可能不是在注意大小寫 1 Spark資料分析導論 1.1 Spark是什麼 Spark是一個用來實現快速而通用的叢
資料分析(五)
週末,終於閒了下來。突然想起資料分析的知識還沒整理完。好吧,廢話就不多說了,我們繼續總結相關的知識點。 前面學了series和dataframe,今天我們先說說他們的運算: 【重要】 使用Python操作符:以行為單位操作,對所有行都有效。(類似於numpy中二
創業公司做資料分析(四)ELK日誌系統
作為系列文章的第四篇,本文將重點探討資料採集層中的ELK日誌系統。日誌,指的是後臺服務中產生的log資訊,通常會輸入到不同的檔案中,比如Django服務下,一般會有nginx日誌和uWSGI日誌。這些日誌分散地儲存在不同的機器上,取決於服務的部署情況了。如果
創業公司做資料分析(一)開篇
瞭解“認知心理學”的朋友應該知道:人類對事物的認知,總是由淺入深。然而,每個人思考的深度千差萬別,關鍵在於思考的方式。通過提問三部曲:WHAT->HOW->WHY,可以幫助我們一步步地從事物的表象深入到事物的本質。比如學習一個新的技術框架,需要逐步
創業公司做資料分析(二)運營資料系統
作為系列文章的第二篇,本文將首先來探討應用層中的運營資料系統,因為運營資料幾乎是所有網際網路創業公司開始做資料的起點,也是早期資料服務的主要物件。本文將著重回顧下我們做了哪些工作、遇到過哪些問題、如何解決並實現了相應的功能。 早期資料服務 產品上
創業公司做資料分析(三)使用者行為資料採集系統
作為系列文章的第三篇,本文將重點探討資料採集層中的使用者行為資料採集系統。這裡的使用者行為,指的是使用者與產品UI的互動行為,主要表現在Android App、IOS App與Web頁面上。這些互動行為,有的會與後端服務通訊,有的僅僅引起前端UI的變化,但是
創業公司做資料分析(六)資料倉庫的建設
作為系列文章的第六篇,本文將重點探討資料處理層中資料倉庫的建設。在第二篇運營資料系統一文,有提到早期的資料服務中存在不少問題,雖然在做運營Dashboard系統時,對後臺資料服務進行了梳理,構建了資料處理的底層公共庫等,但是仍然存在一些問題: 中間資料流
創業公司做資料分析(五)微信分享追蹤系統
作為系列文章的第五篇,本文重點探討資料採集層中的微信分享追蹤系統。微信分享,早已成為移動網際網路運營的主要方向之一,以Web H5頁面(下面稱之為微信海報)為載體,利用微信龐大的好友關係進行傳播,實現宣傳、拉新等營銷目的。以下圖為例,假設有一個海報被分享到了