
詳細教程 :crawler4j 爬取京東商品資訊 Java爬蟲入門 crawler4j教程
現今比較流行的爬蟲語言,屬Java、paython和c語言,筆者學習的是Java語言,所以介紹下使用Java如何爬取網頁資訊。
我們先從一個最原始的Java爬蟲demo開始,再來看如何使用crawler4j這個框架進行爬蟲。
Demo
使用Java的Url物件,指向網址並建立連線,獲取輸入流,解析流中的資訊。該Demo只需一個jdk即可,不用引入其他jar包,下面請看原始碼。
public static void main(String[] args) throws IOException { //新建一個url物件 通過構造方法傳入url值 URL url = new URL("https://www.jd.com/"); //建立Java和url的一個連線,相當於我們訪問網址,不同的是Java返回的是connection 我們肉眼返回的是網頁內容 HttpURLConnection connection = (HttpURLConnection) url.openConnection(); //通過相應狀態碼判斷是否訪問成功 int code = connection.getResponseCode(); if (code != 200) { return; } //獲取connection對網頁訪問之後 的一個輸入流,該流中包含了網頁的資訊內容 InputStream stream = connection.getInputStream(); //通過BufferedReader 獲取流中的資訊 BufferedReader reader = new BufferedReader(new InputStreamReader(stream, "utf-8")); //輸出資訊 String r = null; while ((r = reader.readLine()) != null) { System.out.println(r); } }
這裡的url傳入時必須要帶http協議,不能只傳入jd.com,否則會報異常:
Exception in thread "main" java.net.MalformedURLException: no protocol: jd.com我們看一下輸出內容(僅截取了一小部分內容):
<!DOCTYPE HTML> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>京東(JD.COM)-正品低價、品質保障、配送及時、輕鬆購物!</title> <meta name="description" content="京東JD.COM-專業的綜合網上購物商城,銷售家電、數碼通訊、電腦、家居百貨、服裝服飾、母嬰、圖書、食品等數萬個品牌優質商品.便捷、誠信的服務,為您提供愉悅的網上購物體驗!" /> <meta name="Keywords" content="網上購物,網上商城,手機,筆記本,電腦,MP3,CD,VCD,DV,相機,數碼,配件,手錶,儲存卡,京東" /> <script type="text/javascript"> window.pageConfig = { compatible: true, preload: false, navId: "jdhome2016", timestamp: 1521683291000, isEnablePDBP: 0,, surveyTitle : "調查問卷", surveyLink : "//surveys.jd.com/index.php?r=survey/index/sid/889711/newtest/Y/lang/zh-Hans", leftCateABtestSwitch : 0, "" : "" };
至此,一個簡單的爬蟲就已經實現完成了。原理很簡單:使用Url物件,指向網址並建立連線,獲取輸入流,解析流中的資訊,根據獲取的資訊內容,篩選出自己的需求資訊即可。當然,這幾行程式碼可能遠遠不能滿足我們的需求,所以市場上有了很多開源的Java爬蟲框架,例如nutch、Heritrix、crawler4j等等,具體有何區別,請點選這裡。
下面我們進入正題,如何運用crawler4j進行快速爬蟲。github原始碼下載

根據github上的原始碼和readme.md文件,可以很快使用crawler4j進行爬蟲。有一定英語基礎可以看看readme.md文件。
crawler4j is an open source web crawler for Java which provides a simple interface for crawling the Web. Using it, you can setup a multi-threaded web crawler in few minutes.
上面介紹說,crawler4j是一個開源的爬蟲框架,可以快速建立一個多執行緒爬取網站的程式,而且幾分鐘之內就能完成編碼。
第一步:如果讀者使用過maven,可以很輕鬆的使用maven的pom引入即可。
<repositories>
<repository>
<id>onebeartoe</id>
<name>onebeartoe</name>
<url>https://repository-onebeartoe.forge.cloudbees.com/snapshot/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>edu.uci.ics</groupId>
<artifactId>crawler4j</artifactId>
<version>4.4-SNAPSHOT</version>
</dependency>
</dependencies>如果你沒有用過maven那麼,你需要把原始碼打成jar包,然後引入jar包,使用即可。
第二步:建立一個crawler類繼承WebCrawler ,並重寫兩個方法,如下:
public class MyCrawler2 extends WebCrawler {
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
//這個方法的作用是過濾不想訪問的url
//return false時 url被過濾掉不會被爬取
return super.shouldVisit(referringPage, url);
}
@Override
public void visit(Page page) {
//這個方法的作用是當shouldVisit方法返回true時,呼叫該方法,獲取網頁內容,已被封裝到Page物件中
super.visit(page);
}
}第三步:建立一個controller類(實際任意類都行),建立main方法,根據官方文件,只需修改執行緒數量和url就行了。該url可以被稱為種子,只要傳入一個url,crawler4j就會根據url中的內容獲取頁面中所有的url然後再次爬取,周而復始,但重複的網址不會重複爬取,不會出現死迴圈。
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "/data/crawl/root";//檔案儲存位置
int numberOfCrawlers = 7;//執行緒數量
CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(crawlStorageFolder);//配置物件設定
PageFetcher pageFetcher = new PageFetcher(config);
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);//建立
controller.addSeed("http://www.ics.uci.edu/~lopes/");//傳入的url
controller.start(MyCrawler.class, numberOfCrawlers);//開始執行爬蟲
}
}
啟動main方法就可以完成網頁的爬取了。
使用maven方式僅僅引入以上的pom檔案,會有個問題,啟動的時候總是報錯,
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/http/ssl/TrustStrategy
at com.chenyao.Controller.main(Controller.java:25)
Caused by: java.lang.ClassNotFoundException: org.apache.http.ssl.TrustStrategy
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.4.1</version>
</dependency>
下面寫一個例項,爬取京東商品資訊
1.控制器
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "/data/crawl/root";//檔案儲存位置
int numberOfCrawlers = 1;//執行緒數量
CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(crawlStorageFolder);//配置資訊設定
PageFetcher pageFetcher = new PageFetcher(config);
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);//建立爬蟲執行器
controller.addSeed("https://search.jd.com/Search?keyword=筆記本&enc=utf-8&wq=筆記本");//傳入種子 要爬取的網址
controller.start(MyCrawler2.class, numberOfCrawlers);//開始執行爬蟲
2.爬蟲類,這裡的兩個實現方法尤為重要,控制器只是一個訪問的入口,具體訪問規則和訪問結果的獲取都是在這兩個方法中實現。
檢視京東關鍵詞搜尋之後的html規則,發現商品都在<li>標籤中
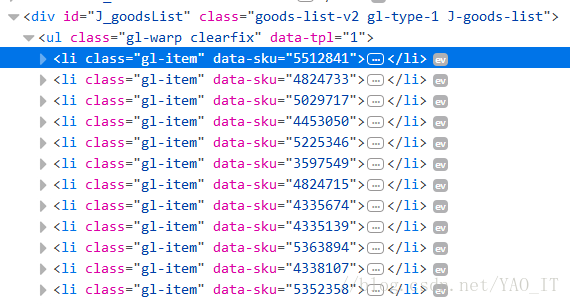
繼續展開<li>標籤,看到該商品的具體資訊,這裡筆者爬取圖片連線,其他資訊依然可以根據讀者需求自定義爬取

public class MyCrawler2 extends WebCrawler {
//自定義過濾規則
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg|png|mp3|mp4|zip|gz))$");
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();//爬取的網址 轉小寫
//這裡定義過濾的網址,我的需求是隻爬取京東搜尋出來的頁面中的商品,url需要以https://search.jd.com/search開頭
boolean b =!FILTERS.matcher(href).matches()&&href.startsWith("https://search.jd.com/search");
return b;
}
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL();
System.out.println(url);
//判斷page是否為真正的網頁
if (page.getParseData() instanceof HtmlParseData) {
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();
String html = htmlParseData.getHtml();//頁面html內容
Document doc = Jsoup.parse(html);//採用jsoup解析html,這個大家不會可以簡單搜一下
//使用選擇器的時候需要了解網頁中的html規則,自己去網頁中F12一下,
Elements elements = doc.select(".gl-item");
if(elements.size()==0){
return;
}
for (Element element : elements) {
Elements img = element.select(".err-product");
if(img!=null){
//輸出圖片連結
System.out.println(img.attr("src"));
System.out.println(img.attr("data-lazy-img"));
}
}
}
}
}看一下執行結果:

not-visiting就是被過濾的url
下面輸出的是圖片的連結
使用Crawler4j確實很方便。而且有點傻瓜式。讀者可以自己試一下爬取網頁給自己帶來的樂趣