用機器學習對CTR預估建模(一)
阿新 • • 發佈:2019-01-22
資料集介紹:
train - Training set. 10 days of click-through data, ordered chronologically. Non-clicks and clicks
are subsampled according to different strategies.
Train.csv 解壓後有5.6G,樣本個數非常大,一般200m的csv資料(20~30維)用pandas讀取成資料幀(dataframe)格式,大概會佔用記憶體1G左右,所以這麼的資料集單機記憶體一般吃不消。
test - Test set. 1 day of ads to for testing your model predictions.
Test.csv解壓後有673m,不是很大。
sampleSubmission.csv - Sample submission file in the correct format, corresponds to the All-0.5 Benchmark.
對特徵進行篩選和down sampling來降低資料集
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 01 12:51:31 2017
@author: JR.Lu
"""
import pandas as pd
import numpy as np
train_df=pd.read_csv('train.csv',nrows=10000000 其次是用簡單的特徵來測試模型,用網格搜尋的方式來進行引數優選
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 01 20:36:46 2017
@author: JR.Lu
"""
import pandas as pd
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier,RandomForestClassifier
from sklearn.cross_validation import train_test_split
from sklearn.learning_curve import learning_curve
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
import scipy as sp
def logloss(act, pred):
'''
比賽使用logloss作為evaluation
'''
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))
ll = ll * -1.0/len(act)
return ll
# 結果衡量
def print_metrics(true_values, predicted_values):
print "logloss: ", logloss(true_values, predicted_values)
print "Accuracy: ", metrics.accuracy_score(true_values, predicted_values)
print "AUC: ", metrics.roc_auc_score(true_values, predicted_values)
print "Confusion Matrix: ", + metrics.confusion_matrix(true_values, predicted_values)
print metrics.classification_report(true_values, predicted_values)
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
'''
輸入一個模型、title、x、y,返回模型學習過程曲線
'''
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
#讀取經過down sampling後的small資料
train_df=pd.read_csv('train_small.csv',nrows=100000)
test_df=pd.read_csv('test_small.csv')
feature_columns=['device_type','C1','C15','C16','banner_pos',
'banner_pos','site_category']
train_x=train_df[feature_columns]
test_x=test_df[feature_columns]
x=pd.concat([train_x,test_x])
#變成one-hot encoding
temp=x
for each in feature_columns:
temp_dummies=pd.get_dummies(x[each])
temp=pd.concat([temp,temp_dummies],axis=1)
x_dummies=temp.drop(feature_columns,axis=1)
X_train=x_dummies[0:len(train_x)]
Y_train=train_df['click']
x_train, x_test, y_train, y_test=train_test_split(X_train,Y_train,test_size=0.33)
#建模
#模型引數選擇,使用GridSearchCV實現
"""
LR模型可調的引數,沒幾個能調的,gs調參只能輸入list,不能對str進行選擇。
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True,
intercept_scaling=1, class_weight=None, random_state=None,
solver='liblinear', max_iter=100, multi_class='ovr',
verbose=0, warm_start=False, n_jobs=1)
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}, default: ‘liblinear’
"""
#param_LR= {'C':[0.1,1,2]}
#
#
#gsearch_LR = GridSearchCV(estimator = LogisticRegression(penalty='l1',solver='liblinear'),
