
DIM(Learning deep representations by mutual information estimation and maximization)
摘要:
許多表示學習只使用已探索過的資料空間(稱為畫素級別),當一小部分資料十分關心語義級別時,該表示學習將不利於訓練。論文提出了無監督表示學習,直接學習和估計資訊內容,統計或結構約束。論文最大化輸入資訊和高階特徵向量之間的互資訊與通過對抗匹配先驗分佈來控制表示學習的特徵。
介紹:
人工智慧單元在預測和規劃時不應該停留在畫素級別或者感測器級別,而是應該在抽象表示級別。畫素級別的非監督機器學習可以在不捕捉語義資訊時表現的非常出色,但是它們並不是好的表示。解決學習一個訓練目標的表示而不適用提前定義好的輸入,一個簡單解決辦法是直接訓練表示學習的函式,最大化輸入和輸出之間的互資訊。在論文 MINE
生成模型:
生成模型依賴重建和對抗,重建誤差與互資訊的聯絡可以如下表示
其中,X 和 Y 分別代表隨機變數的輸入和表示,而表示重建誤差,
表示編碼器的邊緣分佈的熵。在雙向對抗模型(bi-directional adversarial models)訓練編碼器和解碼器來匹配表示的聯合分佈,這樣操作會增加邊緣分佈的熵或者減小重建誤差。在 GAN 裡面採用生成和對抗模型,辨別器來辨別真假圖片時需要很高的互資訊值,但是在高維度情境下,學習生成模型非常困難。同時,圖片中不是所有資訊都很重要,有時候一張圖片只有一小部分的特徵就可以表示整個圖片的重要資訊。
免解碼器模型:
依賴最大化似然函式的演算法(arXiv:1410.8516,2014),但該演算法為了成立一個似然目標函式嚴格限制了編碼器和輸出空間。深度聚類演算法(Unsupervised deep embedding for clustering analysis)在非監督聚類中表現優異,但是用途不廣闊。NAT演算法將表示作為一個監督學習中的噪聲目標來進行非監督學習,不需要生成模型,但是需要一個推斷機制將輸入和噪聲排列起來。NAT演算法需要大量的取樣,並需要訓練先驗分佈,同時NAT演算法如何影響輸入資料的大小和表示的維度並不清楚。
互資訊估計:
INFOMAX 主張最大化輸入和輸出之間的互資訊。MINE 演算法學習連續變數的神經網路估計的互資訊,通過最大化編碼器的輸入和輸出來約束變數和用於學習更好的生成模型。論文使用 KL 散度,使用層級化輸入的結構來提升表示分類的能力。DIM 使用特徵對映對應區域的層級化的取樣,使用 1x1 的卷積來表示當地的小塊區域和全域性變數之間的互資訊估計。
DIM:
定義式如下:
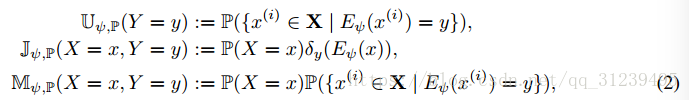
是一個關於 y 的 Dirac 函式。
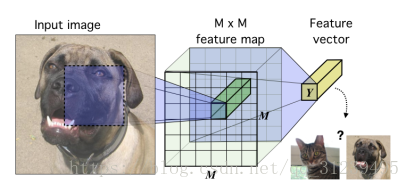
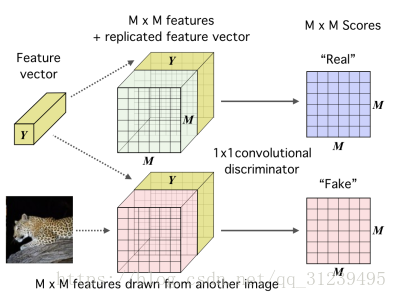
如左圖所示為編碼器的示意圖:影象資訊被編碼為一個卷積神經網路,卷積過程直到對映 MXM 對應了輸入的 MXM,使用全連線整合成一個特徵向量,目標是訓練這個神經網路,這個神經網路的輸入的相關資訊可在高層特徵中抽離出來。
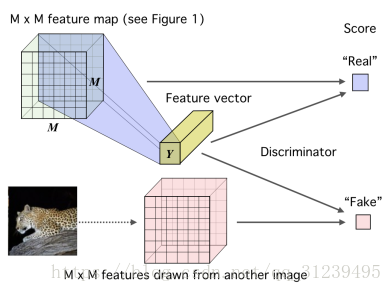
如上右圖所示,我們提出一個高維向量 Y 和一個低級別 MXM 的對映通過一個鑑別器來打分,鑑別器由神經網路,全連線網路組成,假的取樣通過與另一個影象的相同特徵向量結合而描繪出來。
互資訊的估計和最大化:
其中是一個基於引數 w 的鑑別函式,論文同時最大化和估計互資訊
,如下公式:
因為編碼器和MINE演算法在優化目標函式的時候使用類似的計算方法,所以論文結合了最初的兩種網路結構:
論文使用 JSD 散度公式,結合解碼器和MINE的目標函式,得到如下公式:
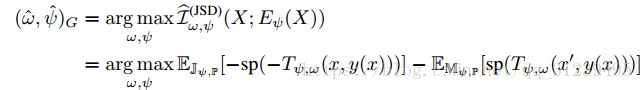
其中,y(x)是一個更級別的表示,x' 是與 y 不相關的另外一個輸入,,JSD散度公式更適合本論文最大化互資訊,① JSD 的上屆 log2,在計算時不會產生特別大的數 ② JSD 的梯度是無偏的。
最大化當地互資訊:
上述公式是最大化輸入和輸出的互資訊的,但是根本上我們的任務並不需要那麼做,比如當地畫素的噪聲,如果最終的目標是分類,那麼這個表示就不太優異。為了保證表示模型能夠適應分類任務,我們最大化高階表示和當地小範圍影象的平均互資訊。因為相同的表示鼓勵更高的互資訊,某些區域的資料會共用了一部分資料,解碼器可以選擇輸入資訊的型別,但是當解碼器通過某些特定輸入資訊時,不會因為其他的區域不包含上述噪聲而增大互資訊,這將使得解碼器更傾向於輸入中共享的資訊。
如下圖所示:最大化當地特徵和高階特徵向量之間的互資訊,論文將影象編碼成一個對映,該對映包含資料的一些結構特徵,並且將該對映整合成一個全域性特徵向量(在上圖可以看到)這個特徵向量在每一個區域都連結低階特徵對映,一個1x1的卷積鑑別器用來給真實圖片和假圖片打分,假圖片是通過另外一張影象生成的對映而生成的。
公式轉化如下:
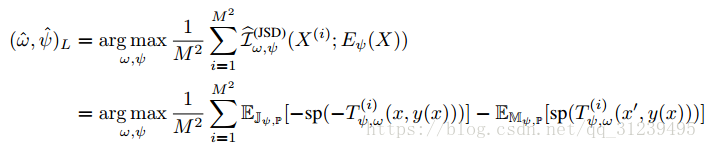
論文提出,當地互資訊最大化雖然引入了真實和虛假圖片的概率,但是並沒有顯著提高效果。
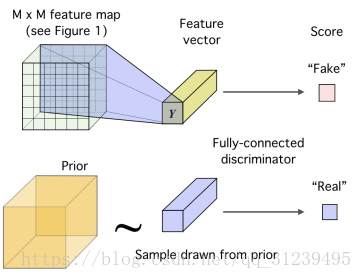
匹配表示與先驗分佈:
好的表示學習應該是簡潔的、獨立的、無糾纏的(disentangled)或者獨立可控的。如圖所示:訓練解碼器是為了疑惑鑑別器,使之不能分辨出真的圖片和假的圖片。真的取樣取自先驗分佈,假的取樣取自編碼器。
公式如下:訓練編碼器最小化散度
將全域性互資訊,區域互資訊和先驗分佈匹配加到一起,得到如下公式:
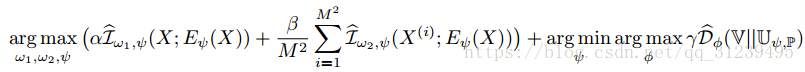
w1 和 w2 分別是鑑別器全域性和區域目標的引數,α、β 和 γ 是超引數。