python 網路爬蟲例項
阿新 • • 發佈:2019-01-22
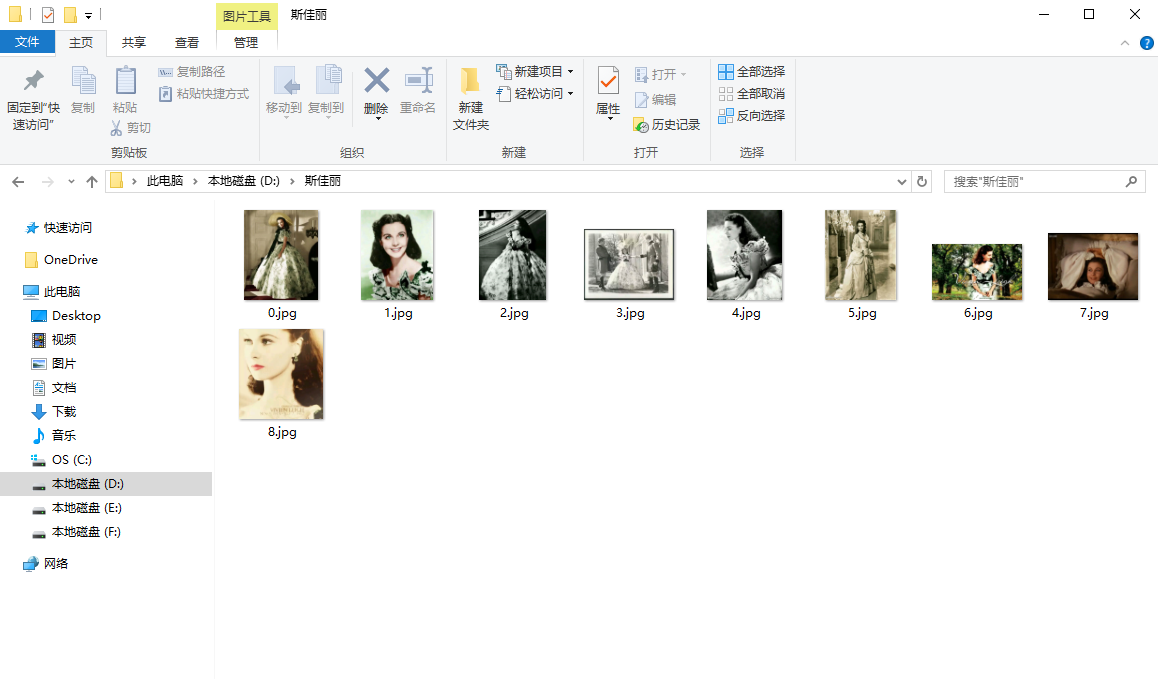
自己用Python寫了一個抓取百度貼吧裡面的圖片的小例項,程式碼如下:
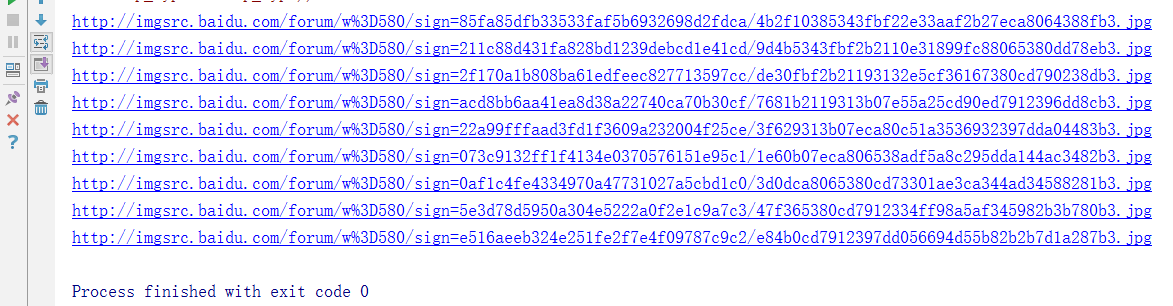
from urllib.request import urlopen from urllib.request import urlretrieve from urllib.error import HTTPError from bs4 import BeautifulSoup #BeautifulSoup需要自己安裝 import sys import re import os def getImg(url): try: html = urlopen(url) except HTTPError as e: print(e) return None try: bsObj = BeautifulSoup(html.read()) images=bsObj.findAll("img",{"src":re.compile("http:\/\/imgsrc\.baidu\.com\/forum\/w%3D580\/sign=.*\.jpg")})#抓取貼吧裡面的圖片 for image in images: print(image["src"])#遍歷輸出圖片的地址 x = 0 path = 'D:\\斯佳麗' # 將圖片儲存到D:\\斯佳麗資料夾中,如果沒有斯佳麗資料夾則建立 if not os.path.isdir(path): os.makedirs(path)#如果D:\\斯佳麗資料夾不存在則重新建立一個,否則會被覆蓋 paths = path + '\\' # 儲存在test路徑下 for image in images: urlretrieve(image["src"], '{}{}.jpg'.format(paths, x)) # 開啟images中儲存的圖片網址,並下載圖片儲存在本地,format格式化字串 x = x + 1 except AttributeError as e: return None getImg("http://tieba.baidu.com/p/3118834498")
結果如下:
抓取的圖片如下: