
平衡二叉樹、B樹、B+樹、B*樹、LSM樹簡介
平衡二叉樹是基於分治思想採用二分法的策略提高資料查詢速度的二叉樹結構。非葉子結點最多隻能有兩個子結點,且左邊子結點點小於當前結點值,右邊子結點大於當前結點樹,並且為保證查詢效能增增刪結點時要保證左右兩邊結點層級相差不大於1,具體實現有AVL、Treap、紅黑樹等。Java中TreeMap就是基於紅黑樹實現的。
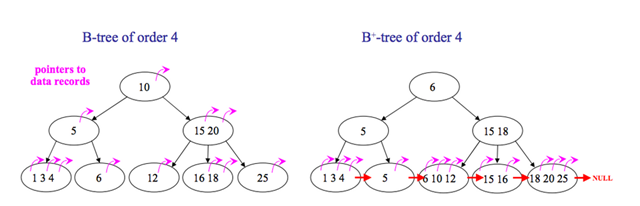
B樹與平衡二叉樹區別是它是平衡多路查詢樹,它每個節點包含的關鍵字增多了,在應用時可利用磁碟塊的原理把結點大小限制在磁碟大小範圍內從而優化讀寫速度,同時樹的關鍵字增多後層級比原理的二叉樹少量,減少了資料查詢次數和複雜度。
B+樹是B樹基礎上為了更充分的利用結點空間,讓遍歷查詢速度更穩定而擴充套件的結構,它規定只在葉子節點存資料,非葉子結點只存索引,且葉子結點用一個連結串列連線起來。
(1)B+跟B樹不同B+樹的非葉子節點不儲存關鍵字記錄的指標,這樣使得B+樹每個節點所能儲存的關鍵字大大增加;
(2)B+樹葉子節點儲存了父節點的所有關鍵字和關鍵字記錄的指標,每個葉子節點的關鍵字從小到大連結;
(3)B+樹的根節點關鍵字數量和其子節點個數相等;
(4)B+的非葉子節點只進行資料索引,不會存實際的關鍵字記錄的指標,所有資料地址必須要到葉子節點才能獲取到,所以每次資料查詢的次數都一樣;
在B樹的基礎上每個節點儲存的關鍵字數更多,樹的層級更少所以查詢資料更快,所有指關鍵字指標都存在葉子節點,所以每次查詢的次數都相同所以查詢速度更穩定;
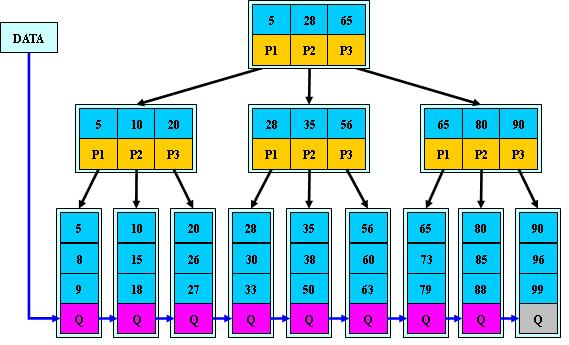
B*樹是在B+基礎上給非根非葉子結點增加指向兄弟結點的指標,因此可以向兄弟結點轉移關鍵字使其分解次數變得更少。
https://zhuanlan.zhihu.com/p/27700617
LSM樹是記憶體中完成增、刪、改操作從而寫效能更高,使用索引修改比讀更頻繁的場景。
https://blog.csdn.net/u010853261/article/details/78217823
為什麼說B+tree比B樹更適合實際應用中作業系統的檔案索引和資料庫索引?
(1) B+tree的磁碟讀寫代價更低
B+tree的內部結點並沒有指向關鍵字具體資訊的指標。因此其內部結點相對B樹更小。如果把所有同一內部結點的關鍵字存放在同一盤塊中,那麼盤塊所能容納的關鍵字數量也越多。一次性讀入記憶體中的需要查詢的關鍵字也就越多。相對來說IO讀寫次數也就降低了。舉個例子,假設磁碟中的一個盤塊容納16bytes,而一個關鍵字2bytes,一個關鍵字具體資訊指標2bytes。一棵9階B-tree(一個結點最多8個關鍵字)的內部結點需要2個盤快。而B+ 樹內部結點只需要1個盤快。當需要把內部結點讀入記憶體中的時候,B 樹就比B+ 樹多一次盤塊查詢時間(在磁碟中就是碟片旋轉的時間)。
(2)B+tree的查詢效率更加穩定
由於非葉子結點並不是最終指向檔案內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查詢必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。(3)B樹在提高了磁碟IO效能的同時並沒有解決元素遍歷的效率低下的問題。正是為了解決這個問題,B+樹應運而生。B+樹只要遍歷葉子節點就可以實現整棵樹的遍歷。而且在資料庫中基於範圍的查詢是非常頻繁的,而B樹不支援這樣的操作(或者說效率太低)。
LSM樹
目前常見的主要的三種儲存引擎是:雜湊、B+樹、LSM樹:
- 雜湊儲存引擎:是雜湊表的持久化實現,支援增、刪、改以及隨機讀取操作,但不支援順序掃描,對應的儲存系統為key-value儲存系統。對於key-value的插入以及查詢,雜湊表的複雜度都是O(1),明顯比樹的操作O(n)快,如果不需要有序的遍歷資料,雜湊表效能最好。
- B+樹儲存引擎是B+樹的持久化實現,不僅支援單條記錄的增、刪、讀、改操作,還支援順序掃描(B+樹的葉子節點之間的指標),對應的儲存系統就是關係資料庫(Mysql等)。
- LSM樹(Log-Structured MergeTree)儲存引擎和B+樹儲存引擎一樣,同樣支援增、刪、讀、改、順序掃描操作。而且通過批量儲存技術規避磁碟隨機寫入問題。當然凡事有利有弊,LSM樹和B+樹相比,LSM樹犧牲了部分讀效能,用來大幅提高寫效能。
上面三種引擎中,LSM樹儲存引擎的代表資料庫就是HBase.
LSM樹核心思想的核心就是放棄部分讀能力,換取寫入的最大化能力。LSM Tree ,這個概念就是結構化合並樹的意思,它的核心思路其實非常簡單,就是假定記憶體足夠大,因此不需要每次有資料更新就必須將資料寫入到磁碟中,而可以先將最新的資料駐留在記憶體中,等到積累到足夠多之後,再使用歸併排序的方式將記憶體內的資料合併追加到磁碟隊尾(因為所有待排序的樹都是有序的,可以通過合併排序的方式快速合併到一起)。
日誌結構的合併樹(LSM-tree)是一種基於硬碟的資料結構,與B+tree相比,能顯著地減少硬碟磁碟臂的開銷,並能在較長的時間提供對檔案的高速插入(刪除)。然而LSM-tree在某些情況下,特別是在查詢需要快速響應時效能不佳。通常LSM-tree適用於索引插入比檢索更頻繁的應用系統。
LSM樹和B+樹的差異主要在於讀效能和寫效能進行權衡。在犧牲的同時尋找其餘補救方案:
(a)LSM具有批量特性,儲存延遲。當寫讀比例很大的時候(寫比讀多),LSM樹相比於B樹有更好的效能。因為隨著insert操作,為了維護B+樹結構,節點分裂。讀磁碟的隨機讀寫概率會變大,效能會逐漸減弱。
(b)B樹的寫入過程:對B樹的寫入過程是一次原位寫入的過程,主要分為兩個部分,首先是查詢到對應的塊的位置,然後將新資料寫入到剛才查詢到的資料塊中,然後再查詢到塊所對應的磁碟物理位置,將資料寫入去。當然,在記憶體比較充足的時候,因為B樹的一部分可以被快取在記憶體中,所以查詢塊的過程有一定概率可以在記憶體內完成,不過為了表述清晰,我們就假定記憶體很小,只夠存一個B樹塊大小的資料吧。可以看到,在上面的模式中,需要兩次隨機尋道(一次查詢,一次原位寫),才能夠完成一次資料的寫入,代價還是很高的。
(c)LSM優化方式:
- Bloom filter: 就是個帶隨機概率的bitmap,可以快速的告訴你,某一個小的有序結構裡有沒有指定的那個資料的。於是就可以不用二分查詢,而只需簡單的計算幾次就能知道資料是否在某個小集合裡啦。效率得到了提升,但付出的是空間代價。
- compact:小樹合併為大樹:因為小樹效能有問題,所以要有個程序不斷地將小樹合併到大樹上,這樣大部分的老資料查詢也可以直接使用log2N的方式找到,不需要再進行(N/m)*log2n的查詢了