
資訊檢索中的特徵空間變化
一、背景及概述
對於一篇文章或者是一段文字資訊,我們想要獲取其中的關鍵資訊,如果是中文,我們首先要對其進行分詞的預處理,中文分詞有很多開源的技術,如python就有結巴模組用來做中文分詞,網上有很多部落格詳細講解,這邊不是我們這部分工作的重點內容,在這裡就不詳細講解了。(關於python中結巴分詞)通過對連續的語義的分詞我們會得到由多個獨立詞語構成的資訊,這裡就需要合適的資訊檢索模型,來判斷兩個不同的文章或語句資訊之間的相似程度了,常用的資訊檢索模型分為三類,集合論模型,代數模型以及概率模型。以代數模型為例,向量空間模型是代數模型的一種,這種模型是將文件表示成空間向量,通過計算向量之間的餘弦相似度來比較兩篇文件之間的相關程度,然而這種模型建立出來的空間向量維度十分高,最簡單的向量空間模型中,加入詞典的大小為N維,那麼一篇文件的向量也是N維,M篇文章就會構成一個M*N維度的矩陣,但是在在這個矩陣中又有很多值為0的特徵,非常冗餘;因此可想而知,用如此高緯度的向量計算是多麼麻煩。在這類問題的基礎上,在資訊檢索的領域內,我們需要做一些特徵空間的變化,來簡化運算以及提高效率,並且實驗也證明,通過一定的特徵空間變化之後得到的效果要優於直接運算。
二、特徵空間變化主要方法簡介
常用的特徵空間變化有,奇異值分解SVD,隱語義分析LSA,PLSA主題模型,LDA主題模型。
簡單介紹一下,奇異值分解是線性代數中一種重要的矩陣分解
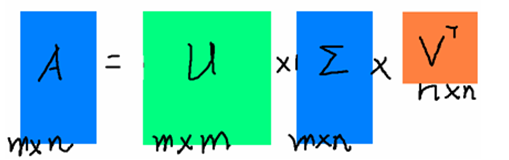
矩陣A可以理解為我們的M個資訊段構成的M*N的矩陣,對於矩陣U是一個M*M的矩陣,這個矩陣中所有的向量是正交的,Σ是一個N*M的矩陣,而且還是個對角陣,即除了對角線上的元素都為0;V'是一個N*N的矩陣,裡面的向量也都是正交的。我們可以將Σ理解成奇異值矩陣,其對角線上的每一個元素是奇異值,並且在這個矩陣中對角線上的元素是按照奇異值的大小排列的,同時,前百分之十以內的奇異值在整個運算中佔的比重幾乎是全部,因此我們可以用前r個奇異值和兩個正交矩陣的相乘結果來近似原本的矩陣
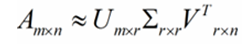
易理解,r越接近N,則相乘的結果越接近於A。由此可見,SVD可以用來作為特徵提取的方法,機器學習中的PCA主成分分析法就是用的這種方法。但是這種方法得到的特徵是各個特徵之間隱含的聯絡構成的新特徵,這樣的新特徵不具備可解釋性。
隱語義分析LDA是一種潛在語義索引方法,一種新的資訊檢索代數模型,使用統計計算的方法對大量的文字集進行分析,從而提取出詞與詞之間潛在的語義結構,並用這種潛在的語義結構,來表示詞和文字,達到消除詞之間的相關性和簡化文字向量實現降維的目的。
基本觀點是,把高維的向量空間模型(VSM)表示中的文件對映到低維的潛在語義空間中,對映是通過對文件矩陣進行奇異值分解來實現的,SVD得到Σ,只保留最大的k個奇異值得到Σ',進行奇異值分解的反運算,得到A的近似矩陣。基本步驟如下:
1、建立詞頻矩陣frequency matrix
2、計算frequency matrix的奇異值分解
3、對於每一個文件d,用排除了SVD中消除後的詞的新向量替換原有的向量
4、用轉換後的文件索引和相似度計算
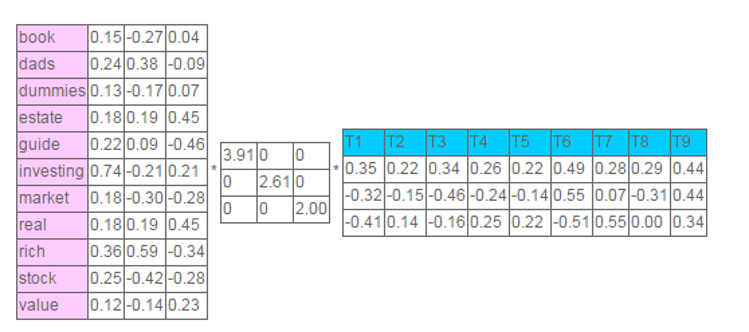
每個文件可以用三維的向量表示出來。LSA本質上識別了以文件為單位的多個單詞並歸入同一個子空間,在這個例子中,即為三維空間中相近的點(stock和market)在這一系列資料中存在著隱含的關係。
後兩種方法是對以上方法的改進,我做的專案中沒有用到,這裡就不做詳細的解釋,感興趣的讀者可以自行查詢。
三、奇異值分解的實現
參考連結:奇異值分解
# encoding=utf8
import numpy as np
from numpy import *
from numpy import linalg as la
from operator import itemgetter
def loadExData():
return [[4,4,0,2,2],
[4,0,0,3,3],
[4,0,0,1,1],
[1,1,1,2,0],
[2,2,2,0,0],
[1,1,1,0,0],
[5,5,5,0,0]]
def loadExData2():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
def ReconstructSigma(Sigma):
return np.mat([[Sigma[0],0,0],[0,Sigma[1],0],[0,0,Sigma[2]]])
def ReconstructData(U,Sigma,VT):
return U[:,:3]*Sigma*VT[:3,:]
# 計算相似性函式
def eulidSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB))#預設計算列做為一個元素之間的距離
def pearsSim(inA,inB):
if(len(inA)<3): return 1.0