# param_grid=param_LR,cv=3)
#gsearch_LR.fit(x_train,y_train)
#gsearch_LR.grid_scores_, gsearch_LR.best_params_, gsearch_LR.best_score_
title='LRlearning{penalty=l1,solver=liblinear,cv=3}'
plot_learning_curve(LogisticRegression(penalty='l1',solver='liblinear',C=1),
title=title,cv=10,X=x_train,y=y_train)
#gsearch_LR.fit(x_train,y_train)
#gbdt模型
#param_GBDT= {'learning_rate':[0.1,0.5],
# 'n_estimators':[100,200,300,400],
# 'max_depth':[3,4]}
#
#gsearch_GBDT = GridSearchCV(estimator =GradientBoostingClassifier(),
# param_grid=param_GBDT,cv=10)
#gsearch_GBDT.fit(x_train,y_train)
##gsearch_GBDT.grid_scores_
#gsearch_GBDT.best_params_
#gsearch_GBDT.best_score_
#最佳引數:'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3
title='GDBTlearning{n_estimators: 200, learning_rate: 0.1, max_depth: 3}'
plot_learning_curve(estimator=GradientBoostingClassifier(n_estimators=200, learning_rate=0.1, max_depth=3),
title=title,cv=2,X=x_train,y=y_train)
#比LR好那麼一點點
#rf建模
#param_rf= {'n_estimators':[100,200,300],
# 'max_depth':[2,3,4]}
#
#gsearch_rf = GridSearchCV(estimator =RandomForestClassifier(),
# param_grid=param_rf,cv=3)
#
#gsearch_rf.fit(x_train,y_train)
##gsearch_GBDT.grid_scores_
#gsearch_rf.best_params_
#gsearch_rf.best_score_
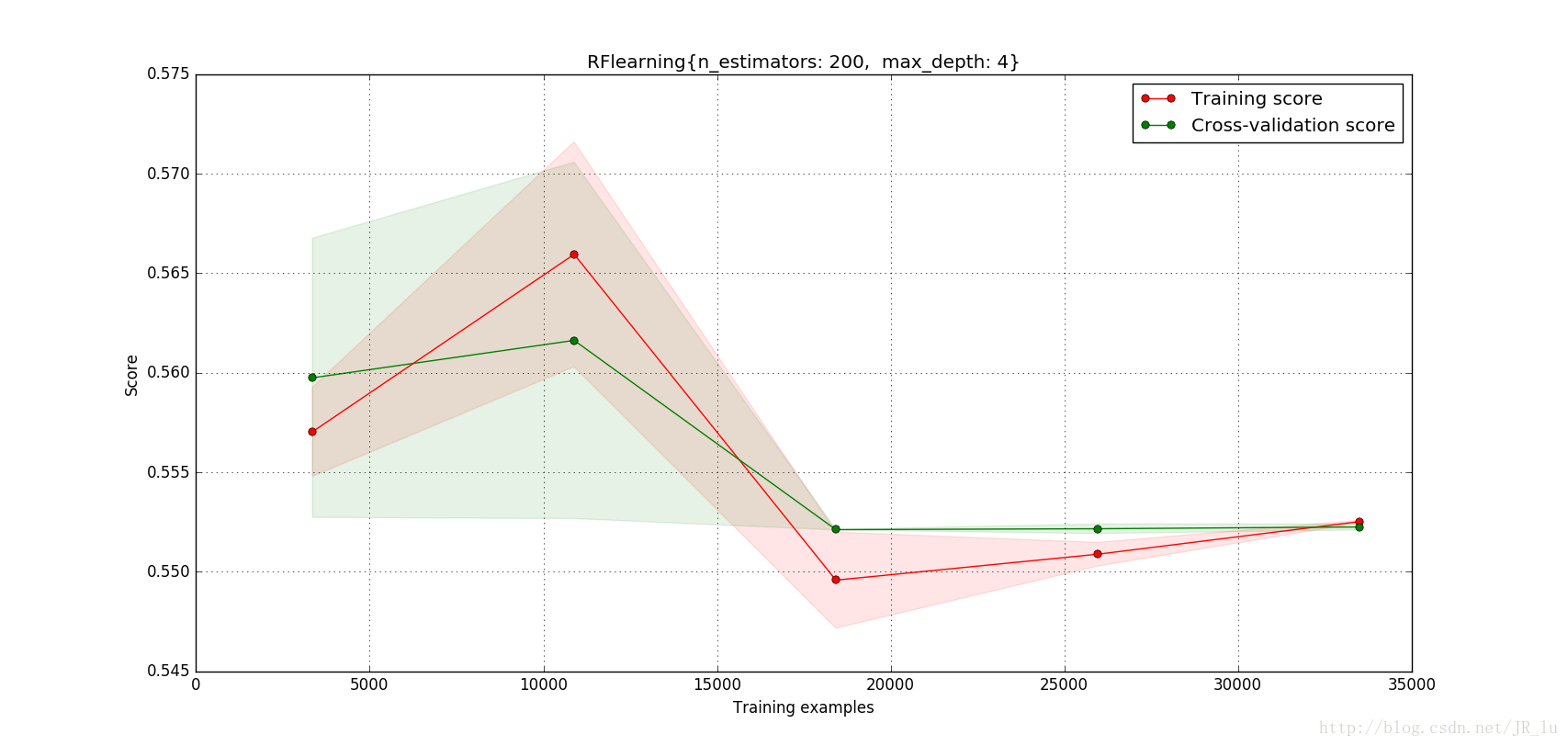
# 最佳引數: {'n_estimators': 200, 'max_depth': 4}
title='RFlearning{n_estimators: 200, max_depth: 4}'
plot_learning_curve(estimator=RandomForestClassifier(n_estimators=200, max_depth=4),
title=title,cv=2,X=x_train,y=y_train)
# predict
lr_model=LogisticRegression(penalty='l1',solver='liblinear',C=1)
gbdt_model=GradientBoostingClassifier(n_estimators=200, learning_rate=0.1, max_depth=3)
rf_model=RandomForestClassifier(n_estimators=200, max_depth=4)
lr_model.fit(x_train,y_train)
gbdt_model.fit(x_train,y_train)
rf_model.fit(x_train,y_train)
lr_predict=lr_model.predict( x_test)
gbdt_predict=gbdt_model.predict(x_test)
rf_predict=rf_model.predict(x_test)
print "LRmodel 效能如下:-------"
print_metrics(y_test, lr_predict)
print "GBDTmodel 效能如下:-------"
print_metrics(y_test, gbdt_predict)
print "RFmodel 效能如下:-------"
print_metrics(y_test, rf_predict)
結果大概如下:
LRmodel 效能如下:-------
logloss: 14.8549419892
Accuracy: 0.569909090909
AUC: 0.570339428461
Confusion Matrix: [[11141 5293]
[ 8900 7666]]
precision recall f1-score support
0 0.56 0.68 0.61 16434
1 0.59 0.46 0.52 16566
avg / total 0.57 0.57 0.56 33000GBDTmodel 效能如下:-------
logloss: 14.7952832304
Accuracy: 0.571636363636
AUC: 0.572068547036
Confusion Matrix: [[11177 5257]
[ 8879 7687]]
precision recall f1-score support
0 0.56 0.68 0.61 16434
1 0.59 0.46 0.52 16566
avg / total 0.58 0.57 0.57 33000RFmodel 效能如下:-------
logloss: 15.4713065032
Accuracy: 0.552060606061
AUC: 0.553565705536
Confusion Matrix: [[15281 1153]
[13629 2937]]
precision recall f1-score support
0 0.53 0.93 0.67 16434
1 0.72 0.18 0.28 16566
avg / total 0.62 0.55 0.48 33000插個圖看看結果: