
LruCache原理和用法與LinkedHashMap
一.LruCache演算法
LruCache演算法就是Least Recently Used,也就是最近最少使用演算法。
他的演算法就是當快取空間滿了的時候,將最近最少使用的資料從快取空間中刪除以增加可用的快取空間來快取新內容。
這個算分的內部有一個快取列表。每當一個快取資料被訪問的時候,這個資料就會被提到列表頭部,每次都這樣的話,列表的尾部資料就是最近最不常使用的了,當快取空間不足時,就會刪除列表尾部的快取資料。
二.LruCache部分原始碼
Least Recently Used,最近最少使用
下面只是部分原始碼
package android.util;
import 通過這個原始碼,可以發現,LruCache的演算法實現主要是依靠LinkedHashMap來實現的。
三.為什麼用LinkedHashMap
為什麼要用LinkedHashMap來存快取呢,這個跟演算法有關,LinkedHashMap剛好能提供LRUCache需要的演算法。
這個集合內部本來就有個排序功能,當第三個引數是true的時候,資料在被訪問的時候就會排序,這個排序的結果就是把最近訪問的資料放到集合的最後面。
到時候刪除的時候就從前面開始刪除。
1.構造方法
LinkedHashMap有個構造方法是這樣的:
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}2.Entity的定義
LinkedHashMap內部是使用雙向迴圈連結串列來儲存資料的。也就是每一個元素都持有他上一個元素的地址和下一個元素的地址,看Entity的定義:
/**
* LinkedHashMap entry.
*/
private static class LinkedHashMapEntry<K,V> extends HashMapEntry<K,V> {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, HashMapEntry<K,V> next) {
super(hash, key, value, next);
}
/**
* 從連結串列中刪除這個元素
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* 當集合的get方法被呼叫時,會呼叫這個方法。
* 如果accessOrder為true,就把這個元素放在集合的最末端。
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}3.get方法的排序過程
看LinkedHashMap的get方法:
public V get(Object key) {
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}具體是怎麼進行排序的,畫個圖看看:
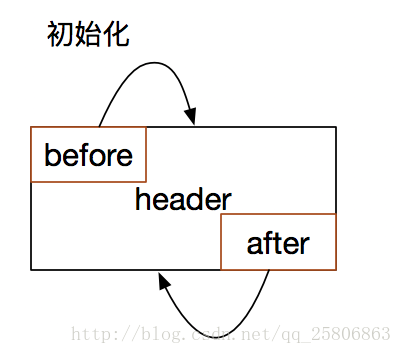
- 當LinkedHashMap初始化的時候,會有一個頭節點header。
void init() {
header = new LinkedHashMapEntry<>(-1, null, null, null);
header.before = header.after = header;
}可以看到這個頭節點的前節點和後節點都指向自己。
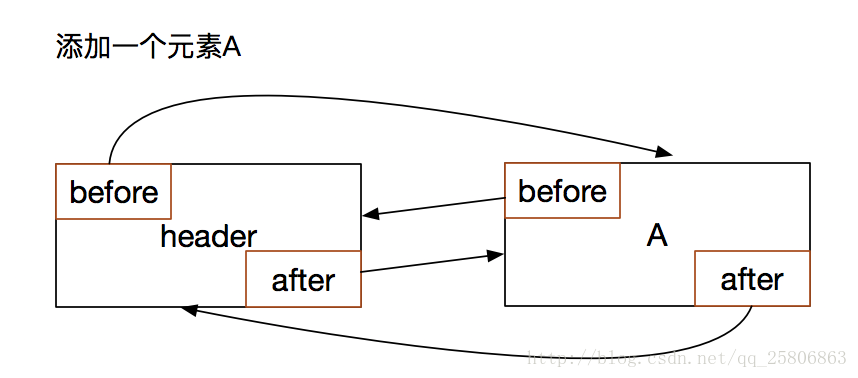
新增一個數據A
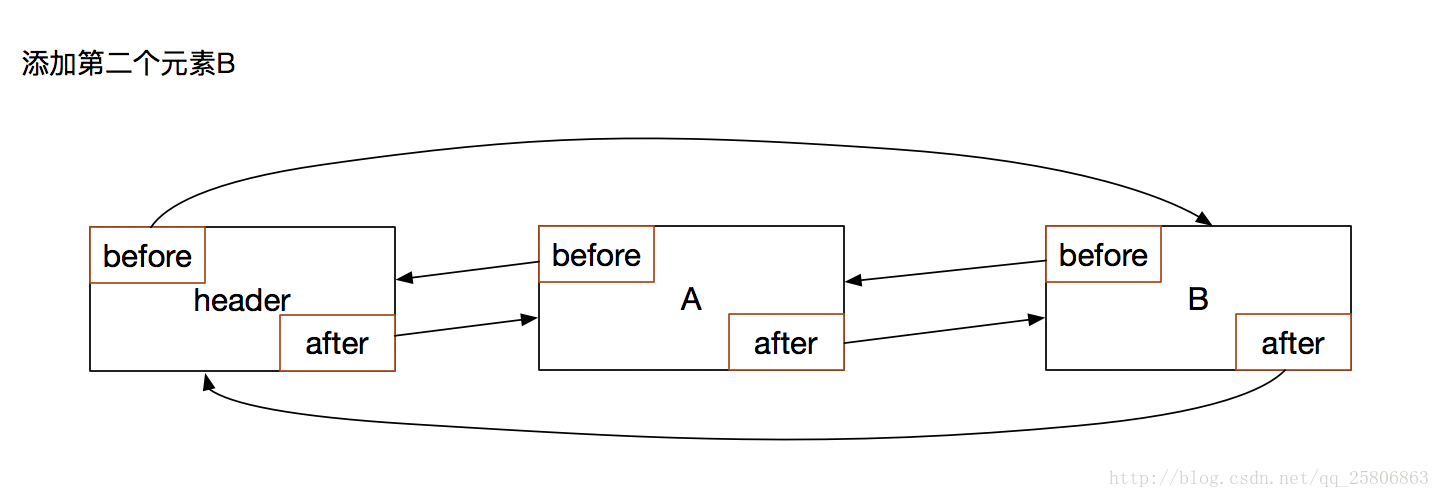
新增一個數據B
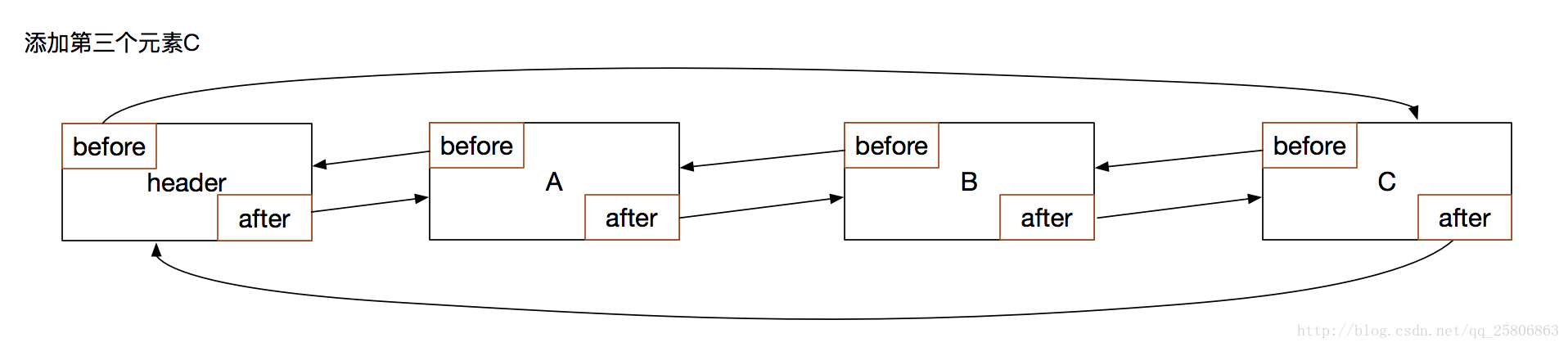
再新增一個數據C
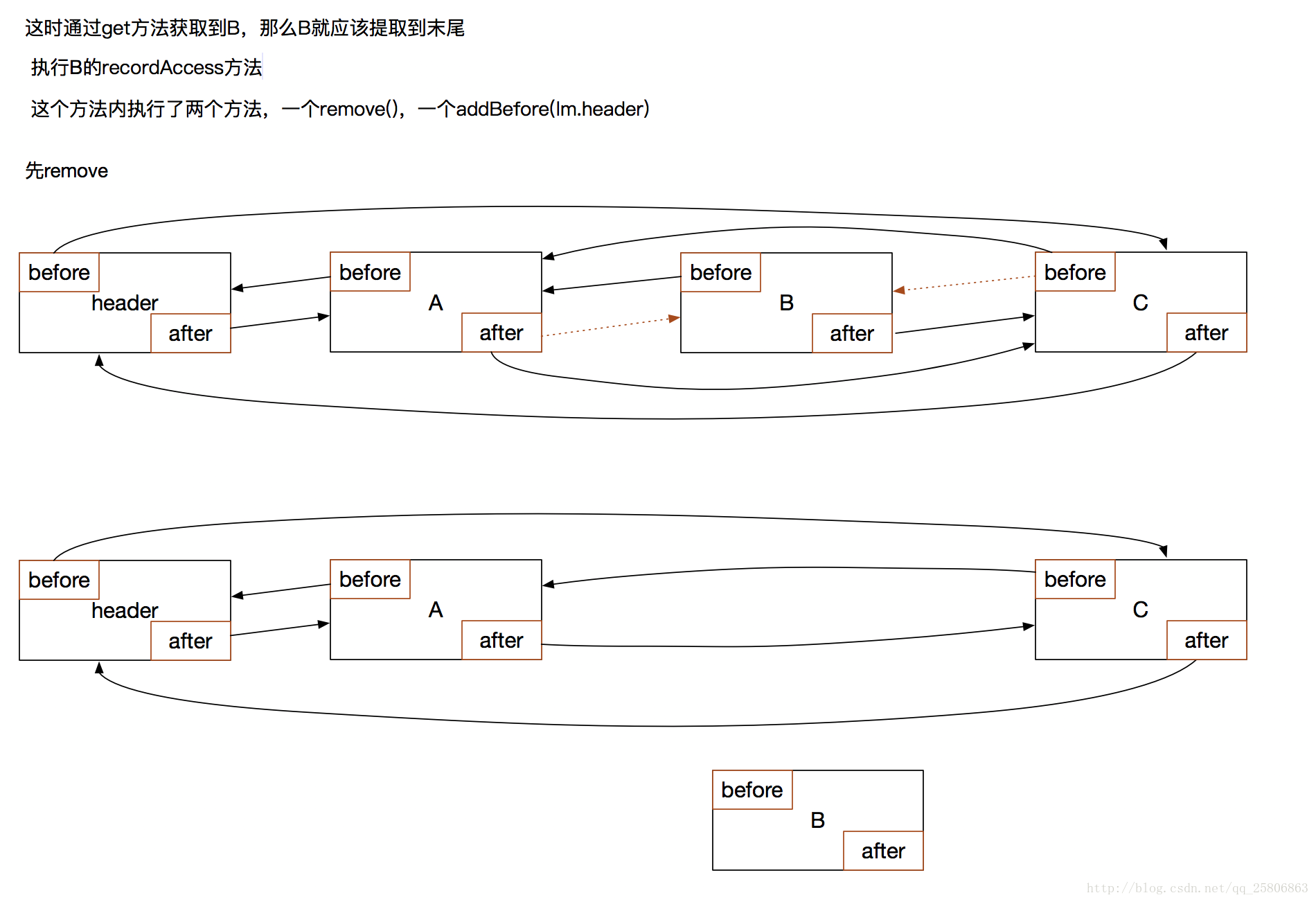
這是通過get訪問資料B
看上面的get方法就知道,他會呼叫B的recordAccess(this)方法,這個this就是這個LinkedHashMap。
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}- recordAccess(this)方法
會先呼叫remove方法,把自己從連結串列中移除:
private void remove() {
before.after = after;
after.before = before;
}
在呼叫addBefore(lm.header)方法,把自己新增到連結串列的結尾:
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}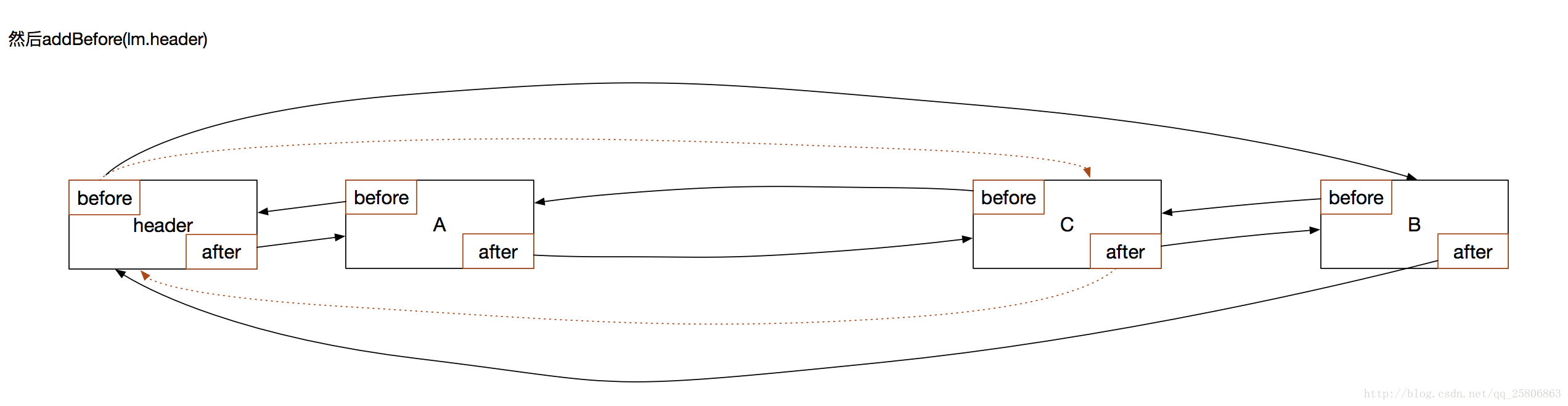
大功告成。這樣就完成了一次Lru排序。將最近訪問的資料放在了連結串列的結尾,連結串列越靠前的越不常用,快取空間不夠就優先清楚前面的。
4.獲取一個最該清除的不常用的元素
LinkedHashMap還有一個方法eldest(),提供的就是最近最少使用的元素:
public Map.Entry<K, V> eldest() {
Entry<K, V> eldest = header.after;
return eldest != header ? eldest : null;
}結合流程圖片可以看到,header.after就是A,也就是符合要求的需要清除的資料。
四.回到LruCache類
在LruCache中是怎麼結合LinkedHashMap實現這個快取的呢?
前面的方法就很明顯了。
- 首先在初始化LinkedHashMap的時候,是這樣的:
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);第三個引數為true,因此每次訪問LinkedHashMap的資料,LinkedHashMap都回去進行排序,將最近訪問的放在連結串列末尾。
- LruCache的put方法呼叫了LinkedHashMap的put來儲存資料,自己進行了對快取空間的計算。LinkedHashMap的put方法也會進行排序。
- LruCache的get方法呼叫了LinkedHashMap的get來獲取資料,由於上面的第三個引數是true,因此get也會觸發LinkedHashMap的排序
trimToSize(int maxSize)
這是LruCache的核心方法了,get和put都可能會執行這個方法。
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}這個方法會檢查已用的快取大小和設定的最大快取大小。
當發現需要進行刪除資料來騰出快取空間的時候,會呼叫LinkedHashMap的eldest()方法來獲取最應該刪除的那個資料,然後刪除。
這樣就完成了他的演算法。
五.用LruCache來快取Bitmap的初始化
LruCache<String, Bitmap> mLruCache;
//獲取手機最大記憶體 單位 kb
int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
//一般都將1/8設為LruCache的最大快取
int cacheSize = maxMemory / 8;
mLruCache = new LruCache<String, Bitmap>(maxMemory / 8) {
/**
* 這個方法從原始碼中看出來是設定已用快取的計算方式的。
* 預設返回的值是1,也就是沒快取一張圖片就將已用快取大小加1.
* 快取圖片看的是佔用的記憶體的大小,每張圖片的佔用記憶體也是不一樣的,一次不能這樣算。
* 因此要重寫這個方法,手動將這裡改為本次快取的圖片的大小。
*/
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount() / 1024;
}
};使用:
//加入快取
mLruCache.put("key", BitmapFactory.decodeResource(getResources(), R.mipmap.ic_launcher));
//從快取中讀取
Bitmap bitmap = mLruCache.get("key");
相關推薦
LruCache原理和用法與LinkedHashMap
一.LruCache演算法 LruCache演算法就是Least Recently Used,也就是最近最少使用演算法。 他的演算法就是當快取空間滿了的時候,將最近最少使用的資料從快取空間中刪除以增加可用的快取空間來快取新內容。 這個算分的內部有一個快取列
linux下crontab的原理和用法
amp %d 檢查 pos 時間 運行時間 tor mman body linux 系統則是由 cron (crond) 這個系統服務來控制的。Linux 系統上面原本就有非常多的計劃性工作,因此這個系統服務是默認啟動的。另 外, 由於使用者自己也可以設置計劃任務,所以,
List集合原始碼解析原理和用法
注:以下所用原始碼均基於JDK1.8基礎(特殊說明除外) 先從原始碼入手解析: public interface List<E> extends Collection<E> {} An ordered collection (also know
feof()原理和用法
一、feof()是什麼? feof()是檢測流上的檔案結束符的函式,如果檔案結束,則返回非0值,否則返回0 一般在檔案操作,中經常使用feof()判斷檔案是否結束。 二、feof()的經典錯誤 根據這個函式的定義,一般大家都是這樣使用的,但是這樣使用
spark原理和spark與mapreduce的最大區別
參考文件:https://files.cnblogs.com/files/han-guang-xue/spark1.pdf 參考網址:https://www.cnblogs.com/wangrd/p/6232826.html 對於spark個人理解: spark與mapreduce最
meshgrid的原理和用法
簡單地說,就是產生Oxy平面的網格座標。 在進行3-D繪圖操作時,涉及到x、y、z三組資料,而x、y這兩組資料可以看做是在Oxy平面內對座標進行取樣得到的座標對(x,y)。 例如,要在“3<=x<=5,6<=y<=9,z不限制區間”
JSON Web Token(JWT)原理和用法介紹
JSON Web Token(JWT)是目前最流行的跨域身份驗證解決方案。今天給大家介紹一下JWT的原理和用法。 一、跨域身份驗證 Internet服務無法與使用者身份驗證分開。一般過程如下。 1. 使用者向伺服器傳送使用者名稱和密碼。 2. 驗證伺服器後,相關資料(如使用者角色,登入時間等)將儲存在
JSON Web Token(JWT)使用步驟說明 JSON Web Token(JWT)原理和用法介紹
在JSON Web Token(JWT)原理和用法介紹中,我們瞭解了JSON Web Token的原理和用法的基本介紹。本文我們著重講一下其使用的步驟: 一、JWT基本使用 Gradle下依賴 : compile 'com.auth0:java-jwt:3.4.0' 示例介紹: im
三、histeq的原理和用法
本系列文章都是通過自己的學習經驗,以及啃文件所寫。如需轉載,請註明出處 參考文件:Image Processing Toolbox™ 6User’s Guide 作者:joy 如果影象的對比度太差,常用的方法就是灰度直方圖均衡化。在matlab中,能達到這個目的的函
Python進階——詳解元類,metaclass的原理和用法
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天是Python專題第18篇文章,我們來繼續聊聊Python當中的元類。 在上上篇文章當中我們介紹了type元類的用法,在上一篇文章當中我們介紹了__new__函式與__init__函式的區別,以及它在一些設計模式當中的運用。這篇文
淺談mmap()和ioremap()的用法與區別
12只 設備 gpa 我們 之間 mmap ioremap shared set 一、mmap()mmap()函數是用來將設備內存線性地址映射到用戶地址空間。(1)首先映射基地址,再通過偏移地址尋址;(2)unsigned char *map_cru_base=(unsig
固件空中升級(OTA)與固件二次引導的原理和設計
vid data 公眾 iss 畢業 hit clas 設計思想 andro 藍牙固件空中升級(OTA)涉及到藍牙無線通信、固件外存分布、固件內存分布(定制鏈接腳本)、固件二次引導等技術,須要開發者深入理解藍牙單芯片的存儲架構、啟動引導流程、外存設備驅動和產品電路設計
oracle 之 偽列 rownum 和 rowid的用法與區別
lena select 區別 name 繼續 class 重復 clas 重復數據 rownum的用法 select rownum,empno,ename,job from emp where rownum<6 可以得到小於6的值數據 select rownum,e
Java-IO流之轉換流的使用和編碼與解碼原理
鍵盤輸入 tostring delet 特點 rgb utf8 equals pri 數據 一、理論: 1、字符流和字節流區別是什麽? 字符流=字節流+編碼集,在實際讀取的時候其實字符流還是按照字節來讀取,但是會更具編碼集進行查找編碼集字典解析相應的字節,使得一次讀取出一個
【轉】typedef和#define的用法與區別
++ 說明 運算符 lan body 精度 標識 gpo 幫助 typedef和#define的用法與區別 一、typedef的用法 在C/C++語言中,typedef常用來定義一個標識符及關鍵字的別名,它是語言編譯過程的一部分,但它並不實際分配內存空間,實例像:
margin和padding的用法與區別--以及bug處理方式
使用 滿足 左右 ron 相互 一段 布局 方式 ont margin和padding的用法: (1)padding (margin) -left:10px; 左內 (外) 邊距(2)padding (margin) -right:10px;
淺談JS中的!=、== 、!==、===的用法和區別 JS中Null與Undefined的區別 讀取XML文件 獲取路徑的方式 C#中Cookie,Session,Application的用法與區別? c#反射 抽象工廠
main 收集 data- 時間設置 oba ase pdo 簡單工廠模式 1.0 var num = 1; var str = ‘1‘; var test = 1; test == num //true 相同類型 相同值 te
iptables的原理和基本用法
iptables 原理 基本用法 iptables-----可以將規則組成一個列表,實現絕對詳細的訪問控制功能。一、iptables基礎Iptables中的規則表:規則表的先後順序:raw→mangle→nat→filte規則鏈的先後順序:入站順序:PREROUTING→INPUT出站順序:OUT
淺談@RequestMapping @ResponseBody 和 @RequestBody 註解的用法與區別
ber attribute thrown text 返回結果 mode 需要 oca 格式 1.@RequestMapping 國際慣例先介紹什麽是@RequestMapping,@RequestMapping 是一個用來處理請求地址映射的註解,可用於類或方法上。用於類上,
淺談new/delete和malloc/free的用法與區別
淺談new/delete和malloc/free的用法與區別 目錄 一.new和delete用法 二.malloc和free的用法 三.new和malloc的區別 正文 每個程式在執行時都會佔用一塊可用的記憶體空間,