return 0.5 + 0.5*np.corrcoef(inA, inB, rowvar=0)[0][1]# 這裡返回是一個矩陣,只拿第一行第二個元素
def cosSim(inA,inB):
num = float(inA.T * inB)
denom = la.norm(inA) * la.norm(inB)
return 0.5 + 0.5 * (num/denom)
'''''
standEst 需要做的就是估計user 的item 評分,
採用方法是 根據物品相似性,及每一列相似性
要估計item那一列與其他列進行相似性估計,獲得兩列都不為0的元素計算相似性
然後用相似性乘以 評分來估計未評分的數值 。
'''
def standEst(dataMat,user,simMeas,item):
n = np.shape(dataMat)[1]
simTotal = 0.0 ; ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user,j]
if(userRating == 0): continue
overLap = nonzero(logical_and(dataMat[:,item].A > 0,dataMat[:,j].A >0))[0]# 返回元素不為0的下標
'''''
nonzero 返回參考下面例子,返回二維陣列,第一維是列方向,第二位是行方向
'''
if(len(overLap)) == 0 :similarity = 0
else:
similarity = simMeas(dataMat[overLap,item],dataMat[overLap,j])
print 'the %d and %d similarity is : %f' %(item,j,similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else : return ratSimTotal/simTotal
def recommend(dataMat,user ,N = 3,simMeas= cosSim,estMethod = standEst):
unratedItems = nonzero(dataMat[user,:].A == 0)[1]# .A 使得矩陣型別轉為array
'''''
>>> a = np.array([[1,2,3],[4,5,6],[7,8,9]])
>>> a > 3
array([[False, False, False],
[ True, True, True],
[ True, True, True]], dtype=bool)
>>> np.nonzero(a > 3)
(array([1, 1, 1, 2, 2, 2]), array([0, 1, 2, 0, 1, 2]))
'''
if len(unratedItems) == 0: return 'you rated everything'
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(dataMat,user,simMeas,item)
itemScores.append((item,estimatedScore))
return sorted(itemScores,key=itemgetter(1),reverse = True)[:N]
def svdEst(dataMat , user, simMeas,item):
n = shape(dataMat)[1]
simTotal = 0.0 ; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4) * Sigma[:4]) # 保留最大三個奇異值
xformedItems = dataMat.T * U[:,:4] * Sig4.I
print xformedItems
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
if __name__=="__main__":
'''''
# 測試中間資料
Data = loadExData()
MatData = np.mat(Data)
U,Sigma,VT = np.linalg.svd(Data)
print Sigma
Sigma = ReconstructSigma(Sigma)
print Sigma
print ReconstructData(U, Sigma, VT)
print eulidSim(MatData[:,0], MatData[:,4])
print cosSim(MatData[:,0], MatData[:,4])
print pearsSim(MatData[:,0], MatData[:,0])
'''
Data = loadExData()
dataMat = np.mat(Data)
dataMat2 = mat(loadExData2())
print dataMat2
print recommend(dataMat2, 1,estMethod=svdEst)