
令仔學Redis(一)----淺析Redis儲存資料時格式的設計
阿新 • • 發佈:2019-01-22
之前接觸的一個業務,資料量的話現在在資料庫中存了有將近400W的資料,在搜尋的時候得到的這些資料會放入達到非同步佇列中,然後單獨開一個執行緒來進行雙寫,寫快取,然後寫資料庫。Redis中的儲存格式是Hash儲存的,資料庫的儲存格式類似Hash,當時設計儲存方式的時候是有些問題的,在Redis中儲存的時候,資料庫中有多少條資料,Redis中就會有多少個Key值。也就是說Redis中儲存的一級Key有400W個,這樣的儲存格式會造成Redis的查詢變慢,具體的原因下面解釋。
| 具體原因 |
Redis的查詢,都是根據Key值來操作的,Hash可以Key值或者根據Key和Field來確定一條記錄。具體的操作可以去百度。其實可以把Redis的儲存看成一棵樹。Key是最頂端的存在。
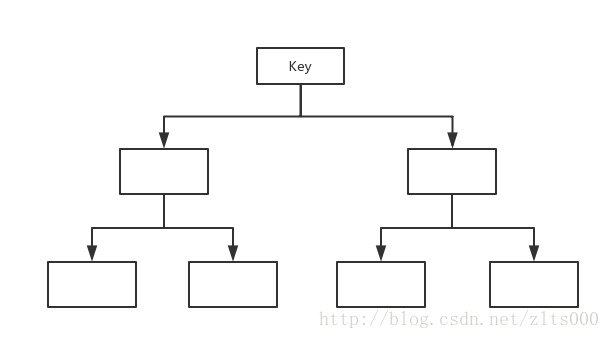
資料量小的情況下,儲存的話沒有太大的要求。但是當資料量大的時候,就要細細的考慮下值的儲存方式。正如我上邊儲存400W資料的方式,相當於把400W的資料都放到了一級Key上,就是沒有任何的深度而言。

所有的Key都儲存在了同一個層級上,這樣的話,當查詢的時候,就要遍歷400W個Key值來找到你想要的資料。自己都感覺自己的設計是一坨翔。。。
| 優化設計 |
最好的辦法,就是減少一級Key的數量。舉個例子,花和樹。假如全世界有花共100W種類,樹也有100W,那怎麼設計儲存方式?
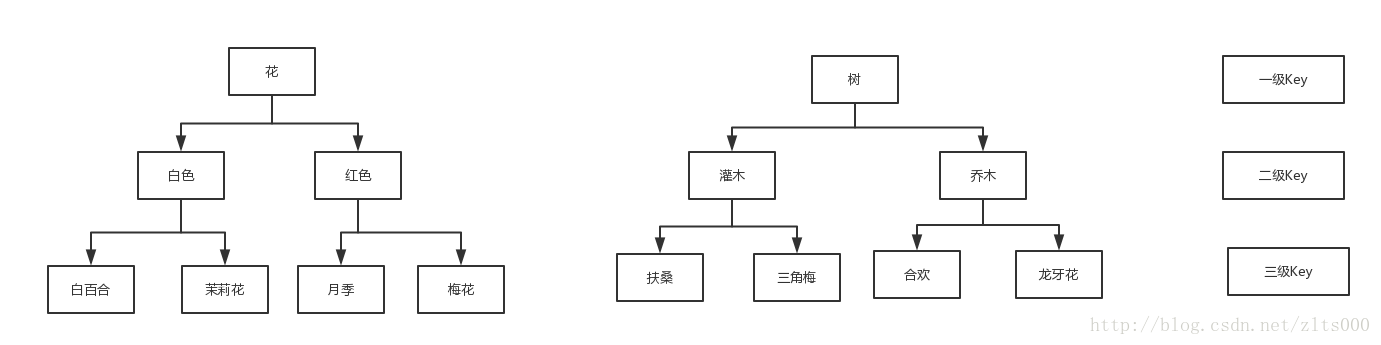
一級Key的設計要有自己的特點,這樣刪除的時候也很方便去刪除。正如上圖的設計一樣,我要是查詢一種具體的花,一級Key就可以過濾掉100W的資料,然後有可能知道具體的花的種類,再子節點查詢的時候,每到一個子節點都可以過濾掉10倍的資料。這樣才是最合適的。存的資料多,但是查詢的時候也能夠快速的定位到你想要的資料,何樂而不為呢?